Nvidia Nemo 使用笔记
环境:python=3.8.0 + conda 4.5.11 + cuda 11.4.0 +Pytorch 1.10.2
1 conda 环境:
conda:基本应用【查询版本:环境更新:添加镜像:创建新环境:使用】
=====查看安装的conda 版本:
(base) C:\Users\Administrator>conda -V
conda 4.5.11
=====查看当前conda 环境中安装的库:
conda env list
=====添加镜像:
conda config --add channels https://pypi.douban.com/anaconda/cloud/conda-forge/
conda config --add channels https://pypi.douban.com/anaconda/cloud/msys2/
conda config --add channels https://pypi.douban.com/anaconda/cloud/bioconda/
conda config --add channels https://pypi.douban.com/anaconda/cloud/menpo/
conda config --add channels https://pypi.douban.com/anaconda/cloud/pytorch/
=====查看镜像:
(base) C:\Users\Administrator>conda config --show-source
==> C:\Users\Administrator\.condarc <==
channels:
- https://pypi.douban.com/anaconda/cloud/pytorch/
- https://pypi.douban.com/anaconda/cloud/menpo/
- https://pypi.douban.com/anaconda/cloud/bioconda/
- https://pypi.douban.com/anaconda/cloud/msys2/
- https://pypi.douban.com/anaconda/cloud/conda-forge/
- defaults
show_channel_urls: True
=====换回默认镜像:
conda config --remove-key channels
======更新conda:
conda update conda
=====查询是否安装【pandas】:
(base) C:\Users\Administrator>conda list pandas
# packages in environment at D:\ProgramData\Anaconda3:
#
# Name Version Build Channel
pandas 0.23.4 py37h830ac7b_0 defaults
======创建新的虚拟环境:默认版本:Python 3.8.0
conda create -n myNemo3.8.0 python==3.8.0
======查询虚拟环境:
(base) C:\Users\Administrator>conda env list
# conda environments:
#
base * D:\ProgramData\Anaconda3
myNemo D:\ProgramData\Anaconda3\envs\myNemo
======切换虚拟环境:
(base) C:\Users\Administrator>conda activate myNemo
======查看新环境中的库:
(myNemo) C:\Users\Administrator>conda list
# packages in environment at D:\ProgramData\Anaconda3\envs\myNemo:
#
# Name Version Build Channel
certifi 2021.10.8 py37haa95532_2 defaults
pip 21.2.4 py37haa95532_0 defaults
python 3.7.0 hea74fb7_0 defaults
setuptools 58.0.4 py37haa95532_0 defaults
vc 14.2 h21ff451_1 defaults
vs2015_runtime 14.27.29016 h5e58377_2 defaults
wheel 0.37.1 pyhd3eb1b0_0 defaults
wincertstore 0.2 py37haa95532_2 defaults
======安装自己需要用的库到新环境中:
conda install pandas
======查询当前虚拟环境中安装的依赖库:
conda list -n myNemo
NeMo环境:
1、查看驱动程序版本,驱动版本下载所需要的环境:CUDAToolkit版本(CUDA11.4.0)
版本对照参考:Release Notes :: CUDA Toolkit Documentation (nvidia.com)

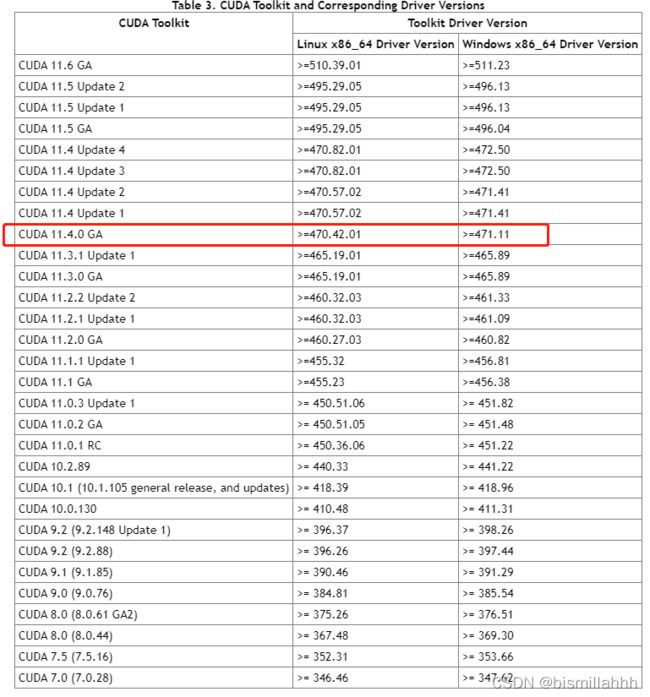
2 驱动下载:
CUDA Toolkit Archive | NVIDIA Developer
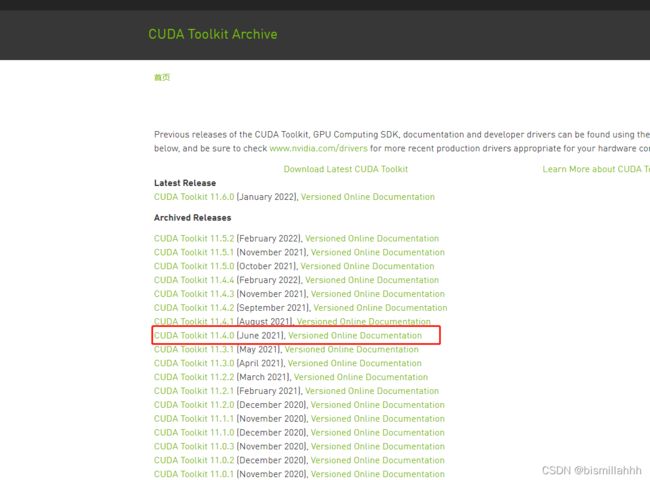
CUDA Toolkit 11.4 Downloads | NVIDIA Developer

下载安装完成之后:配置环境:
CUDA_PATH = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
CUDA_PATH_V10_1 = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.1
CUDA_LIB_PATH = %CUDA_PATH%\lib\x64
CUDA_BIN_PATH = %CUDA_PATH%\bin
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64

测试是否安装成功:
执行:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\extras\demo_suite\deviceQuery.exe
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\extras\demo_suite\deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce GTX 1050 Ti"
CUDA Driver Version / Runtime Version 11.4 / 11.4
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 4096 MBytes (4294967296 bytes)
( 6) Multiprocessors, (128) CUDA Cores/MP: 768 CUDA Cores
GPU Max Clock rate: 1418 MHz (1.42 GHz)
Memory Clock rate: 3504 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 1048576 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 5 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.4, CUDA Runtime Version = 11.4, NumDevs = 1, Device0 = NVIDIA GeForce GTX 1050 Ti
Result = PASS
Official Drivers | NVIDIA

2 Torch 环境
安装对应版本的pytotch Previous PyTorch Versions | PyTorch
(myNemo) C:\Users\Administrator>conda install pytorch torchvision torchaudio cudatoolkit=11.3.1 -c pytorch

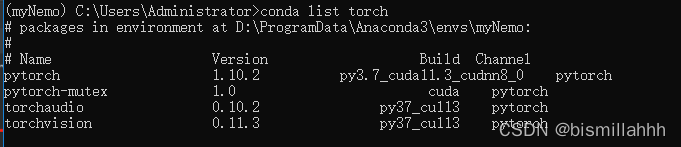
测试是否可用:
测试过程可能存在问题: OSError: [WinError 1455] 页面文件太小,无法完成操作 的问题
解决办法:方法3 可以解决。多种方法彻底解决pycharm中: OSError: [WinError 1455] 页面文件太小,无法完成操作 的问题_孤柒的博客-CSDN博客_python页面文件太小,无法完成操作
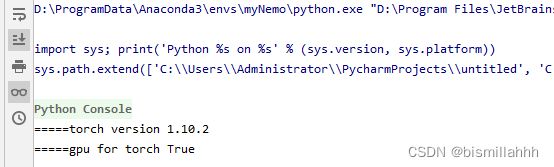
import torch
print('=====torch version',torch.__version__)
print('=====gpu for torch',torch.cuda.is_available())
3 Nemo 环境
1> 下载Nemo GitHub - NVIDIA/NeMo: NeMo: a toolkit for conversational AI
2> 安装Nemo:
python setup.py install安装出现的问题: RuntimeError: Python version >= 3.8 required.【conda 默认版本为3.7.0,重新创建虚拟环境,指定安装的python版本为3.8.0,然后重新安装torch和nemo】
需要的环境还包括:
1、 Microsoft Visual C++ 14.0安装
error: Microsoft Visual C++ 14.0 is required. Get it with "Build Tools for Visual Studio": https://visualstudio.microsoft.com/downloads/ Tools":解决办法有空再补充,需要的工具先上传了:
链接:https://pan.baidu.com/s/12vKWGhvJoDgifoEdA9s9xw?pwd=kuq3
提取码:kuq3
--来自百度网盘超级会员V5的分享2、youtokentome安装

3> Nemo测试:
import nemo
import nemo.collections.nlp as nemo_nlp
# 在NeMo中使用Bert做分词
get_tokenizer = nemo_nlp.modules.get_tokenizer_list()
print('=====get_tokenizer ',get_tokenizer)ModuleNotFoundError: No module named 'hydra'
ModuleNotFoundError: No module named 'pytorch_lightning'
ModuleNotFoundError: No module named 'transformers'
解决:
pip install hydra-core --upgrade
(myNemo3.8.0) D:\常用电脑软件\nvidia\NeMo-main>conda list hydra
# packages in environment at D:\ProgramData\Anaconda3\envs\myNemo3.8.0:
#
# Name Version Build Channel
hydra-core 1.1.1
=========================================================
pip install pytorch-lightning
(myNemo3.8.0) D:\常用电脑软件\nvidia\NeMo-main>conda list pytorch_lightning
# packages in environment at D:\ProgramData\Anaconda3\envs\myNemo3.8.0:
#
# Name Version Build Channel
=========================================================
conda install transformers
(myNemo3.8.0) C:\Users\Administrator>conda list transformers
# packages in environment at D:\ProgramData\Anaconda3\envs\myNemo3.8.0:
#
# Name Version Build Channel
transformers 2.1.1 pyhd3eb1b0_0 defaults 【transformers导入依赖出错的问题】:一开始安装的版本是2.1.1,后来使用过程中出现有新的问题,可能需要更新,目前可以正常使用的版本:transformers 4.14.1
4 测试Nemo
import nemo
import nemo.collections.nlp as nemo_nlp
# 在NeMo中使用Bert做分词
get_tokenizer = nemo_nlp.modules.get_tokenizer_list()
print('=====get_tokenizer ',get_tokenizer)
tokenizer_en = nemo_nlp.modules.get_tokenizer(tokenizer_name="bert-base-cased")
tokenizer_zh = nemo_nlp.modules.get_tokenizer(tokenizer_name="bert-base-chinese")
# 准备少量文本数据测试
data_text_en = "NeMo is a toolkit for creating Conversational AI applications.NeMo toolkit makes it possible for researchers to easily compose complex neural network architectures "
data_text_zh ="我爱你中国"
tokenized_en = [tokenizer_en.bos_token] + tokenizer_en.text_to_tokens(data_text_en) + [tokenizer_en.eos_token]
print(tokenized_en)
# 将token转换为神经模型的input_ids
print(tokenizer_en.tokens_to_ids(tokenized_en))
# 打印并查看语料库
print(tokenizer_zh.tokenizer.vocab)
## 二、 在NeMo中使用BERT做命名实体识别
### 加载命名实体识别预训练模型
pretrained_ner_model = nemo_nlp.models.TokenClassificationModel.from_pretrained(model_name="ner_en_bert") #执行之后需要下载或安装
# [NeMo I 2022-02-14 00:33:19 cloud:66] Downloading from: https://api.ngc.nvidia.com/v2/models/nvidia/nemo/ner_en_bert/versions/1.0.0rc1/files/ner_en_bert.nemo to C:\Users\Administrator\.cache\torch\NeMo\NeMo_1.7.0rc\ner_en_bert\5ec56ceb814b9dba236d4962586d67cc\ner_en_bert.nemo
# [NeMo I 2022-02-14 00:34:20 common:704] Instantiating model from pre-trained checkpoint
# [NeMo I 2022-02-14 00:34:23 tokenizer_utils:125] Getting HuggingFace AutoTokenizer with pretrained_model_name: bert-base-uncased, vocab_file: C:\Users\Administrator\AppData\Local\Temp\tmp5_u_9jwu\tokenizer.vocab_file, special_tokens_dict: {}, and use_fast: False
# Downloading: 100%|██████████| 28.0/28.0 [00:00<00:00, 27.2kB/s]
# Downloading: 100%|██████████| 570/570 [00:00<00:00, 571kB/s]
# Downloading: 100%|██████████| 226k/226k [00:00<00:00, 250kB/s]
# Downloading: 100%|██████████| 455k/455k [00:01<00:00, 437kB/s]
# Using eos_token, but it is not set yet.
# Using bos_token, but it is not set yet.
# [NeMo W 2022-02-14 00:34:42 modelPT:147] If you intend to do training or fine-tuning, please call the ModelPT.setup_training_data() method and provide a valid configuration file to setup the train data loader.
# Train config :
# text_file: text_train.txt
# labels_file: labels_train.txt
# shuffle: true
# num_samples: -1
# batch_size: 64
#
# [NeMo W 2022-02-14 00:34:42 modelPT:154] If you intend to do validation, please call the ModelPT.setup_validation_data() or ModelPT.setup_multiple_validation_data() method and provide a valid configuration file to setup the validation data loader(s).
# Validation config :
# text_file: text_dev.txt
# labels_file: labels_dev.txt
# shuffle: false
# num_samples: -1
# batch_size: 64
#
# [NeMo W 2022-02-14 00:34:42 modelPT:160] Please call the ModelPT.setup_test_data() or ModelPT.setup_multiple_test_data() method and provide a valid configuration file to setup the test data loader(s).
# Test config :
# text_file: text_dev.txt
# labels_file: labels_dev.txt
# shuffle: false
# num_samples: -1
# batch_size: 64
#
# [NeMo W 2022-02-14 00:34:42 nlp_overrides:207] Apex was not found. Please see the NeMo README for installation instructions: https://github.com/NVIDIA/apex
# Megatron-based models require Apex to function correctly.
# [NeMo W 2022-02-14 00:34:42 modelPT:1221] World size can only be set by PyTorch Lightning Trainer.
# [NeMo W 2022-02-14 00:34:42 modelPT:214] You tried to register an artifact under config key=tokenizer.vocab_file but an artifact for it has already been registered.
# Downloading: 100%|██████████| 420M/420M [00:16<00:00, 26.8MB/s]
# Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertModel: ['cls.predictions.transform.dense.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.bias']
# - This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
# - This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
# Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertEncoder: ['cls.predictions.transform.dense.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.bias']
# - This IS expected if you are initializing BertEncoder from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
# - This IS NOT expected if you are initializing BertEncoder from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
# [NeMo I 2022-02-14 00:35:15 save_restore_connector:154] Model TokenClassificationModel was successfully restored from C:\Users\Administrator\.cache\torch\NeMo\NeMo_1.7.0rc\ner_en_bert\5ec56ceb814b9dba236d4962586d67cc\ner_en_bert.nemo.
print('====END=====')