三维视觉和三维点云基础概念
本篇文章为学习笔记(知识点整理),内容非原创, 部分内容转载自以下博客链接。(链接不太全)
三维视觉研究什么_惊鸿一博-CSDN博客_三维视觉
北大陈宝权教授:三维视觉前沿进展与应用 - 知乎
3D目标检测与视觉SLAM的区别与联系是什么?研一新生目前还在这两个方向上犹豫,前辈们能否提供点建议? - 知乎
什么是三维点云,一起来认识下?_空间
三维点云处理(深度学习方法)综述_jcsm__的博客-CSDN博客_三维点云
(一)三维视觉
1、三维视觉作为一个学科来讲,是多学科的交叉融合。主要有计算机视觉、计算机图形学,还有人工智能。
2、研究内容
(1)三维感知技术。结合多方面的技术,研究新的三维感知模型,新的成像理论方法,实现低成本、大场景、高精度的三维数据获取。单目、双目、结构光深度估计。超大场景的三维获取。
(2)位姿估计技术。涉及到特征、定位和定姿态。相机的位置,观察目标的位置,以及相机对应的姿态。前期采用的是特征提取、特征分析、配对等等,来进行定位定姿。这个技术在AR、VR方向应用很大。
(3)三维建模技术。得到的三维深度数据,并不是三维完整的表述,所以需要三维建模技术,即从离散、海量的数据中建立一个统一、完整的模型。当然三维建模根据场景的大小,物品的纹理,扫描的有序无序,方法都是不同的。所有这些场景,都需要不同的三维建模技术。需要注意的是,一般说的三维建模是指几何建模。
(4)三维理解技术。在整个三维视觉里面,需要理解这个场景,不管是在建模之后还是建模过程中。理解也有很多新的方法,尤其随着现在数据的获取越来越相对容易,数据量越来越大,或者积累的建模数据越来越多。在这样的情况下,可以采用数据驱动的方式,进行三维的理解。这方面有很多的挑战,因为一般来说三维理解针对三维点云数据,点云数据区别于传统的基于图像的理解,它的数据结构上有非结构性等等,理解的东西也比图像理解得多。图像理解大多是分类,物体的识别,但是三维理解有空间的概念、控制的理解等等。
(二)三维点云
1、定义:在同一空间参考系下表达目标空间分布和目标表面光谱性的海量点集合,是由物体模型表面上一系列空间采样点构成的模型几何描述,也是三维激光扫描数据的通用表现形式。
2、点云数据格式
Pi=(x,y,z); Pi=(x,y,z,R,G,B,.…) 表示空间的一个点。
Point Cloud={P1,P2,P3,P4,.…}表示空间中的多个点。
包含:三维坐标;强度;回波信息;类别信息;RGB色彩;GPS时间;扫描角度;扫描方向
3、三维点云处理的层次
与图像处理类似,点云处理也存在不同层次的处理方式。或者说,根据任务的需求,需要组合不同的处理方式,而这些处理在过程上有先后之分。Marr将图像处理分为三个层次,低层次包括图像强化,滤波,边缘检测等基本操作。中层次包括连通域标记(label),图像分割等操作。高层次包括物体识别,场景分析等操作。
PCL官网对点云处理方法给出了较为明晰的层次划分,如图所示。
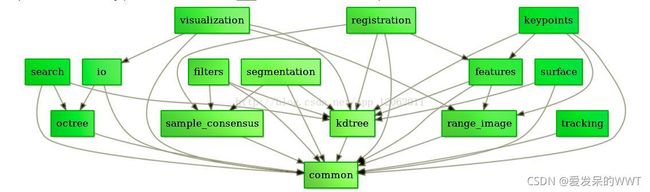
此处的common指的是点云数据的类型,包括XYZ,XYZC,XYZN,XYZG等很多类型点云,归根结底,最重要的信息还是包含在point
4、三维点云处理的卷积处理的挑战和方法
3D数据通常可以用不同的格式表示,包括深度图像、点云、网格和体积网格。点云表示是一种常用的格式,在三维空间中保留了原始的几何信息,不进行离散化。因此,它是许多场景理解相关应用如自动驾驶和机器人的首选表示。最近,深度学习技术已经主导了许多研究领域,如计算机视觉、语音识别和自然语言处理。然而,三维点云的深度学习仍然面临着数据集规模小、三维点云的高维性和非结构化等重大挑战。
点云的深度学习越来越受到人们的关注,尤其是在过去的五年里。一些公开的数据集也被发布,如ModelNet、ScanObjectNN、ShapeNet、PartNet、S3DIS、ScanNet、Semantic3D、ApolloCar3D和KITTI Vision基准套件。这些数据集进一步推动了研究深度学习的3d点云,也有越来越多的方法被提出解决各种问题点云处理,包括三维形状分类,三维对象检测和跟踪、三维点云分割、三维点云注册、6自由度姿态估计和三维重建。
1.挑战
(1)点云具有稀疏性
不同于图像,三维点云在表示物体时,只有物体表面有点云数据,如果是在实际的场景下,往往只有面向雷达的一面才会有数据产生。而且限于雷达的工作原理,远处物体的点云数据更加稀疏。因而,在点云上直接进行三维卷积需要很大的计算量,而其中很大一部分资源都是在处理空数据。
(2)点云具有无序性
三维空间中的点云不会像图像那样,规规矩矩的在一个个的像素点排好队,点云并没有顺序,这给处理上带来极大的困难。一个物体如果使用N个点云表示,那么它的排列方式具有N!种,但是表示的却是同一个物体,这是不可想象的处理难度。因而,点云的处理需要实现置换不变性。
(3)点云具有几何变换问题
一个物体在图像上的显示并不会随着物体位置的改变而发生大的变化。但是点云反应的却是实实在在的位置坐标信息,不同位置处的同一物体所表现出的数据特征是很大不同的。
2.常用方法
(1)多视角+2D卷积
这是较早使用的方法,将三维点云数据,通过多个视角的投影,转换成2D,进而转到图像方法上进行处理。该方法避开了处理三维点云数据,但是多视角投影的方法增加了计算量、损失了点云的三维空间信息。
(2)体素化+3D卷积(voxel_base)
voxel_base的方法就是先将原始点云进行体素化处理,将无序的点云转为有序,并进而使用3D卷积进行处理。而且为了解决点云稀疏性带来的卷积计算量大问题,也提出了稀疏卷积的方法,舍弃那些空白体素,加快执行速度。VoxelNet
(3)原始点云+MLP(point_base)
point_base是除了voxel_base之外另外一种优雅的处理方式,最开始是在2017年的CVPR论文PointNet提出。point_base不经过体素化过程,直接对原始数据进行处理,通过多层的mlp进行点云特征的描述,经过max pooling保证了点云的置换不变性。处理的方式很简单,效果确实很不错,并且已经成为三维点云处理中的一个重要理论和思想基础。PointNet