在 Solidity 中 ++i 为什么比 i++ 更省 Gas?
前言
作为一个初学者,“在 Solidity 中 ++i 为什么比 i++ 更省 Gas?” 这个问题始终在每个寂静的深夜困扰着我。也曾在网上搜索过相关问题,但没有得到根本性的解答。最终决定扒拉一下它们的字节码,从较为底层的层面看一下它们的差别究竟在哪里。
Solidity 代码选择
Solidity 版本选用了 0.8.4 (随手选的没啥说法),代码选用了两个简单的合约,分别是 Test(i++) 和 Test2(++i) ,两个合约都有一个全局变量 i ,修改值的时候从 storage 中取值然后进行修改。选择全局变量的这个形式是想要通过定位 SLOAD 和 SSTORE 两个比较有特征的操作码来进行比较。当然,这个只是我知识浅薄的脑瓜子想出来的一个代码形式,如果有更好的更直接明了的代码形式也十分欢迎各位师傅提出来交流交流。
Solidity Code:
pragma solidity 0.8.4;
contract Test{
uint256 i = 0;
// 0xfb5343f3
function t1() public {
i++;
}
}
contract Test2{
uint256 i = 0;
// 0xbaf2f868
function t2() public {
++i;
}
}
RuntimeCode 分析
Solidity 代码经过编译以后,截取两个合约的 RuntimeCode,注意是 RuntimeCode 而不是包括 CreationCode 的所有代码。否则在后面看地址转跳的时候会对不上号。
OK,拿到了字节码。我们简单地从长度比较上面就可以看出两个合约的字节码是不一样的,但是具体怎么不一样,不一样发生在什么地方,就需要进行进一步的分析。
Test Contract RuntimeCode:
6080604052348015600f57600080fd5b506004361060285760003560e01c8063fb5343f314602d575b600080fd5b60336035565b005b6000808154809291906045906056565b9190505550565b6000819050919050565b6000605f82604c565b91507fffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff821415608f57608e609a565b5b600182019050919050565b7f4e487b7100000000000000000000000000000000000000000000000000000000600052601160045260246000fdfea264697066735822122036565a2f31dfc56ec3a1576d52790574b00eea2721561ecdc6581a7c865a382564736f6c63430008040033
Test2 Contract RuntimeCode:
6080604052348015600f57600080fd5b506004361060285760003560e01c8063baf2f86814602d575b600080fd5b60336035565b005b60008081546041906054565b91905081905550565b6000819050919050565b6000605d82604a565b91507fffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff821415608d57608c6098565b5b600182019050919050565b7f4e487b7100000000000000000000000000000000000000000000000000000000600052601160045260246000fdfea2646970667358221220a395400661088056760f04d1c0d531d36c787fe81f654b35987819f5b3a4e36564736f6c63430008040033
Operation Code 分析
当然也不至于手撕字节码,所以下一步就是把字节码翻译成操作码(Operation Code)来分析。推荐去 dedaub(Bytecode Decompilation - Contract Library for the Ethereum and Fantom blockchains by Dedaub)上面反编译一下。由于OP Code太长,考虑到文章篇幅就不贴上来了,朋友们可以自己去操作一下。
但是!我根据 OP Code 做了两个图,去掉了一些不重要的结束分支,保留了主干。其中标有红蓝两种颜色的代码块表示此处出现不同的操作。其余没有标记颜色的代码块操作基本相同。(说基本相同是因为红蓝颜色代码块的长度不同,导致整体的地址发生了一些偏移。操作是一样的,只是跳转的地址相应地存在一点偏移。)而且刚刚好, SLOAD 和 SSTORE 两个操作码正好处于这两个不一样的代码块中,那说明 i++ 和 ++i 这两个操作在取值后和赋值前这两个地方会出现差异。
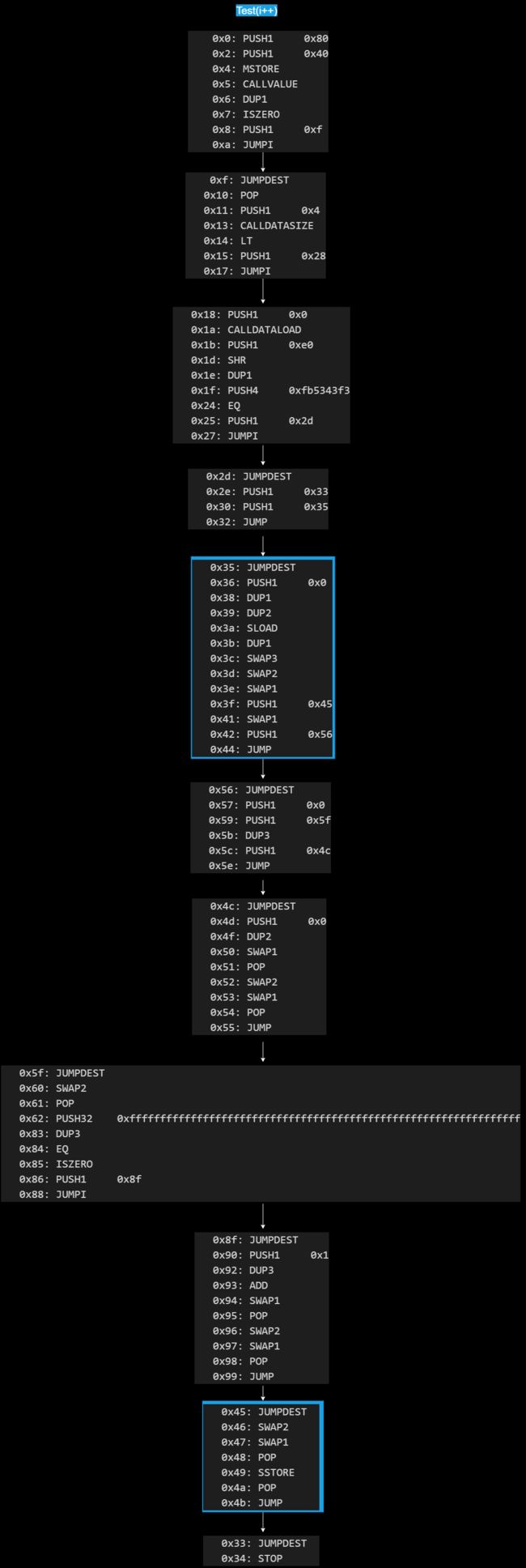
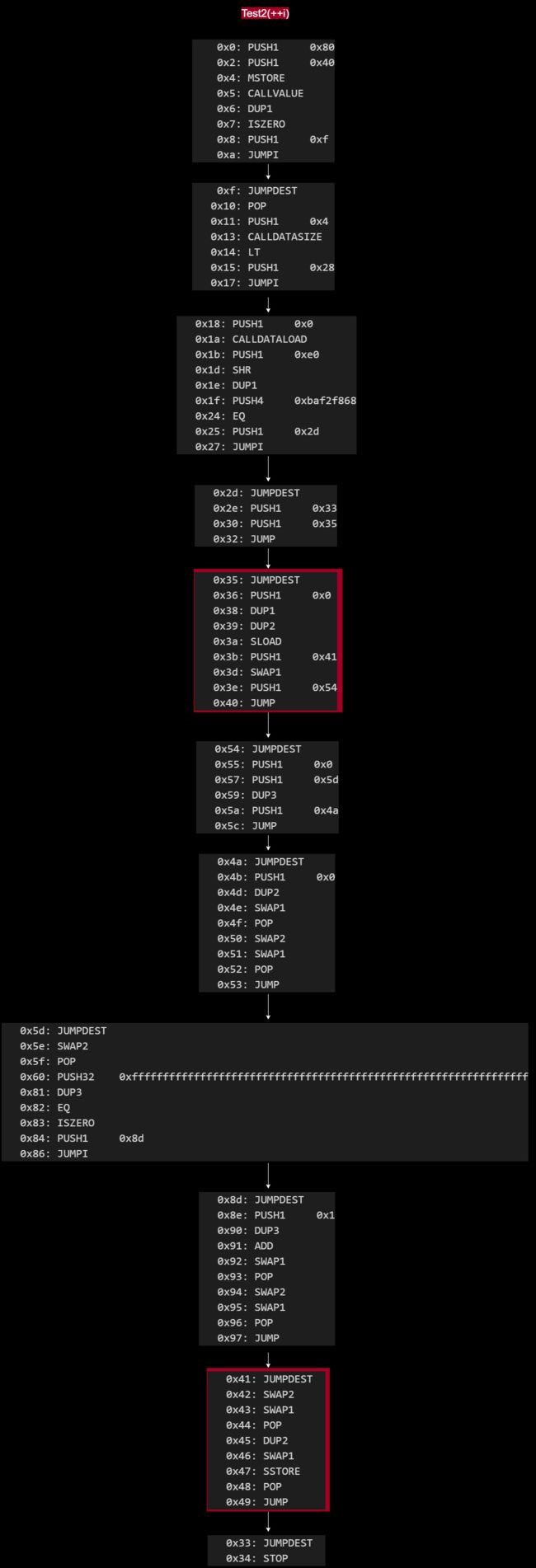
现在两个合约的不同点已经找出来了。接下来我们把标有颜色的代码块取出来,结合运行到此处时堆栈的变化,进行进一步的对比分析。
堆栈的分析工具可以用 evm.codes (EVM Codes - Playground),把字节码贴上去,配置好函数选择器就可以单步调试了。但是这里还有一个问题,就是用 remix 的 debug 调试的时候操作码的地址与反编译出来的地址对不上号,用 evm.codes 倒是完美对上。希望有头绪的师傅可以指点一下这到底是怎么回事。
接下来看对比图。为了更好地分析堆栈的变化,选择了当 i = 1 时的状态来进行 +1 操作对比。这是为了避免当 i = 0 时读取进来的 0 值不够显眼,容易与堆栈中的其他 0 值混淆。0x3a Stack 代表当代码运行完 0x3a 这个位置的操作码后,堆栈 Stack 中的情况。
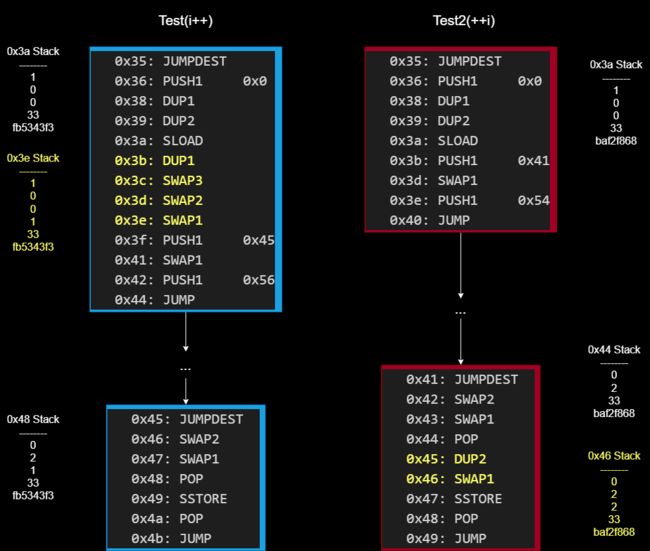
先看左边,当 i = 1 时,进行 i++ 操作。从左上角的代码块可以看出,0x3a 处的 SLOAD 指令从 solt 中取出 i 的值存放在堆栈顶。然后 0x3b 处的 DUP1 将栈顶 i 的值进行复制。随后的几个 SWAP 操作把复制出来的值交换到堆栈的第 4 位处。随后程序运行到左下的代码块中。当程序运行到 0x48 处时,此时栈顶的 0 为 i 的 slot 位置,堆栈第 2 位为 i++ 后的值,堆栈第 3 位是在 0x3b 处 i 进行 +1 操作前复制出来的 i 值。随后 0x49 处的 SSTORE 操作将 2 存放到 solt 0 中。
然后右边,当 i = 1 时,进行 ++i 操作。从右上角的代码块可以看出,0x3a 处的 SLOAD 指令从 solt 中取出 i 的值存放在堆栈顶。随后程序运行到左下的代码块中。当程序运行到 0x44 处,此时栈顶的 0 为 i 的 slot 位置,堆栈第 2 位为 i++ 后的值。随后 0x45 处的 DUP2 操作将堆栈第 2 位的 2 值复制并存放的栈顶。随后 0x46 的 SWAP1 操作将其堆栈 1, 2 位的值调换。此时堆栈的第 3 位是 i 进行 +1 后的值。0x47 处的 SSTORE 指令将 2 值存放到 solt 0 中。
上面的解释可能稍微有点绕,有简单版的。
简单的理解可以把 i++ 的操作类似于:
uint256 j = i;
i = i + 1;
// store 'i', keeep 'j'
因为我们可以通过堆栈中的情况看到,在执行完 0x3a: SLOAD 这个操作后,马上执行 0x3b: DUP1 对取出来的 i 值进行一个复制,就相当于 uint256 j = i;,而随后对 i 的值进行 +1 操作,并不影响复制出来 j 的值。当执行完 0x49: SSTORE 后,堆栈顶的 1 值就是 0x3b: DUP1 复制出来的 j。
而 ++i 的操作则类似于:
i = i + 1;
// store 'i', keep 'i' copy value
当代码运行到 0x44 处时,栈顶的 0 为 i 的 slot 位置,堆栈第 2 位为 i++ 后的值。然后 0x45: DUP2 对 i 值进行了复制,利用 0x46: SWAP1 调整完顺序以后执行 0x47: SSTORE 保存。此时,栈顶的 2 值就是 0x45: DUP2 复制出来的进行过 +1 操作后的 i值。
好!话说回来!
那么到底为什么在 Solidity 中 ++i 为什么比 i++ 更省 Gas 呢?我们看代码对比(比较图中的黄色代码)可以看出,当执行 i++ 的时候,要比 ++i 多执行一个 SWAP2 和一个 SWAP3,而每个 SWAP* 固定的消耗为 3 gas。
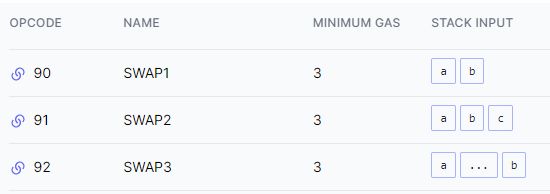
所以可以得出,以本文的案例 Test 合约与 Test2 合约为例,执行一遍 i++ 要比 ++i 多消耗 6 gas,如下图所示:


就是这样。