我的NVIDIA开发者之旅——使用NeMo快速构建智能问答系统学习笔记
我的NVIDIA开发者之旅——使用NeMo快速构建智能问答系统学习笔记
"我的NVIDIA开发者之旅” | 征文活动进行中…
智能问答系统是自然语言处理领域的重要任务之一, 它是对无序语料信息进行有序、科学的整理,建立基于知识的分类模型; 这些模型可以指导新添加的分类语料库和服务信息,节省人力资源,提高信息处理的自动化程度。 它具有广泛的应用如:智能语音交互、在线客服、知识获取、个性化情感聊天等。
NeMo是一个用于构建新型最先进的对话AI模型的工具箱, NeMo有独立的集合用于自动语音识别(ASR)、自然语言处理(NLP)和文本到语音(TTS)模型。
一、智能问答系统简介
1.1、智能问答系统定义
智能问答系统(Question Answering System, QA)是自然语言处理领域的子任务之一,也是信息检索系统的一种高级形式 。它能用准确、简洁的自然语言回答用户用自然语言提出的问题。 问答系统是人工智能和自然语言处理领域中一个倍受关 注并具有广泛发展前景的研究方向。它具有广泛的应用比如:智能语音交互、在线客服、知识获取、个性化情感聊天等。
1.2、智能问答系统分类
1.2.1、基于结构化数据的问答系统
基于结构化数据的问答系统的主要思想是通过分析问题, 把问题转化为一个查询(query), 然后在 结构化数据库进行查询, 返回的查询结果即为问题 的答案。体现强人工智能的成分不多。
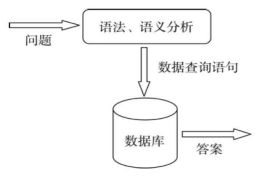
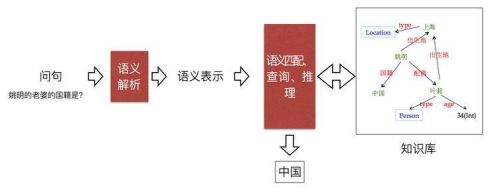
1.2.2、基于知识图谱的问答系统
知识图谱:是由一些相互连接的实体和他们的属性构成的,实体的每一条属性和关系就是一条三元组。
目前实现基于知识图谱的问答系统主要有三类方法,分别为基于模板匹配的方法;基于语义解析的方法以及基于向量建模的方法。
1.2.3、基于自由文本阅读理解的问答系统
是指模型根据对非结构化的文本进行阅读理解,从而从中抽取出答案。阅读理解能够让计算机帮助人类在大量文本中快速找到准确答案,从而减轻人们对信息的获取的成本。具体来讲,机器阅读理解和问答任务(QA)指的是给定一个问题和一个或多个文本,训练的QA系统可以依据文本找出问题答案。
二、智问答系统的工作流程和原理
2.1、智能问答系统的工作流程
2.1.1、流程概述
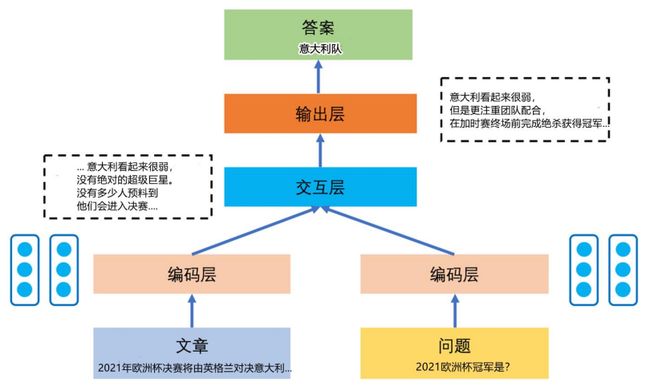
(1)首先有两部分输入,包含原文与基于提出的问题。
(2)在编码层将文本数字化,转化成向量表达的形式。
(3)将结果输入到神经网络的编码程序中,对文本的特殊向量进行编码,把编码后的结果输入到交互层。
(4)通过交互层的模型建立文章与问题之间的语义联系,模型将原文与问题的语义结合起来进行考量。
(5)经过输出层,模型找出最大概率的答案的起始与结束位置,输出答案。
2.1.2、流程图
2.2、智能问答系统经典模型
2.2.1、BiDAF
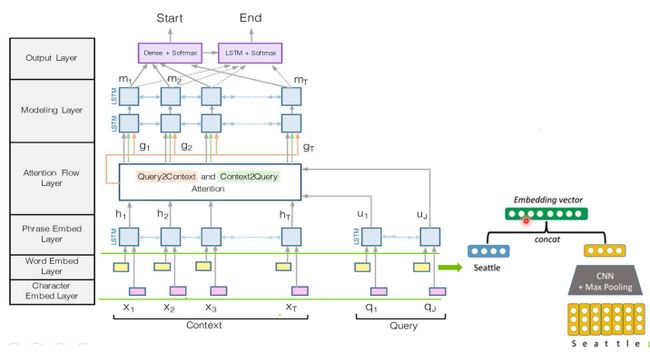
BiDAF共有6层,分别是Character Embedding Layer、Word Embedding Layer、Contextual Embedding Layer、Attention Flow Layer、Modeling Layer和Output Layer。其中前三层是一个多层级上下文不同粒度的表征编码器。第四层则是双向注意流层,这是原文的核心层。第五层是一个编码层,编码第四层输出的问题感知的上下文表征。第六层就是一个预测答案的范围。
(1)字符嵌入层:用字符级CNNs将每个字映射到向量空间。
(2)字嵌入层:利用预训练的词嵌入模型,将每个字映射到向量空间。
(3)上下文嵌入层:利用周围单词的上下文线索来细化单词的嵌入。这前三层同时应用于问句和原文。
(4)注意力流层:将问句向量和原文向量进行耦合,并为原文中每个词生成一个问句相关的特征向量集合。
(5)建模层:使用RNN以扫描整个原文。
(6)输出层:输出问句对应的回答。
2.2.2、QANet
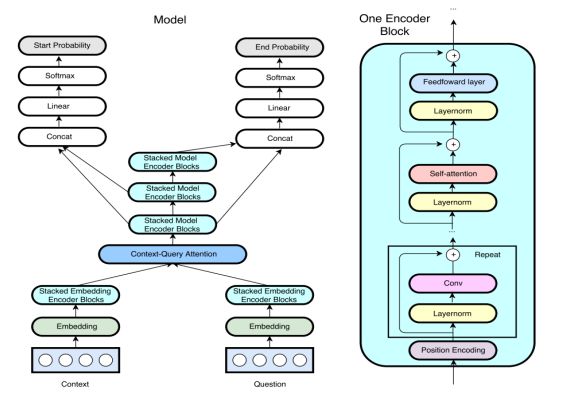
QANet模型网络结构介绍
(1)输入的数据有Context和Question两部分组成。
(2)通过Embedding层转化为Embedding向量,分为word embedding和char embedding。Highway network包含在embedding层中。
(3)通过Encoder Block层,Encoder Block是QANet重要组成部分,如右图所示。Encoder Block层分别通过四个部分,Position Encoding、 Conv卷积层、Self attention和Feedword层。每个部分开头做layernorm处理,结尾做残差连接。
(4)Context和Question的encoder向量,通过Context Query Attention计算相关性。
(5)接着通过三层Encoder Block层,第一层和第二层输出连接后,通过一层全链接层作为起始位置的概率。
(6)第一层和第三层输出连接后,通过一层全链接层作为起始位置的概率。
2.2.3、BERT
BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言表征模型。它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),以致能生成深度的双向语言表征。
该模型有以下主要优点:
1)采用MLM对双向的Transformers进行预训练,以生成深层的双向语言表征。
2)预训练后,只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
BERT的输入
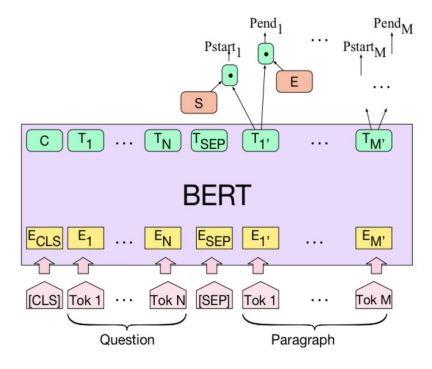
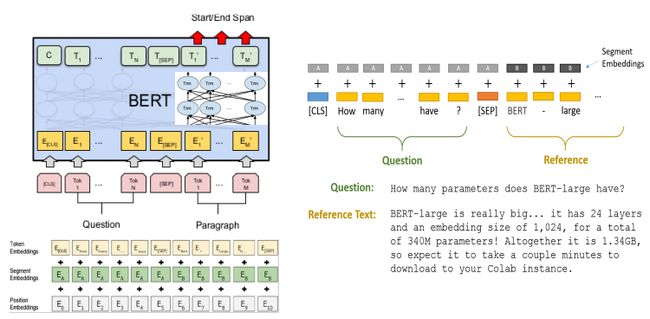
BERT的输入为每一个token对应的表征*(图中的粉红色块就是token,黄色块就是token对应的表征)*,并且单词字典是采用WordPiece算法来进行构建的。为了完成具体的分类任务,除了单词的token之外,作者还在输入的每一个序列开头都插入特定的分类token([CLS]),该分类token对应的最后一个Transformer层输出被用来起到聚集整个序列表征信息的作用。
由于BERT是一个预训练模型,其必须要适应各种各样的自然语言任务,因此模型所输入的序列必须有能力包含一句话*(文本情感分类,序列标注任务)或者两句话以上(文本摘要,自然语言推断,问答任务)*。那么如何令模型有能力去分辨哪个范围是属于句子A,哪个范围是属于句子B呢?BERT采用了两种方法去解决:
1)在序列tokens中把**分割token([SEP])**插入到每个句子后,以分开不同的句子tokens。
2)为每一个token表征都添加一个可学习的分割embedding来指示其属于句子A还是句子B。
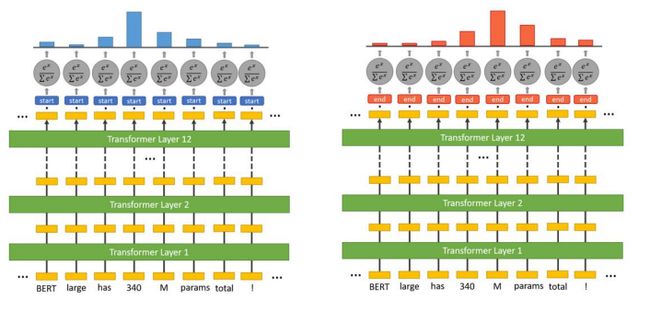
BERT的输出
C为分类token([CLS])对应最后一个Transformer的输出, 则代表其他token对应最后一个Transformer的输出。对于一些token级别的任务*(如,序列标注和问答任务),就把 输入到额外的输出层中进行预测。对于一些句子级别的任务(如,自然语言推断和情感分类任务)*,就把C输入到额外的输出层中,这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
三、构建适合于NeMo的中文问答数据集
3.1、SQuAD
SQuAD是Stanford Question Answering Dataset 的首字母缩写。这是一个阅读理解数据集,由众包工作者在一组维基百科文章上提出的问题组成,其中每个问题的答案都是相应文章中的一段文本,某些问题可能无法回答.
Squad官网: https://rajpurkar.github.io/SQuAD-explorer/
3.1.1、SQuAD1.0
SQuAD 1.1 包含针对500+文章的10万+问答对。
论文地址:https://arxiv.org/pdf/1606.05250
下载地址:https://data.deepai.org/squad1.1.zip
3.1.2、SQuAD2.0
SQuAD2.0组合了SQuAD1.1中的10万个问题,并增加了超过5万个无法回答的问题,这些问题由众包工作者以对抗(adversarially)的方式设计,看起来与可回答的问题相似。
为了在SQuAD2.0数据集上表现出色。系统不仅必须在可能的情况下回答问题,还必须确定篇章数据何时不支持回答,并避免回答。
论文地址:https://arxiv.org/abs/1806.03822
数据集地址: https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v2.0.json
3.1.2.1、Squad2.0英文数据集格式:

{
"data": [
{
"title": "Super_Bowl_50",
"paragraphs": [
{
"context": " numerals 50.",
"qas": [
{
"answers": [
{
"answer_start": 177,
"text": "Denver Broncos"
},
{
"answer_start": 177,
"text": "Denver Broncos"
},
{
"answer_start": 177,
"text": "Denver Broncos"
}
],
"question": "Which NFL team represented the AFC at Super Bowl 50?",
"id": "56be4db0acb8001400a502ec"
}
]
}
]
}
],
"version": "1.1"
}
3.1.2.2、Squad2.0中文数据集格式:

四、在NeMo中训练中文问答系统模型基本步骤
点击观看课程视频:
4.1、导入NeMo工具库及相关工具类
4.1、创建目录存放数据集
4.3、定义相关超参数
4.4、加载模型配置文件
4.5、通过OmegaConf工具库创建Config对象
4.6、通过config对模型配置文件进行修改
4.7、设置模型的训练器
4.8、初始化模型
4.9、开始训练模型
4.10、模型进行推理
4.11、模型的保存
五、使用模型进行推理完成中文智能问答的任务
课程视频链接: https://www.bilibili.com/video/BV1744y167Ag
"我的NVIDIA开发者之旅” | 征文活动进行中…