机器学习实战之朴素贝叶斯(三)示例:过滤垃圾邮件(含数据集)
朴素贝叶斯(三)示例:过滤垃圾邮件
- 流程
- 导入
- 收集数据:提供文本文件
- 准备数据:切分文本
-
- 使用split()切分
- 使用正则表达式切分
- 数据集介绍
- 训练算法:使用我们之前建立的trainNB0()函数
- 测试算法:进行交叉验证
转载请注明作者和出处:https://blog.csdn.net/weixin_45814668
微信公众号:qiongjian0427
知乎:https://www.zhihu.com/people/qiongjian0427
Github代码获取:https://github.com/qiongjian/Machine-learning/
Python版本: Python3.x
流程
(1)收集数据:提供文本文件。
(2)准备数据:将文本文件解析成词条向量。
(3)分析数据:检查词条确保解析的正确
(4)训练算法:使用我们之前建立的trainNB0()函数。
(5)测试算法:使用calssifyNB(),并且构建一个新的测试函数来计算文档集的错误率。
(6)使用算法:构建一个完整的程序对一组文档进行分类,将错分的文档输出。
导入
from numpy import *
import random
import math
import os
收集数据:提供文本文件
email 提取码:7pk8。点这里下载
准备数据:切分文本
先前的词向量是预先给定的,这次将介绍如何从文本文档中构建自己的词列表。
使用split()切分
对于一个文本字符串,可以使用Python的string.split()方法将其切分。
mySent='This book is the best book on Python or M.L. I have ever laid eyes upon.'
mySent.split()
结果:
['This','book','is','the','best','book','on','Python','or',
'M.L.','I','have', 'ever', 'laid','eyes','upon.']
可以切分出所有词,但是标点符号也被当成词的一部分。
使用正则表达式切分
import re
regEx = re.compile('\\W*')
listOfTokens = regEx.split(mySent)
listOfTokens
结果:
['This','book','is','the','best','book','on','Python','or',
'M','L','I', 'have','ever','laid','eyes','upon','']
可以切分出每个单词,不包括标点,但空字符串要去掉。
我们希望所有词的形式都是统一的,所以将字符串转换为小写(.lower())或者大写(.upper())。
[tok.lower() for tok in listOfTokens if len(tok) > 0]
结果:
['this','book', 'is', 'the', 'best', 'book', 'on', 'python', 'or', 'm', 'l', 'i', 'have', 'ever', 'laid', 'eyes', 'upon']
数据集介绍
数据集有50封邮件,其中垃圾邮件25封,正常邮件25封,垃圾邮件类别记为1,有用邮件类别记为0。
使用正则表达式来切分句子,去掉少于两个字符的字符串,并变成小写。
def textParse(bigString):
import re
listOfTokens =re.split(r'\W*',bigString)
return [tok.lower() for tok in listOfTokens if len(tok)>2]
之前的代码
#创建一个包含在所有文档中的不重复词的列表
def createVocabList(dataSet):
vocabSet = set([]) #创建一个空集
for document in dataSet:
vocabSet = vocabSet | set(document) # “ |”代表创建两个集合的并集
return list(vocabSet)
词袋模型:
def bagOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
训练算法:使用我们之前建立的trainNB0()函数
def trainNB0(trainMatrix,trainCategory):#输入参数为文档矩阵trainMatrix,和每篇文档类别标签所构成的向量trainCategory
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCategory)/float(numTrainDocs)
#p0Num = zeros(numWords); p1Num = zeros(numWords) #初始化概率
#p0Denom = 0.0; p1Denom = 0.0
p0Num = ones(numWords); p1Num = ones(numWords)
p0Denom = 2.0; p1Denom = 2.0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
#p1Vect = p1Num/p1Denom #change to log()
#p0Vect = p0Num/p0Denom #change to log()
p1Vect = log(p1Num/p1Denom)
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
测试算法:进行交叉验证
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1)
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) #2分类问题可以用1.0-pClass1,多分类需要修改
if p1 > p0:
return 1
else:
return 0
def spamTest():
#初始化数据列表
docList = []; classList = []; fullText = []
#spam和ham文件夹里的邮件是25封,所以用for循环25次
for i in range(1, 26):
#切分文本
wordList = textParse(open('email/spam/%d.txt' % i).read())
#切分后的文本以原始列表形式加入文档列表
docList.append(wordList)
#切分后的文本直接合并到词汇列表
fullText.extend(wordList)
#标签列表更新
classList.append(1)
wordList = textParse(open('email/ham/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
#创建一个包含所有文档中出现的不重复词的列表
vocabList = createVocabList(docList)
#初始化训练集和测试集列表
trainingSet = list(range(50)); testSet = []
#随机构建测试集,随机选取10个样本作为测试样本,并从训练样本中剔除
for i in range(10):
#randIndex=random.uniform(a,b)用于生成指定范围内的随机浮点数
randIndex = int(random.uniform(0, len(trainingSet)))
#将该样本加入测试集中
testSet.append(trainingSet[randIndex])
#同时将该样本从训练集中剔除
del(trainingSet[randIndex])
#初始化训练集数据列表和标签列表
trainMat = []; trainClasses = []
#遍历训练集
for docIndex in trainingSet:
#词表转换为向量,并加入到训练数据列表中
trainMat.append(bagOfWords2Vec(vocabList, docList[docIndex]))
#相应的标签也加入训练标签列表中
trainClasses.append(classList[docIndex])
#朴素贝叶斯分类器训练函数
p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses))
#初始化错误计数
errorCount = 0
#遍历测试集来测试
for docIndex in testSet:
#词表转换为向量
wordVector = setOfWords2Vec(vocabList, docList[docIndex])
#判断分类结果与原标签是否一致
if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]:
#如果不一致则错误计数加1
errorCount += 1
#并且输出出错的文档
print("classification error",docList[docIndex])
#打印输出信息
print('the erroe rate is: ', float(errorCount)/len(testSet))
#返回词汇表和全部单词列表
结果:
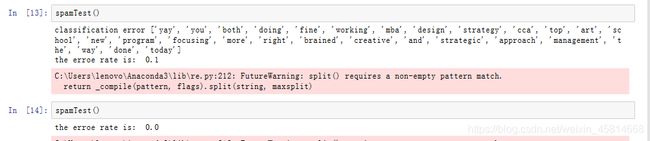
因为测试集是随机选取的,所以每次测试的结果可能不同。
可以多次运行测试函数求平均错误率,以此来评估算法。
我运行了20次,平均错误率是7%。
上面处理的邮件全英文的,中文邮件怎么处理呢?Python有中文处理模块 jieba(结巴)。
END
注:本人菜鸟一枚,如有不对的地方还请指正~