Can You Really Backdoor Federated Learning
Can You Really Backdoor Federated Learning
**作者:**Ananda Theertha Suresh Brendan McMahan Peter Kairouz Ziteng Sun
**会议:**NeruIPS
**发表时间:**2019.12
背景:
联邦学习的分布式特征,特别是在使用安全聚合协议增强时,使得检测和防御后门攻击成为一项具有挑战性的任务。
而当前针对后门攻击的防御方法,要么需要仔细的检查训练数据,要么需要完全控制服务器上的训练过程,这在联邦学习的背景下很难实现。
本文证实了两种防御措施 更新范数边界和弱差分隐私,可以较为有效的防御联邦学习中的后门攻击,并通过多种对比实验,说明了攻击者的数量、后门任务的数量对攻击效果的影响。
方案:
**模型更新毒化攻击 Model Update Poisoning Attacks,**与《How to Backdoor Federated Learning》中提出的攻击方式类似。
全局模型更新方式:

攻击方案:
假设在第t轮只选择了用户1作为攻击者,攻击者通过发送下式达到攻击效果。
用w*作为我们的后门模型,根据w*倒推出∆w_t^1:

此时新获得的t+1轮全局模型为:

且当假设模型已经充分收敛时,k > 1的其他用户更新很小,那么模型的参数将被更新在w^*的一个小邻域内。

**3.攻击方式**
**无约束的增强后门攻击 Unconstrained boosted backdoor attack:**
如何获得一个后门模型w^*:
为了获得后门模型w^,我们假设攻击者拥有一组描述后门任务的集合D_mal和一组由真实分布得到的训练样本D_trn。
用参数集w_t作为初始化,用D_trn∪D_mal训练一个模型w^。这种攻击对模型的更新通常会更大,也更容易被检测到,作为一个基线任务。
**规范有界后门攻击 Norm bounded backdoor attack:**
将无约束的增强后门攻击Unconstrained boosted backdoor attack进行规范裁剪:在每一轮中,模型在后门任务训练得到的模型更新都要小于M⁄β。因此模型更新在经过β的提升后,其规范由M约束。
4.防御措施:
Norm thresholding of updates 更新的规范阈值
由于提升攻击可能会产生比较大的更新,可以通过裁掉那些高于阈值M的更新参数使服务器忽略那些超过阈值M的更新。
攻击者的应对:
如果我们假设攻击者知道阈值M,因此攻击者总是可以在这个量级内返回恶意更新:

(Weak) differential privacy (弱)差分隐私
添加少量噪音,传统上为了获得合理的差分隐私而添加的噪声量是比较大的。因为我们的目标不是隐私,而是防止攻击,所以我们添加了少量的噪音,足以限制攻击的成功。
实验评估:
**数据集:**EMINIST数据集——3383个用户,每个用户大约有100张数字图像,
**后门任务:**将目标用户的“7”分类为“1” 。
**随机采样 vs 固定频率攻击。Random sampling vs. fixed frequency attacks.
**被损坏用户的比例。Fraction of corrupted users.****
ϵ表示攻击者的比例,每轮选取C·K=30个用户,进行模型更新:
固定频率攻击:攻击频率设置为与攻击者总数量成反比f=1/(ϵ·C·K),
攻击频率为1和1 / 10,每轮攻击一次和每10轮攻击一次。
随机取样攻击:每一轮的攻击者的数量为(0,min(ϵ·K,C·K)),
3383个用户里有113个被毒害的用户,每轮进行重新抽取。

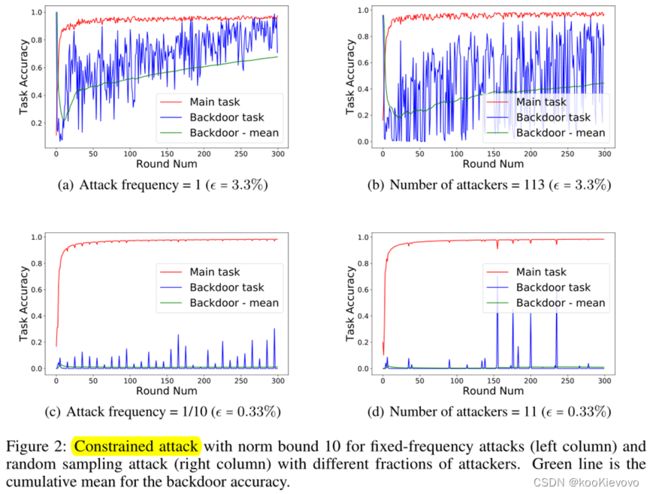
固定频率攻击比随机抽样攻击更有效,此外,在固定频率攻击中,更容易看到攻击是否发生在特定的一轮。
后门任务的数量。Number of backdoor tasks.
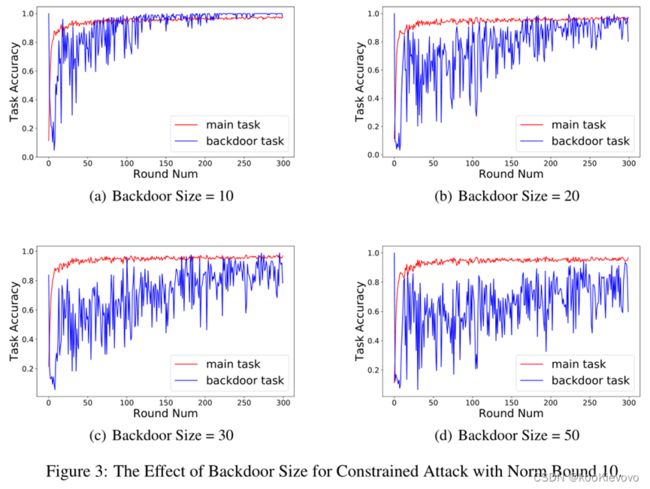
拥有的后门任务越多,就越难达到在不影响主要任务的条件下,实现对目标的攻击。
更新的范数界限。Norm bound for the update.
**限制更新在某个范围内,**当选择3作为范数边界将成功地减轻攻击,而对主要任务的性能几乎没有影响。

Norm bounding可以作为当前后门攻击的有效防御。
弱差分隐私。Weak differential privacy
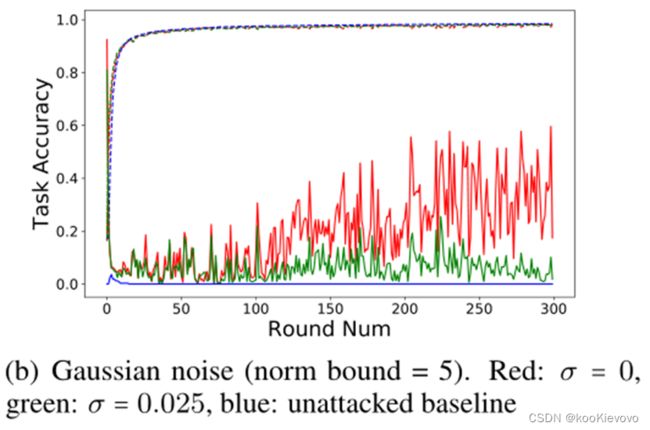
考虑在范数边界方法的基础上添加高斯噪声,添加高斯噪声也可以帮助减轻那些逃避了范数裁剪的后门攻击,而且不会对主要任务的准确率造成太大的影响。
总结:
证实了在没有防御的情况下。攻击的成功率依赖于攻击者的数量,换句话说需要大量的攻击者存在。范数约束极大的限制了后门攻击的成功率。
证实了后门任务的数量对后门任务的影响,呈负相关趋势。
提出了两种防御措施Norm bound for the update和weak differential privacy可以较为有效的防御在联邦学习中的后门攻击。
(模型:TensorFlow联邦框架中的联邦学习来训练一个五层卷积神经网络,两个卷积层、一个最大池化层和两个dense层。)