人工智能-机器学习-特征工程
我们用泰坦尼克号事件生还者信息举例, 采用KNN算法预测某个人的生还率, 采用KNN临近算法
数据链接: 泰坦尼克号csv数据集
一.利用pandas观察数据情况
我们先看下数据:

各列对应字端的含义为:
passengerId: 表示乘船编号
surverved: 表示是否存活, 0为死亡, 1为生存(此列为标签)
pclass: 客舱等级
name: 名字
sex: 性别
age: 年龄
sibsp: 兄弟姐妹数和配偶数
parch: 船上父母数和子女数
ticket: 船票编号
fare: 船票价格
cabin:客舱号
embarked: 登船港口
"""
1.利用pandas观察数据情况
"""
import pandas as pd
data = pd.read_csv("train.csv")
print(data.info())
# 打印全部数据信息
pd.set_option('display.max_columns', None)
pd.set_option('display.width', 1000)
# 查看所有类型数据情况
# print(data.describe(include='all'))
# 查看数字类型的量纲情况, 观察量纲范围
print(data.describe())
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
可以看到每列的列名和数据量(是否为null)和数据类型。
1. 可以观察到, id列和大多数列非空值有 891 个数据,而 Age、Cabin、Embarked 分别为 714, 204, 889 个数据, 说明其中存在空值, 如果需要把这几列为做特征的话, 我们需要对它们进行空值处理。
2. 数据类型中, Name、Sex、Ticket、Cabin、Embarked数据类型为 object 而非数字, 如果这些数据具有分类性质并且我们需要拿这几列数据当做特征的话, 还需要将之转换为数字, 常用的方式比如 one-hot(独热编码)。
PassengerId Survived Pclass Age SibSp Parch Fare
count 891.000000 891.000000 891.000000 714.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008 0.381594 32.204208
std 257.353842 0.486592 0.836071 14.526497 1.102743 0.806057 49.693429
min 1.000000 0.000000 1.000000 0.420000 0.000000 0.000000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000 0.000000 7.910400
50% 446.000000 0.000000 3.000000 28.000000 0.000000 0.000000 14.454200
75% 668.500000 1.000000 3.000000 38.000000 1.000000 0.000000 31.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000 6.000000 512.329200
可以观察数据是否需要标准化, 比如是否存在异常点, 量纲是否需要统一(采用梯度下降训练的需要统一量纲, 本文采用KNN算法, 所以不需要), 以及是否需要归一化、分桶离散、标签均衡等操作。
二.空值处理
常用的空值处理方式分两种:
1.针对离散型数据的, 比如Cabin、Embarked这种纯文本类, 我们一般是建立一个新的类别来代替所有的空值, 比如我们将该字端为空的位置设置为字符 “N”。
2.针对连续型数据, 比如 Age 这个属于数字类。可以采用数学统计值填充, 比如中位数、平均值或者通过插值计算、极大似然估计、聚类分析、回归分析等方式进行填充。
# 一. 空值处理 (空值填充要在 one-hot 之前做)
# 对连续型数值空值填充
data.loc[(data.Age.isnull()), 'Age'] = np.mean(data['Age'])
# 对离散型数值填充
data.loc[(data.Cabin.isnull()), 'Cabin'] = "N"
data.loc[(data.Embarked.isnull()), 'Embarked'] = "N"
print(data.info())
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 891 non-null object
11 Embarked 891 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
三.独热编码
对于一些分类特征, 我们经常需要将这些特征进行特征数字化, 拿性别举例, 比如某一列的属性为 “性别”, 该列数据全部为 男或者女, 我们可以将性别这一列变为两列, 如: “性别_男”, “性别_女”, 如果为男性,则 “性别_男” 为 1,“性别_女”为 0,如果为女性, 则 “性别_男” 为 0,“性别_女”为 1, 如下:

也可以使用 sklearn 的 preproccessing 库的 OneHotEncoder 类对数据进行独热编码:
from sklearn.preprocessing import OneHotEncoder
import numpy as np
train_x = np.array([["男"], ["女"], ["女"], ["不男不女"], ["男"]])
print(train_x)
# 做独热编码
tran_x_standard = OneHotEncoder().fit_transform(train_x).toarray()
print(tran_x_standard)
[['男']
['女']
['女']
['不男不女']
['男']]
[[0. 0. 1.]
[0. 1. 0.]
[0. 1. 0.]
[1. 0. 0.]
[0. 0. 1.]]
对于文本类型的数据, 我们通过观察, 明显知道 Name 并没有分类性质(除非需要考虑是否是贵族姓氏),并且与乘客最后是否生还没什么关系的, 所以只对其他四种字段"Sex", “Ticket”,
“Cabin”, “Embarked” 进行独热编码, 可以使用pandas提供的 get_dummies()方法进行独热编码。
# 二. 独热编码
# 对于文本类型的数据, 我们通过观察, 明显知道 Name并没有分类性质,并且与乘客最后是否生还没什么关系的
# 所以只对其他四种字段进行独热编码
need_one_hot_field = ["Sex", "Ticket", "Cabin", "Embarked"]
for col_name in need_one_hot_field:
# 使用 pandas 的 get_dummies方法进行独热编码
processed_data = pd.get_dummies(data[col_name], prefix="%s_" % col_name)
# 合并新的one hot 列到数据
data = pd.concat([data, processed_data], axis=1)
# 原列已经没用了, 删除远原列
data.drop([col_name], axis=1, inplace=True)
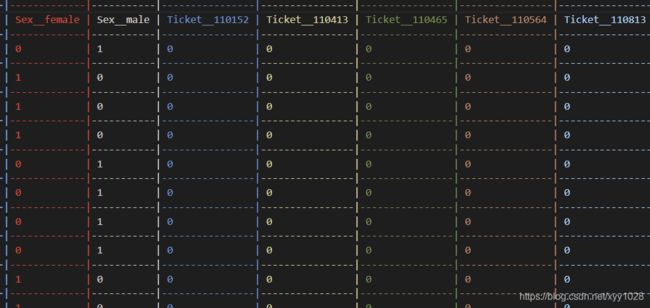
四.特征选择
我们再选择训练特征的时候, 要先分析我们要进行训练的字段, 有哪些是可以作为特征的, 比如 这份数据的 id 和 Name, 明显跟 事故后乘客是否生还没有什么关系, 则可以滤掉, 只采用我们需要的数据, 并将数据保存到 csv 中观察一下。
data = data.filter(regex='Survived|Age|SibSp|Parch|Fare|Cabin_.*|Embarked_.*|Sex_.*|Pclass')
data.to_csv("train_dispose.csv", index=None)
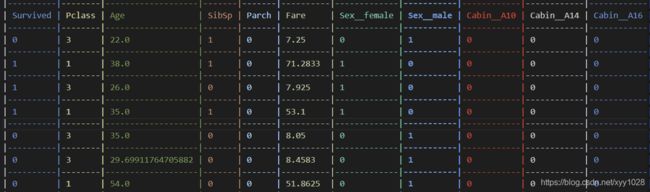
此时只包含我们想要的列
五.进行 KNN 临近算法训练
"""
5.KNN 临近算法
"""
import pandas as pd
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
data = pd.read_csv("train.csv")
# 一. 空值处理 (空值填充要在 one-hot 之前做)
# 对连续型数值空值填充
data.loc[(data.Age.isnull()), 'Age'] = np.mean(data['Age'])
# 对离散型数值填充
data.loc[(data.Cabin.isnull()), 'Cabin'] = "N"
data.loc[(data.Embarked.isnull()), 'Embarked'] = "N"
# 二. 独热编码
# 对于文本类型的数据, 我们通过观察, 明显知道 Name 是与 乘客最后是否生还没什么关系的
# 所以只对其他四种字段进行独热编码
need_one_hot_field = ["Sex", "Ticket", "Cabin", "Embarked"]
for col_name in need_one_hot_field:
# 使用 pandas 的 get_dummies方法进行独热编码
processed_data = pd.get_dummies(data[col_name], prefix="%s_" % col_name)
# 合并新的one hot 列到数据
data = pd.concat([data, processed_data], axis=1)
# 原列已经没用了, 删除远原列
data.drop([col_name], axis=1, inplace=True)
# 四. 特征选择
# 通过filter筛选需要留下的列,one_hot 列使用 _.* 进行过滤
data = data.filter(regex='Survived|Age|SibSp|Parch|Fare|Cabin_.*|Embarked_.*|Sex_.*|Pclass')
# 五. KNN临近测试
# 取出所有的数据值为 numpy类型(不包含表头)
data_array = data.values
# 以所有行, 第二列开始到最后一列的数据为特征
x = data_array[:, 1:]
# 以第一列是否生存为标签
y = data_array[:, 0]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# 构建KNN模型
model = KNeighborsClassifier()
# 训练
model.fit(x_train, y_train)
print("训练集准确度: %02.2f %%" % (model.score(x_train, y_train) * 100))
print("测试集准确度: %02.2f %%" % (model.score(x_test, y_test) * 100))
训练集准确度: 80.58 %
测试集准确度: 72.39 %
五.其他处理
1.无量纲化
如果数据的特征规格不一样, 则不能够放在一起比较, 我们需要将之转换为同一规格, 无量纲化可以解决这个问题。
1.1 标准化(对列向量处理)
标准化也叫Z-score standardization,将服从正态分布的特征值转换成标准正态分布,标准化需要计算特征的均值和标准差,公式表达为:
x = x − X ‾ S x = \frac{x- \overline X}{S} \quad x=Sx−X
可以使用 sklearn 的 preproccessing 库的 StandardScaler 类对数据进行标准化:
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
# 鸢尾花数据集
iris = load_iris()
train_x = iris.data
print(train_x)
# 进行标准化,返回值为标准化后的数据
tran_x_standard = StandardScaler().fit_transform(train_x)
print(tran_x_standard)
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
........
[5.9 3. 5.1 1.8]]
[[-9.00681170e-01 1.01900435e+00 -1.34022653e+00 -1.31544430e+00]
[-1.14301691e+00 -1.31979479e-01 -1.34022653e+00 -1.31544430e+00]
[-1.38535265e+00 3.28414053e-01 -1.39706395e+00 -1.31544430e+00]
[-1.50652052e+00 9.82172869e-02 -1.28338910e+00 -1.31544430e+00]
..........
[ 6.86617933e-02 -1.31979479e-01 7.62758269e-01 7.90670654e-01]]
1.2 区间缩放(对列向量处理)
区间缩放是指将数据范围缩小到某一区间, 常用的方法是利用最值将区间放缩到 0-1
x = x − M i n M a x − M i n x = \frac{x- Min}{Max -Min} \quad x=Max−Minx−Min
可以使用 sklearn 的 preproccessing 库的 MinMaxScaler 类对数据进行放缩:
from sklearn.preprocessing import MinMaxScaler
from sklearn.datasets import load_iris
# 鸢尾花数据集
iris = load_iris()
train_x = iris.data
print(train_x)
# 进行区间放缩,将列数据放缩到 0-1 之间
tran_x_standard = MinMaxScaler().fit_transform(iris.data)
print(tran_x_standard)
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
......
[5.9 3. 5.1 1.8]]
[[0.22222222 0.625 0.06779661 0.04166667]
[0.16666667 0.41666667 0.06779661 0.04166667]
[0.11111111 0.5 0.05084746 0.04166667]
[0.08333333 0.45833333 0.08474576 0.04166667]
.......
[0.44444444 0.41666667 0.69491525 0.70833333]]
- 在一些分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA、LDA这些需要用到协方差分析进行降维的时候,同时数据分布可以近似为正太分布,标准化方法表现更好。
- 在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用区间缩放法或其他归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围。
1.3 归一化(对行向量处理)
归一化目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准。
可以使用 sklearn 的 preproccessing 库的 Normalizer 类对数据进行归一化:
from sklearn.preprocessing import Normalizer
from sklearn.datasets import load_iris
# 鸢尾花数据集
iris = load_iris()
train_x = iris.data
print(train_x)
# 进行归一化
tran_x_standard = Normalizer().fit_transform(iris.data)
print(tran_x_standard)
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
...........
[5.9 3. 5.1 1.8]]
[[0.80377277 0.55160877 0.22064351 0.0315205 ]
[0.82813287 0.50702013 0.23660939 0.03380134]
[0.80533308 0.54831188 0.2227517 0.03426949]
[0.80003025 0.53915082 0.26087943 0.03478392]
...........
[0.69025916 0.35097923 0.5966647 0.21058754]]
2. 对定量特征二值化(对列向量处理)
定量特征二值化核心为设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。
可以使用 sklearn 的 preproccessing 库的 Normalizer 类对数据进行二值化:
from sklearn.preprocessing import Binarizer
from sklearn.datasets import load_iris
# 鸢尾花数据集
iris = load_iris()
train_x = iris.data
print(train_x)
# 定量特征二值化, 将阈值设为 3
tran_x_standard = Binarizer(threshold=3).fit_transform(iris.data)
print(tran_x_standard)
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
...........
[5.9 3. 5.1 1.8]]
[[1. 1. 0. 0.]
[1. 0. 0. 0.]
[1. 1. 0. 0.]
[1. 1. 0. 0.]
..........
[1. 0. 1. 0.]]
3. 哑编码(对列向量处理)
哑编码与独热编码的区别就是可以去除一个状态位, 比如[小学, 中学, 大学, 研究生, 博士], 我们去除热编码中博士生的状态位 [0 ,0, 0, 0, 1], 改为 [0, 0, 0, 0], 即如果不是前四种, 那必然是第五种。
还有其他很多处理…以后接触到再补充。。。。