cento7 spark3 安装 anaconda安装
一、Spark部署安装
1. Spark Local 模式搭建文档
在本地使用单机多线程模拟Spark集群中的各个角色
1.1 安装包下载
目前Spark最新稳定版本:课程中使用目前Spark最新稳定版本:3.1.x系列
https://spark.apache.org/docs/3.1.2/index.html
注意1:
Spark3.0+基于Scala2.12
http://spark.apache.org/downloads.html

注意2:
目前企业中使用较多的Spark版本还是Spark2.x,如Spark2.2.0、Spark2.4.5都使用较多,但未来Spark3.X肯定是主流,毕竟官方高版本是对低版本的兼容以及提升
http://spark.apache.org/releases/spark-release-3-0-0.html

1.2 将安装包上传并解压
说明: 只需要上传至node1即可, 以下操作都是在node1执行的
cd /export/software
上传
解压:
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /export/server/
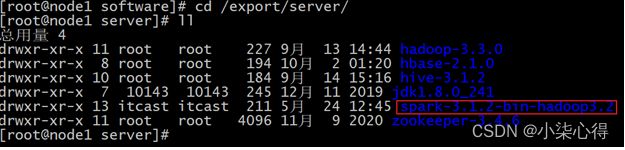
更名: (两种方式二选一即可, 推荐软连接方案)
直接重命名:
mv spark-3.1.2-bin-hadoop3.2 spark
软连接方案:
ln -s spark-3.1.2-bin-hadoop3.2 spark
目录结构说明:
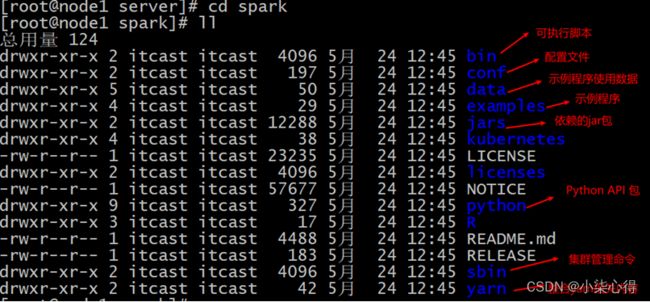
1.3 测试
Spark的local模式, 开箱即用, 直接启动bin目录下的spark-shell脚本
cd /export/server/spark/bin
./spark-shell
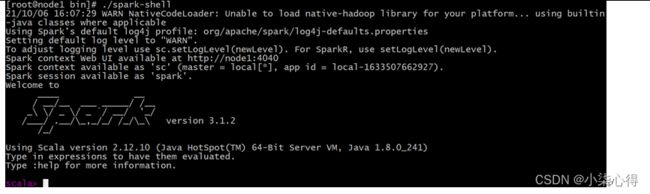
说明:
sc:SparkContext实例对象:
spark:SparkSession实例对象
4040:Web监控页面端口号
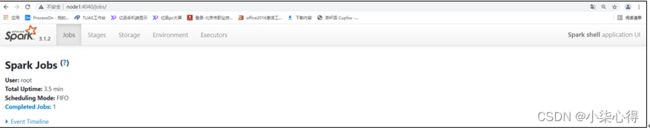
- Spark-shell说明:
1.直接使用./spark-shell
表示使用local 模式启动,在本机启动一个SparkSubmit进程
2.还可指定参数 --master,如:
spark-shell --master local[N] 表示在本地模拟N个线程来运行当前任务
spark-shell --master local[] 表示使用当前机器上所有可用的资源
3.不携带参数默认就是
spark-shell --master local[]
4.后续还可以使用–master指定集群地址,表示把任务提交到集群上运行,如
./spark-shell --master spark://node01:7077,node02:7077
5.退出spark-shell
使用 :quit
2. PySpark环境安装
这里简单说明一下:
PySpark: 是Python的库, 由Spark官方提供. 专供Python语言使用. 类似Pandas一样,是一个库
Spark: 是一个独立的框架, 包含PySpark的全部功能, 除此之外, Spark框架还包含了对R语言\ Java语言\ Scala语言的支持. 功能更全. 可以认为是通用Spark。
2.1 下载Anaconda环境包
安装版本:https://www.anaconda.com/distribution/#download-section
Python3.8.8版本:Anaconda3-2021.05-Linux-x86_64.sh
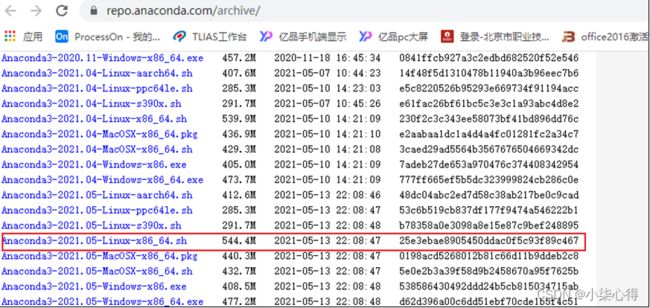
2.2 安装Anaconda环境
此环境三台节点都是需要安装的, 以下演示在node1安装, 其余两台也是需要安装的
cd /export/software
上传Anaconda脚本环境
执行脚本:
bash Anaconda3-2021.05-Linux-x86_64.sh

不断输入空格, 直至出现以下解压, 然后输入yes

此时, anaconda需要下载相关的依赖包, 时间比较长, 耐心等待即可…
配置anaconda的环境变量:
vim /etc/profile
增加如下配置
export ANACONDA_HOME=/root/anaconda3/bin
export PATH=$PATH:$ANACONDA_HOME/bin
重新加载环境变量:
source /etc/profile
修改bashrc文件
sudo vim ~/.bashrc
添加如下内容: 直接在第二行空行添加即可
export PATH=~/anaconda3/bin:$PATH
2.3 启动anaconda并测试
注意: 请将当前连接node1的节点窗口关闭,然后重新打开,否则无法识别
输入 python -V启动:

base: 是anaconda的默认的初始环境, 后续我们还可以构建更多的虚拟环境, 用于隔离各个Python环境操作, 如果不想看到base的字样, 也可以选择直接退出即可
执行:
conda deactivate

但是当大家重新访问的时候, 会发现又重新进入了base,如何让其默认不进去呢, 可以选择修改.bashrc这个文件
vim ~/.bashrc
在文件的末尾添加:
conda deactivate
保存退出后, 重新打开会话窗口, 发现就不会在直接进入base了
2.4 Anaconda相关组件介绍[了解]
Anaconda(水蟒):是一个科学计算软件发行版,集成了大量常用扩展包的环境,包含了 conda、Python 等 180 多个科学计算包及其依赖项,并且支持所有操作系统平台。下载地址:https://www.continuum.io/downloads
- 安装包:pip install xxx,conda install xxx
- 卸载包:pip uninstall xxx,conda uninstall xxx
- 升级包:pip install upgrade xxx,conda update xxx
Jupyter Notebook:启动命令
jupyter notebook
功能如下:
- Anaconda自带,无需单独安装
- 实时查看运行过程
- 基本的web编辑器(本地)
- ipynb 文件分享
- 可交互式
- 记录历史运行结果
修改jupyter显示的文件路径:
通过jupyter notebook --generate-config命令创建配置文件,之后在进入用户文件夹下面查看.jupyter隐藏文件夹,修改其中文件jupyter_notebook_config.py的202行为计算机本地存在的路径。
Spyder:
下面就Anaconda中的conda命令做详细介绍和配置。
(1)conda命令及pip命令
conda管理数据科学环境,conda和pip类似均为安装、卸载或管理Python第三方包。
conda install 包名 pip install 包名
conda uninstall 包名 pip uninstall 包名
conda install -U 包名 pip install -U 包名
(2) Anaconda设置为国内下载镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
(3)conda创建虚拟环境
conda env list
conda create py_env python=3.8.8 #创建python3.8.8环境
activate py_env #激活环境
deactivate py_env #退出环境
2.5 PySpark安装
三个节点也是都需要安装pySpark的
2.5.1 方式1:直接安装PySpark
安装如下:
使用PyPI安装PySpark如下:也可以指定版本安装
pip install pyspark
或者指定清华镜像(对于网络较差的情况):
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark # 指定清华镜像源
如果要为特定组件安装额外的依赖项,可以按如下方式安装(此步骤暂不执行,后面Sparksql部分会执行):
pip install pyspark[sql]
截图如下:

2.5.2 创建Conda环境安装PySpark
从终端创建新的虚拟环境,如下所示
conda create -n pyspark_env python=3.8
创建虚拟环境后,它应该在 Conda 环境列表下可见,可以使用以下命令查看
conda env list

2.6 初体验-PySpark shell方式
前面的Spark Shell实际上使用的是Scala交互式Shell,实际上 Spark 也提供了一个用 Python 交互式Shell,即Pyspark。

bin/pyspark --master local[*]

3. Spark on YARN 环境搭建
3.1 修改spark-env.sh
cd /export/server/spark/conf
vim /export/server/spark/conf/spark-env.sh
添加以下内容:
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
同步到其他两台
cd /export/server/spark/conf
scp -r spark-env.sh node2:$PWD
scp -r spark-env.sh node3:$PWD
3.2 修改hadoop的yarn-site.xml
node1修改
cd /export/server/hadoop/etc/hadoop/
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
添加以下内容:
<!-- 配置yarn主节点的位置 -->
yarn.resourcemanager.hostname</name>
node1.itcast.cn</value>
</property>
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
<!-- 设置yarn集群的内存分配方案 -->
yarn.nodemanager.resource.memory-mb</name>
20480</value>
</property>
yarn.scheduler.minimum-allocation-mb</name>
2048</value>
</property>
yarn.nodemanager.vmem-pmem-ratio</name>
2.1</value>
</property>
<!-- 开启日志聚合功能 -->
yarn.log-aggregation-enable</name>
true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
yarn.log-aggregation.retain-seconds</name>
604800</value>
</property>
<!-- 设置yarn历史服务器地址 -->
yarn.log.server.url</name>
http://node1.itcast.cn:19888/jobhistory/logs</value>
</property>
<!-- 关闭yarn内存检查 -->
yarn.nodemanager.pmem-check-enabled</name>
false</value>
</property>
yarn.nodemanager.vmem-check-enabled</name>
false</value>
</property>
</configuration>
将其同步到其他两台
cd /export/server/hadoop/etc/hadoop
scp -r yarn-site.xml node2:$PWD
scp -r yarn-site.xml node3:$PWD
3.3 Spark设置历史服务地址
cd /export/server/spark/conf
vim spark-defaults.conf
添加以下内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:9820/sparklog/
spark.eventLog.compress true
spark.yarn.historyServer.address node1.itcast.cn:18080
设置日志级别:
cd /export/server/spark/conf
vim log4j.properties
修改以下内容:

同步到其他节点
cd /export/server/spark/conf
scp -r spark-defaults.conf log4j.properties node2:$PWD
scp -r spark-defaults.conf log4j.properties node3:$PWD
3.4 配置依赖spark jar包
当Spark Application应用提交运行在YARN上时,默认情况下,每次提交应用都需要将依赖Spark相关jar包上传到YARN 集群中,为了节省提交时间和存储空间,将Spark相关jar包上传到HDFS目录中,设置属性告知Spark Application应用。
hadoop fs -mkdir -p /spark/jars/
hadoop fs -put /export/server/spark/jars/* /spark/jars/
修改spark-defaults.conf
cd /export/server/spark/conf
vim spark-defaults.conf
添加以下内容:
spark.yarn.jars hdfs://node1.itcast.cn:8020/spark/jars/*
同步到其他节点
cd /export/server/spark/conf
scp -r spark-defaults.conf root@node2:$PWD
scp -r spark-defaults.conf root@node3:$PWD
3.5 启动服务
Spark Application运行在YARN上时,上述配置完成
启动服务:HDFS、YARN、MRHistoryServer和Spark HistoryServer,命令如下:
## 启动HDFS和YARN服务,在node1执行命令
start-dfs.sh
start-yarn.sh
或
start-all.sh
注意:在onyarn模式下不需要启动start-all.sh(jps查看一下看不到worker和master)
## 启动MRHistoryServer服务,在node1执行命令
mapred --daemon start historyserver
## 启动Spark HistoryServer服务,,在node1执行命令
/export/server/spark/sbin/start-history-server.sh
- Spark HistoryServer服务WEB UI页面地址:
- http://node1:18080/
3.6 提交测试
先将圆周率PI程序提交运行在YARN上,命令如下:
/export/server/spark/bin/spark-submit \
--master yarn \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
/export/server/spark/examples/src/main/python/pi.py \
10
运行完成在YARN 监控页面截图如下:

设置资源信息,提交运行pi程序至YARN上,命令如下:
/export/server/spark/bin/spark-submit \
--master yarn \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--conf "spark.pyspark.driver.python=/root/anaconda3/bin/python3" \
--conf "spark.pyspark.python=/root/anaconda3/bin/python3" \
/export/server/spark/examples/src/main/python/pi.py \
10
当pi应用运行YARN上完成以后,从8080 WEB 页面点击应用历史服务连接,查看应用运行状态信息。

4. SparkSQL与Hive整合
4.1SparkSQL整合Hive步骤
4.1.1 第一步:将hive-site.xml拷贝到spark安装路径conf目录
node1执行以下命令来拷贝hive-site.xml到所有的spark安装服务器上面去
cd /export/server/hive/conf
cp hive-site.xml /export/server/spark/conf/
scp hive-site.xml root@node2:/export/server/spark/conf/
scp hive-site.xml root@node3:/export/server/spark/conf/
4.1.2 第二步:将mysql的连接驱动包拷贝到spark的jars目录下
node1执行以下命令将连接驱动包拷贝到spark的jars目录下,三台机器都要进行拷贝
cd /export/server/hive/lib
cp mysql-connector-java-5.1.32.jar /export/server/spark/jars/
scp mysql-connector-java-5.1.32.jar root@node2:/export/server/spark/jars/
scp mysql-connector-java-5.1.32.jar root@node3:/export/server/spark/jars/
4.1.3 第三步:Hive开启MetaStore服务
(1)修改 hive/conf/hive-site.xml新增如下配置
远程模式部署metastore 服务地址
"1.0"?>
type="text/xsl" href="configuration.xsl"?>
hive.metastore.uris</name>
thrift://node1.itcast.cn:9083</value>
</property>
</configuration>
2: 后台启动 Hive MetaStore服务
前台启动:
bin/hive --service metastore
后台启动:
nohup /export/server/hive/bin/hive --service metastore 2>&1 >> /var/log.log &
完整的hive-site.xml文件
<!-- 存储元数据mysql相关配置 -->
javax.jdo.option.ConnectionURL</name>
jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&;useSSL=false&;useUnicode=true&;characterEncoding=UTF-8</value>
</property>
javax.jdo.option.ConnectionDriverName</name>
com.mysql.jdbc.Driver</value>
</property>
javax.jdo.option.ConnectionUserName</name>
root</value>
</property>
javax.jdo.option.ConnectionPassword</name>
123456</value>
</property>
<!-- H2S运行绑定host -->
hive.server2.thrift.bind.host</name>
node1</value>
</property>
<!-- 远程模式部署metastore 服务地址 -->
hive.metastore.uris</name>
thrift://node1:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
hive.metastore.event.db.notification.api.auth</name>
false</value>
</property>
<!-- 关闭元数据存储版本的验证 -->
hive.metastore.schema.verification</name>
false</value>
</property>
</configuration>
4.1.4 第四步:测试Sparksql整合Hive是否成功
- [方式1]Spark-sql方式测试
先启动hadoop集群,在启动spark集群,确保启动成功之后node1执行命令,指明master地址、每一个executor的内存大小、一共所需要的核数、mysql数据库连接驱动:
cd /export/server/spark
bin/spark-sql --master local[2] --executor-memory 512m --total-executor-cores 1
或
bin/spark-sql --master spark://node1.itcast.cn:7077 --executor-memory 512m --total-executor-cores 1
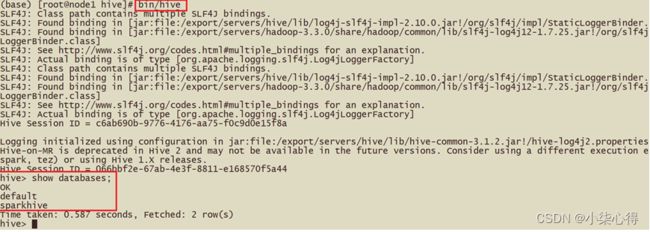
执行成功后的界面:进入到spark-sql 客户端命令行界面
查看当前有哪些数据库, 并创建数据库
show databases;
create database sparkhive;
看到数据的结果,说明sparksql整合hive成功!

注意:日志太多,我们可以修改spark的日志输出级别(conf/log4j.properties)
注意:
在spark2.0版本后由于出现了sparkSession,在初始化sqlContext的时候,会设置默认的spark.sql.warehouse.dir=spark-warehouse,
此时将hive与sparksql整合完成之后,在通过spark-sql脚本启动的时候,还是会在那里启动spark-sql脚本,就会在当前目录下创建一个spark.sql.warehouse.dir为spark-warehouse的目录,存放由spark-sql创建数据库和创建表的数据信息,与之前hive的数据息不是放在同一个路径下(可以互相访问)。但是此时spark-sql中表的数据在本地,不利于操作,也不安全。
所有在启动的时候需要加上这样一个参数:
–conf spark.sql.warehouse.dir=hdfs://node1:9820/user/hive/warehouse
保证spark-sql启动时不在产生新的存放数据的目录,sparksql与hive最终使用的是hive同一存放数据的目录。如果使用的是spark2.0之前的版本,由于没有sparkSession,不会出现spark.sql.warehouse.dir配置项,不会出现上述问题。
Spark2之后最后的执行脚本,node1执行以下命令重新进去spark-sql
cd /export/server/spark
bin/spark-sql \
--master spark://node1:7077 \
--executor-memory 512m --total-executor-cores 1 \
--conf spark.sql.warehouse.dir=hdfs://node1:9820/user/hive/warehouse
Spark-Shell方式启动:
bin/spark-shell --master local[3]
spark.sql("show databases").show
如下图:

PySpark-Shell方式启动:
bin/pyspark --master local[2]
spark.sql("show databases").show
