K-近邻算法(kNN)
什么是k近邻算法?
工作原理:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
事例:
比如电影可以按照题材进行分类分为动作片和爱情片,但是如何正确又有什么明显的区别呢,动作片中会出现接吻的镜头,而爱情片中也会有打斗的场景,我们不能单纯依靠是否有某一镜头而确定电影的类别,但是动作片中的打斗镜头肯定比爱情片多,而爱情片中的亲吻镜头肯定也比动作片多,所以我们就可以依靠这个镜头数量的多少来进行电影题材的确定。

如何确定上图中问号处电影的类型呢?
首先我们需要先确定电影中存在的打斗镜头和接吻镜头的个数。

上面则是各个电影的打斗和接吻镜头的个数以及其电影类型,可以以其镜头个数进行坐标的定位,即问号出的坐标为(18,90)
因此可以将问号处与各个电影之间的距离计算出来,如下图
现在我们知道了样本集中所有电影与未知电影的距离,并且从小到大排序,因此我们可以找到k个距离最近的电影,来判断其类型,
比如我们假定k=3,那么最靠近的三个电影都为爱情片,因此我们判断未知电影是爱情片,那如果与未知电影相距的最近三个电影中分别为爱情片,动作片,动作片,那么我们则判断未知电影为动作片,当然我们还可以选择不同的k值来进行判断。
k-近邻算法的一般流程
(1)收集数据:可以使用任何方法
(2)准备数据:距离计算所需要的数值,最好是结构化的数据格式
(3)分析数据:可以使用任何方法
(4)训练算法:此步骤不适用于k——近邻算法
(5)测试算法:计算错误率
(6)使用算法:首先输入样本数据和结构化的输出结果,然后运行k近邻算法判定输入样本属于哪个分类,然后对计算处的分类执行后续处理
关于k-近邻算法的基本问题
1.如何确定k的值
通过上述的事例我们知道k的取值不同会影响结果的判断,那么我们应该如何确定一个k的取值呢?
| k值 | 影响 |
|---|---|
| 过大 | 【欠拟合】受到样本均衡的问题 |
| 过小 | 【过拟合】容易受到异常点的影响 |
在实际应用中,k值过大的话容易受到样本均衡性的影响,比如上述例子当k=6时动作片与爱情片的比值为3:3,那么就无法判断未知电影的类型了,当k值过小的话则容易受到异常样本的影响,上述例子中若k=1,而最近点的电影错误的将爱情片统计为了动作片那么最终结果就因为数据问题而出现了错误。
因此k值一般取一个比较小的数值之后不断增加K的值,采用交叉验证法(简单来说,就是把训练数据在分成两组:训练集和验证集)来选择最优的K值。
2.样本距离间的计算
欧氏距离:两点之间的直线距离

曼哈顿距离:两个点在坐标轴上的绝对轴距总和

具体例子:
下表是随机询问几名集美大学学生的食堂堂食次数,根据他们在不同食堂的堂食次数我们可以据此推断出其是住在本部还是诚毅。
集美大学学生一周内不同食堂堂食表
| 姓名 | 本部食堂堂食次数 | 诚毅食堂堂食次数 | 宿舍位置 |
| A | 15 | 3 | 本部 |
| B | 16 | 5 | 本部 |
| C | 5 | 15 | 诚毅 |
| D | 12 | 2 | 本部 |
| E | 7 | 10 | 诚毅 |
| F | 14 | 0 | 本部 |
| G | 3 | 18 | 诚毅 |
| H | 12 | 6 | ? |
上表可以看出当本部食堂堂食次数多的大都为住在本部的学生,而诚毅食堂堂食次数多的大都为住在诚毅的学生,现在给出未知学生H的各食堂堂食次数,利用k近邻算法推断出其是住在本部还是诚毅的学生。
如下散点图表示了上述图表中的数据在二维坐标内的分布状态。其中红色点则是同学H的位置,那么该如何确定它是住在什么位置呢?
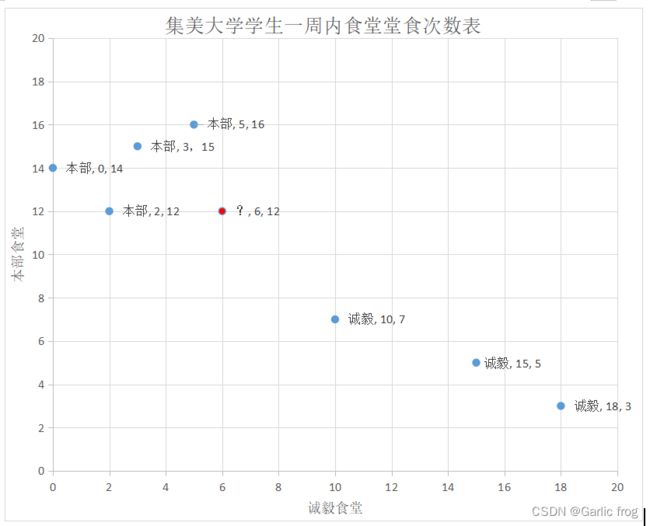
上述中我们知道了我们可以使用k近邻分布来确定该学生的位置,假定我们将k=3,则我们需要找到距离红点最近的三个点并确定其三个点代表的是本部还是诚毅,由上表我们容易得知距离红点最近的三个点分别是(2,12),(3,15),(5,16),而且这三个点都代表本部,所以我们可以判断H学生是住在本部的。
代码实现:
首先准备数据:
from numpy import *
import operator
#导入训练集以及对应的位置
def createDateSet():
group = array([[3, 15], [5, 16], [15, 5], [2, 12], [10, 7], [0, 14], [18, 3]])
labels = ['本部', '本部', '诚毅', '本部', '诚毅', '本部', '诚毅']
return group, labels实现kNN算法分类
#KNN算法核心,即计算出k个最近邻点的位置
def classify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteILabel = labels[sortedDistIndicies[i]]
classCount[voteILabel] = classCount.get(voteILabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
进行测试以及错误率的计算
group,labels = createDateSet()
errorCount=0.0
i = 0
train_group = array([[6, 12],[10,5],[5,10],[9,5],[6,8]])
train_Size=train_group.shape[0]
True_labels = ['本部', '诚毅', '本部','诚毅','本部']
train_labels = []
for i in range(train_Size):
train_labels.append(classify(train_group[i], group, labels, 3)) #3即为k的取值
if(train_labels[i]!=True_labels[i]): errorCount += 1.0
print('姓名%c 宿舍位置 %s' % (chr(ord('H') + i),train_labels[i]))
print ("the total error rate is:", errorCount/(i+1))整体代码:
from numpy import *
import operator
#导入训练集以及对应的位置
def createDateSet():
group = array([[3, 15], [5, 16], [15, 5], [2, 12], [10, 7], [0, 14], [18, 3]])
labels = ['本部', '本部', '诚毅', '本部', '诚毅', '本部', '诚毅']
return group, labels
#KNN算法核心,即计算出k个最近邻点的位置
def classify(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteILabel = labels[sortedDistIndicies[i]]
classCount[voteILabel] = classCount.get(voteILabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
group,labels = createDateSet()
errorCount=0.0
i = 0
train_group = array([[6, 12],[10,5],[5,10],[9,5],[6,8]])
train_Size=train_group.shape[0]
True_labels = ['本部', '诚毅', '本部','诚毅','本部']
train_labels = []
for i in range(train_Size):
train_labels.append(classify(train_group[i], group, labels, 3)) #3即为k的取值
if(train_labels[i]!=True_labels[i]): errorCount += 1.0
print('姓名%c 宿舍位置 %s' % (chr(ord('H') + i),train_labels[i]))
print ("the total error rate is:", errorCount/(i+1))测试结果

由上图可知测试结果全部正确,当然这显然有点离谱,原因则是因为准备数据阶段的数据不够多。
归一化数值:
当然在我们收集数据阶段我们也许会出现一些数据远大于其他数据的情况,当这种情况出现时我们利用这些数据计算样本间的距离时,会发现这些数据在距离计算中占据了主导作用,其他数据貌似没用了,所以这时我们为了避免出现这种情况就需要进行数据的归一化处理,将数值的取值范围处理为0-1或者-1-1之间,则可以有效避免这种情况的出现以影响测试结果,当然我这里的数据不需要进行归一化处理,因为所有数值都在0-20之间并未出现超大数值的问题,所以我们省略这一步骤。
现在我们测试完毕我们还可以改变k值再看看错误率会如何改变
当k=1 错误率变成了0.2
当k=7错误率变成了0.4 当然收集的数据只有7个而其中本部就占了四个所以当k等于7时所有预测都会变成本部,这便是数据样本太少的弊端了

由此可见k的取值也决定了我们算法的效率。
若KNN算法核心代码不懂的话可以看看下面博客的解释
核心代码解释:(30条消息) K近邻算法代码注释及详解_aidianta1907的博客-CSDN博客