ES性能优化之内存优化
文章目录
- 前言
- 一、ES性能优化之内存优化
-
- 一、调整节点内存大小
- 二、禁用Swapping
- 三、垃圾回收器调整(参考)
-
- 3.1打开垃圾回收日志
- 3.2使用jstat 检查垃圾回收器工作状态
- 3.3垃圾回收器调优
- 总结
前言
ES虽然具有较高的性能,同样也比较吃资源,通常调整节点内存大小,基本能解决ES常见的性能问题
提示:以下是本篇文章正文内容
一、ES性能优化之内存优化
一、调整节点内存大小
修改ES节点实例GC参数(Xms)和最大(Xmx)内存大小,并且保持值一致,重启Elasticsearch服务。
单个EsNode实例 看具体服务器内存大小调整,最大推荐31G左右。
如果EsMaster也有组件或业务连接,也需要调大GC参数,不然会导致内存溢出,不推荐业务连接EsMaster实例节点
二、禁用Swapping
大多数操作系统都尽可能多地为文件系统缓存使用内存,并切换出未使用的应用程序内存。这可能导致部分JVM堆被交换到磁盘上。
对于性能和节点的稳定性来说,这种交换是非常糟糕的,应该不惜一切代价避免。它可能导致垃圾收集持续几分钟而不是几毫秒,这可能导致节点响应缓慢,甚至脱离集群。
Linux/Unix系统中使用mlockall在RAM中锁定进程的地址空间,阻止Elasticsearch内存被交换出去,从而实现禁用Swapping。
禁用方式:1. Es使用的服务器安装操作系统时,也不要开启或配置swap分区。
2.Elasticsearch > 配置 > 自定义”。
3.添加新的参数“bootstrap.memory_lock”,设置值为“true”,保存配置并重启Elasticsearch服务。
4.使用root用户登录任意Elasticsearch数据节点,执行如下命令验证是否修改成功。执行命令后结果显示包含“true”则表示修改成功。
curl -XGET --tlsv1.2 --negotiate -k -u : “https://ip:httpport/_nodes?filter_path=**.mlockall”
三、垃圾回收器调整(参考)
配置垃圾回收器,避免内存交换,记录垃圾回收行为日志,诊断故障
JVM内存空间主要分为以下区域:
-
Eden区
初次分配的大部分对象都在该区域 -
Survivor区
分为 0区 和 1区,对Eden区进行垃圾回收仍然存活的对象 -
老年代
存储在Survivor区存货较长时间的对象 -
持久代
非堆空间,存储所有JVM自身的数据,如 java类,对象方法等 -
代码缓存区
用来编译,存放本地原生代码
3.1打开垃圾回收日志
ElasticSearch.yml配置文件中,默认被注释掉了:

指定了3中日志级别,并分别指定了阈值。
以info级别的日志配置为例:
如果年轻代垃圾回收过程耗时到达或超过700毫秒,ES就会写日志文件;
如果老年代垃圾回收过程耗时到达或超过5秒,也会记录。
日志文件记录类似如下:

上面日志是关于ConcurrentMarkSweep垃圾回收器的,也就是说,它是关于老年代的垃圾回收的。从中可以看出:
总的回收时间是14.8秒;在回收前,总共11.9GB空间中有8.6GB被占用,回收后,被占用空间减少到3.4GB;
接下来是更详细的统计信息,用来确定堆内存中的各个部分如代码缓存区,Eden区,Survivor区,老年代,持久代等的回收处理情况。
3.2使用jstat 检查垃圾回收器工作状态
jstat -gcutil 123456 2000 1000
-gcutil 告知jstat监控垃圾回收器工作状态;
123456用于表示ES所在的JVM;
2000 表示抽样间隔,单位是毫秒;
1000 表示抽样数;
以上例子执行耗时为 33 分钟(2000*1000/1000/60)
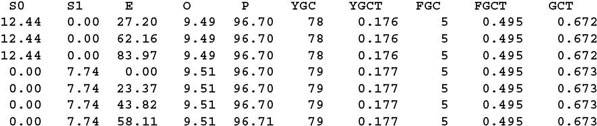
·S0:表示survivor 0区的使用率,用百分比表示。
·S1:表示survivor 1区的使用率,用百分比表示。
·E:表示Eden区的使用率,用百分比表示。
·O:表示年老代的使用率,用百分比表示。
·YGC:表示年轻代垃圾回收事件的次数。
·YGCT:表示年轻代垃圾回收耗时,单位为秒。
·FGC:表示年老代垃圾回收事件的次数。
·FGCT:表示年老代垃圾回收耗时,单位为秒。
·GCT:表示垃圾回收总耗时。
现在回到刚才的示例。如你所见,在第三和第四次抽样之间JVM对年轻代执行了一次垃圾回收,此次操作耗时0.001秒(第四次抽样的YGCT是0.177,第三次抽样的YGCT是0.176,两次YGCT之差为0.001)。同时我们可以看到,Eden区使用率从83.7%变为0%,而年老代使用率从9.49%上升为9.51%,这是因为此次操作中一些对象从Eden区迁移到了年老代。这个示例同时也展示了如何对jstat的输出进行分析。当然,分析工作比较费时,也需要你了解垃圾回收器是如何工作以及明白堆中都存放了什么。尽管如此,这可能是ElasticSearch故障时你能用的唯一方法。
如果你遇到以下情况,ElasticSearch运行不正常,或者S0、S1、E列的值达到100%,并且垃圾回收工作对这些堆空间不起作用,那么原因可能是:年轻代太小了,你需要把它调大一些(当然,前提是拥有足够的物理内存);内存出问题了,比如说因为一些资源没有释放占用的内存而导致内存泄露。还有一种情况,如果年老代使用率达到100%且垃圾回收器多次尝试仍无法释放它的空间,这大概意味着没有足够的堆空间让ElasticSearch节点正常运作了。此时,如果你不想改变索引结构,就只能通过增大运行ElasticSearch的JVM的堆空间来解决了(更多JVM参数信息请参考:http://www.oracle.com/technetwork/java/javase/tech/vmoptions-jsp-140102.html)。
1.3生成Memory Dump
JVM还拥有把堆空间转储到文件的能力。Java允许我们获取特定时间点的一个内存快照,并通过分析快照的存储内容,从而发现问题。你可以使用jmap命令(http://docs.oracle.com/javase/7/docs/technotes/tools/share/jmap.html)去转储Java进程的内存。Jmap命令示例如下:
jmap -dump:file=heap.dump 123456
123456表示需要转储的Java进程号。
-dump:file=heap.dump指定转储的目标文件为heap.dump。
我们可以通过一些特殊的软件进一步分析转储文件,如jhat(http://docs.oracle.com/javase/7/docs/technotes/tools/share/jhat.html)。
3.3垃圾回收器调优
然而,如果你想了解更多关于垃圾回收器的信息,如它有哪些选项以及这些选项如何作用到你的程序,建议阅读这篇伟大的文章:http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html。尽管该文章是关于Java 6的,但其中提及的绝大部分选项对Java 7应用同样适用。
谨记一件事:尽可能进行多次轻量级垃圾回收操作,而不是一次性、耗时很长的垃圾回收操作。因为保持ElasticSearch程序性能的稳定性是第一位的,对ElasticSearch来说,垃圾回收应该是透明的。一次重大的垃圾回收操作会停止全局的垃圾回收事件,在短时间内冻结ElasticSearch的工作,从而使查询变慢且短期无法执行索引操作。
1.4调整ElasticSearch中垃圾回收器的工作方式
我们已经知道了垃圾回收器如何工作,也明白了如何诊断垃圾回收过程中的故障,接下来可以探讨一下如何通过修改ElasticSearch启动参数来调整垃圾回收器的工作方式。参数的修改方式视ElasticSearch的运行方式而定,目前常见的有两种:
一种是使用ElasticSearch发行包自带的标准启动脚本,
另一种是使用服务包装器(service wrapper)。
1.4.1 使用标准启动脚本
为了添加额外的JVM参数,我们需要把它们加入JAVA_OPTS环境变量中。例如,要给Linux环境下的ElasticSearch添加-XX:+UseParNewGC -XX:+UseConcMarkSweepGC启动参数,需要执行如下命令:
export JAVA_OPTS="-XX:+UseParNewGC -XX:+UseConcMarkSweepGC"
执行如下命令以确定参数是否添加成功:
echo $JAVA_OPTS
在本例中,应该会有如下输出:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
1.4.2 使用服务包装器
可以使用Java服务包装器(https://github.com/ElasticSearch/ElasticSearch-servicew-rapper)把ElasticSearch包装成服务。这种给ElasticSearch添加启动参数的方法与使用标准启动脚本的方法不同。
我们所需要做的是修改elasticsearch.conf文件,该文件一般位于/opt/ElasticSearch/bin/service/目录下(如果ElasticSearch安装目录是/opt/ElasticSearch)。文件中包含了以下属性:
第一行负责设置ElasticSearch的堆空间大小,之后的其他行是附加JVM参数。如果需要添加其他参数,只需新增一行wrapper.java.additional,后面紧跟下一个可用数字,例如:
wrapper.java.additional.10=-server
垃圾回收调优并不是一件一劳永逸的事情。它需要反复试验,因为调优结果严重依赖于你的数据、查询和各种组合环境。在ElasticSearch出故障的时候要勇于改变和调优,在做出改变后也要继续观察、监控ElasticSearch的运行状况。
总结
ES调整节点内存大小基本可以解决大部分问题