异质网络模型HetGNN论文总结理解
论文题目:Heterogeneous Graph Neural Network
论文来源:KDD 2019
论文链接:https://www3.nd.edu/~dial/publications/zhang_2019_heterogeneous.pdf
代码链接:https://github.com/chuxuzhang/KDD2019_HetGNN
1.摘要部分:
HetGNN同时考虑到节点异质的内容信息(节点的不同属性信息的融合),以及图中异质的结构信息。
两个模块:第一部分,通过编码异质内容深度特征的交互,得到每个节点的content embedding。(或者叫attribute embedding)
第二部分,聚合不同的邻居节点,使用了注意力机制考虑不同类型邻居的不同影响
模型适合多种应用,节点分类、聚类、链接预测、推荐等任务。
思考:比起其他异质网络模型的优势(之前看过HGAT、HAN、GTN等):
个人理解:首先HAN、GTN这些需要结合Metapath的思想,需要提前定义元路径,这对负责的网络是不容易选择的,像HGAT这种模型(结合注意力机制的),在短文本分类和假新闻检测中都有使用,但是短文本分类的那篇是先求了类型节点的权重(type attention),再根据类型聚合节点(node attention)信息的权重;而另一篇是先求同类型节点的聚合(nodetype attention),然后把不同类型的节点信息聚合(schema attention),两个相反的过程。
相比之下,HetGNN的优势:(1)不用手动选择元路径;(2)不止能够结合1阶邻居的节点进行判断,可以结合更高阶邻居的节点信息,(不会削弱更远邻居的影响)
2.引言部分

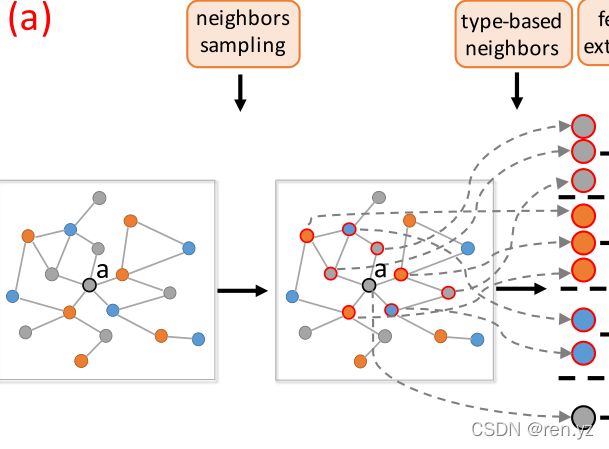
模型框架总体概述:
a.异质网络的例子(学术网络和review网络)
b.三个过程,C1,采样邻居节点,对a来说,type1的采样节点为b和c;type2采样节点为g和f;type3采样的节点为e和d
C2,节点的attribute融合,得到节点的content embedding。
C3,不同类别邻居聚合(也包括了同类型邻居的聚合)
问题:b和c的节点是如何聚合的???(也放到了在C3的过程中)
GNN方法
GNN使用深层神经网络,强有力地聚合了邻居节点的特征信息。
而且,GNN天然可以进行归纳式学习(inductive learning),可为训练过程中未出现过的节点生成嵌入表示。例如GCN、GraphSAGE、GAT。
HetGNN的三个挑战:
其实就是上述的三个过程换成了三个挑战:(直接把解决方案写下面了)
1.为每个节点构造邻居节点,大多数只考虑了一届的邻居,但是不相连的节点比如a和v仍然有作用;同时不同类型的邻居节点数目也不同,例如a有5个直接相连得邻居,c只有2个;
解决:首先设计了一个带重启的随机游走策略,为HetG中的每个节点采样固定数量的强关联的异质邻居
2.不同节点的content embedding,如何从异构内容(文本、图像等)获得节点的表示。
解决:用了RNN编码节点异质内容信息间深度的特征交互信息,得到每个节点的内容(content)嵌入。
3.不同类型的邻居节点对目标节点的贡献度不同。比如针对author节点,paper节点比起venue相对更重要。
解决:使用另一个RNN,聚合不同类别的邻居节点的嵌入,并且运用了注意力机制,为不同类型的异质邻居节点分配不同的注意力,得到最终的节点嵌入。
3.问题定义

4.模型介绍
模型总框架由四部分组成,就是前面介绍的C1,C2,C3三个过程加上定义目标函数并设计模型训练过程

以下对四个过程详细描述:
一、C1采样邻居节点
本文采用一种random walk with restart(RWR)方法进行采样,主要有两步:
- 从节点v随机游走采样,采样固定长度,每次以概率p访问邻居节点或返回初始节点,每种类型节点采样数固定,确保每类节点都会被采样到。
- 对不同类型的邻居分组,不同类型的邻居,根据采样频率返回前k个
上述采样方法中:
- 对于每种类型的节点都采样到了
- 每种类型节点数量相同,并且高频邻居被选择
- 同种类型的邻居放在了一起,邻居信息可以聚合
二、C2节点异构内容的编码
同一个节点,也往往有多种类型的特征,如图像,文字等,文章提出先对这一类特征进行预训练,如类别特征直接利用one-hot,文本特征利用par2vec,图像特征利用CNN,训练得到每类特征的向量表示后,利用Bi-LSTM进行编码后聚合。
(简而言之就是两步:1.每个属性的embedding。2.多个属性的BILSTM聚合——不用考虑顺序)
好处:以往的方法是将不同的属性特征直接拼接,或者将其线性转换到一个向量中。本文是使用Bi-LSTM捕获深层次的特征交互信息,同时增强了模型的表达能力。



FC是用作维度统一化,将不同尺寸的数据转化成统一规格,双向的LSTM具体运用为:从左开始:LSTM{x0,x1,x2....xn},从右开始LSTM{xn,xn-1.....x2,x1,x0},两部分拼接起来得到一个输出;
论文中提到这种编码方式有以下3个优点:
- 结构简单参数少,模型实现和微调相对容易;
- 可融合异质的内容/属性信息,表达能力强;
- 模型易于扩展,可以额外添加属性特征。
三、C3聚合异质邻居的信息(两个过程分别做如下描述)
(1)同一类型邻居的聚合:same type neighbors aggregation

和feature aggregation方法相同。 
(2)不同类型邻居的聚合:types combination

针对每种类型的节点进行了聚合,生成了∣ O V ∣个聚合向量,接下来要将它们再聚合起来。由于不同类型的邻居节点对学习到节点v最终的表示贡献度不同,所以使用注意力机制,为不同类型分配不同的注意力。
节点v最终的向量表示为: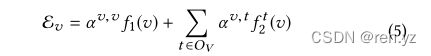
f1(v)是中心节点的content embedding.。
f2(v)是type embedding的聚合 (
(
注意力参数a的计算方式为:
u∈R2d×1is the attention parameter
四、目标和模型训练
为了执行异构图表示学习,我们用参数Θ:定义以下目标:
 (使v的邻居为vc的概率最大的参数
(使v的邻居为vc的概率最大的参数 ),vc为某类型(v)下的一阶二阶邻居
),vc为某类型(v)下的一阶二阶邻居
![]() 是一系列根据随机游走采样的一阶二阶的t类型的邻居节点,
是一系列根据随机游走采样的一阶二阶的t类型的邻居节点,![]()
的定义如下: 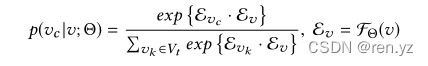
由于分母计算的难度,使用负采样,最终优化目标函数为

这部分没太看懂,具体在附录和实践中再仔细琢磨!!!
更新:大概看懂了:v就是当前节点,vc就是正例,就是一阶二阶的同类型content embedding,vc‘就是负采样,负采样你们肯定懂,采样到的负例节点的content embedding
上式中的三元组基于图上的随机游走序列生成。大致过程为:生成异构图随机游走序列,基于一个序列选择节点v的正节点v_c,采样生成与v_c对应的节点v的负节点v_c'。
明确目标函数后,模型基于mini-batch的方式训练,优化器是Adam optimizer。不断地进行训练迭代,直至指标收敛为止。
5.实验
该部分只分析实验结果,代码部分见后续博客更新。
代码中使用了学术图数据如下:

实验结果包括:
1.链接预测 2.推荐实验 3.节点分类和聚类 4.inductive的节点分类和聚类(分清直推式和归纳式的区别),归纳式类似于监督学习,直推式指训练集和测试集的数据都出现在图网络中 5.不同模块对实验结果的影响 6.超参数的设置对实验结果的影响
直推式和归纳式:
