论文阅读--Exploiting Unsupervised Data for Emotion Recognition in Conversations
Exploiting Unsupervised Data for Emotion Recognition in Conversations
Wenxiang Jiao, Michael R. Lyu, Irwin King:
Exploiting Unsupervised Data for Emotion Recognition in Conversations. EMNLP (Findings) 2020: 4839-4846
Abstract
与句子级文本分类问题不同,ERC任务可用的监督数据有限,这有可能阻止模型发挥最大作用。在本文中,我们提出了一种更加可行的新颖的方法来利用无监督的对话数据。具体来说,我们提出了“Conversation Completion(ConvCom)”任务,该任务尝试从候选answer中选择正确的answer,以填充对话中被mask的话语。之后我们在ConvCom任务上预训练了一个上下文依赖的编码器(PRE-CODE)。最后我们在ERC数据集上微调PRE-CODE。
1 Introduction
对话的内在层次结构,即“词到话语”和“话语到对话”,决定了ERC任务可以通过上下文相关的模型来更好地进行处理。
尽管取得了显著的成功,但依赖上下文的模型受到了数据稀缺性问题的困扰。在ERC任务中,注释者需要识别情绪之间的明显差异或细微差别,并用特定的情绪标签标记实例,这使收集带有人工注释的监督数据非常昂贵。ERC的现有数据集 (Busso et al.,2008; Hsu and Ku, 2018; Zahiri and Choi, 2018;Zadeh et al., 2018)包含不充分的对话,这阻碍了上下文依赖模型发挥其最大效果。
在本文中,我们旨在通过利用无监督数据来解决ERC的数据不足问题。具体来说,我们基于无监督数据提出了Conversation Completion(ConvCom)任务,其尝试从候选answer中选择正确的answer,以填补对话中的被mask的话语。接着,我们在ConvCom任务上预训练了一个上下文依赖的编码器(PRE-CODE)。上下文相关编码器的层级结构使我们的工作不同于专注于通用句子编码器的方法。最后我们在5个ERC数据集上微调PRE-CODE。
本研究的贡献:
- 我们提出了conversation completion任务,让上下文相关的编码器从无监督会话数据中学习。
- 我们在ERC的数据集上微调了预训练的上下文相关编码器,并在基线之上实现了显着的性能提升。
2 Pre-training Strategy
2.1 Approach

- ConvCom Task.我们在对话中利用自监督信号来构建我们的预训练任务。给定对话 U = { u 1 , u 2 , . . . , u L } \mathcal{U}=\{u_1,u_2,...,u_L\} U={u1,u2,...,uL}, 掩住(mask)目标话语 u l u_l ul,对话序列变为 U ∖ u l = { ⋯ , u l − 1 , [ m a s k ] , u l + 1 , ⋯ } \mathcal{U}\setminus u_l=\{\cdots,u_{l-1},[mask],u_{l+1},\cdots\} U∖ul={⋯,ul−1,[mask],ul+1,⋯} ,以此来创建一个question, 并尝试从整个训练语料库中检索正确的话语 u l u_l ul。填充mask的选择涉及到无数可能的话语,这使得用softmax将任务制定为多标签分类任务是不可行的。相反,我们使用负采样将任务简化为响应选择任务,这是噪声对比估计 (NCE, Gutmannand Hyv ̈arinen, 2010)的一种变体。为此,我们取目标话语并在其他地方采样N-1个噪声话语,以形成一组有N个候选answers。那么目标就是根据上下文的话语,从候选中选择正确的answer,即 u l u_l ul 来填充mask。我们将此任务称作 “Conversation Completion”,简称 ConvCom。图2展示了一个例子,其中话语 u 4 u_4 u4 被从原本的对话中mask, 候选answers包括话语 u 4 u_4 u4 和两个噪声话语。
- Context-Dependent Encoder.上下文相关的编码器由两部分组成:一个话语编码器和一个对话编码器。每一个话语由一个单词向量序列 X = { x 1 , x 2 , . . . , x t } X=\{x_1,x_2,...,x_t\} X={x1,x2,...,xt}表示,这些词向量被初始化为预训练的300维的GloVe向量。
- 对于话语编码器,使用一个双向GRU来读取一个话语的单词向量并产生相应的隐藏状态 h ↔ t = [ h → t ; h ← t ] ∈ R 2 d u \overleftrightarrow{h}_t=[\overrightarrow{h}_t;\overleftarrow{h}_t]\in R^{2d_u} h t=[ht;ht]∈R2du。在所有单词的隐藏状态之上应用最大池化和平均池化。将池化的结果加起来,然后接上一个全连接层来获取话语 u l , l ∈ [ 1 , L ] u_l,l\in[1,L] ul,l∈[1,L] 的话语嵌入 :
h l = m a x ( { h ↔ t } t = 1 T + m e a n ( { h ↔ t } t = 1 T ) (1) h_l=max(\{\overleftrightarrow{h}_t\}_{t=1}^T+mean(\{\overleftrightarrow{h}_t\}_{t=1}^T)\tag{1} hl=max({h t}t=1T+mean({h t}t=1T)(1)
u l = t a n h ( W u ⋅ h l + b u ) , l ∈ [ 1 , L ] (2) u_l=tanh(W_u\cdot h_l+b_u),l\in[1,L]\tag{2} ul=tanh(Wu⋅hl+bu),l∈[1,L](2)
其中 T T T表示话语的长度, L L L表示对话中话语的数目。 - 对对话编码器,因为一个话语可能在不同的上下文中表达不同的意思,我们采用了另一个双向GRU来对对话中的话语序列进行建模以捕获话语之间的关系。产生的隐藏状态表示为 H → l ; H ← l ∈ R d c \overrightarrow{H}_l;\overleftarrow{H}_l\in R^{d_c} Hl;Hl∈Rdc
- 对于话语编码器,使用一个双向GRU来读取一个话语的单词向量并产生相应的隐藏状态 h ↔ t = [ h → t ; h ← t ] ∈ R 2 d u \overleftrightarrow{h}_t=[\overrightarrow{h}_t;\overleftarrow{h}_t]\in R^{2d_u} h t=[ht;ht]∈R2du。在所有单词的隐藏状态之上应用最大池化和平均池化。将池化的结果加起来,然后接上一个全连接层来获取话语 u l , l ∈ [ 1 , L ] u_l,l\in[1,L] ul,l∈[1,L] 的话语嵌入 :
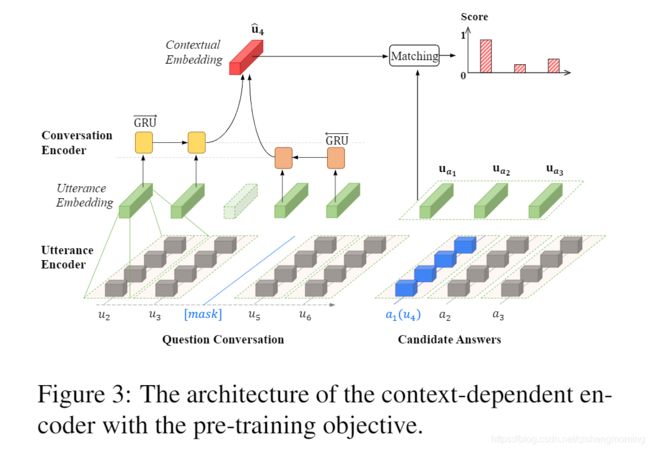
- Pre-training Objective.为了在所提出的ConvCom任务上训练上下文相关的编码器,我们通过结合被mask的话语的历史 H ← l − 1 \overleftarrow{H}_{l-1} Hl−1 和未来 H → l + 1 \overrightarrow{H}_{l+1} Hl+1 为每一个被mask的话语建立了一个上下文嵌入(见图3):
u ^ l = t a n h ( W c ⋅ [ H ← l − 1 ; H → l + 1 ] + b c ) (3) \hat{u}_l=tanh(W_c\cdot[\overleftarrow{H}_{l-1};\overrightarrow{H}_{l+1}]+b_c)\tag{3} u^l=tanh(Wc⋅[Hl−1;Hl+1]+bc)(3)
之后,上下文嵌入 u ^ l \hat{u}_l u^l 与候选answers进行匹配以找到最合适的一个来填充mask。为了计算匹配分数,我们采用了下列带有sigmoid函数的点积的方式:
s ( u ^ l , u a n ) = σ ( u ^ l T ⋅ u a n ) , n ∈ [ 1 , N ] (4) s(\hat{u}_l,u_{a_n})=\sigma(\hat{u}_l^T\cdot u_{a_n}),n\in[1,N]\tag{4} s(u^l,uan)=σ(u^lT⋅uan),n∈[1,N](4)
其中 u a n u_{a_n} uan 是第 n n n个候选answer的嵌入。目标是最大化目标话语的匹配分数,并最小化噪声话语的分数。因此损失函数为:
F = − ∑ l [ log σ ( u ^ l T ⋅ u a 1 ) + ∑ n = 2 N log σ ( − u ^ l T ⋅ u a n ) ] (5) \mathcal{F}=-\sum\limits_l[\log\sigma(\hat{u}_l^T\cdot u_{a_1})+\sum\limits_{n=2}^N\log\sigma(-\hat{u}_l^T\cdot u_{a_n})]\tag{5} F=−l∑[logσ(u^lT⋅ua1)+n=2∑Nlogσ(−u^lT⋅uan)](5)
其中 a 1 a_1 a1 对应于目标话语,并且求和操作遍历训练集中所有对话的每一个话语。
2.2 Experiment
- Dataset.我们使用的无监督对话数据来自开源数据库OpenSubtitle,其包含大量的电影和电视节目的字幕。具体来说,我们检索了2016年全年的英语字幕,并收集了25466个html文件。在预处理之后,我们的训练集,验证集和测试集分别包含58360, 3186, 3297个对话。
- Evaluation.评价指标:
R N ′ @ k = ∑ i = 1 k y i ∑ i = 1 N ′ y i (6) R_{N'}@k=\dfrac{\sum_{i=1}^ky_i}{\sum_{i=1}^{N'}y_i}\tag{6} RN′@k=∑i=1N′yi∑i=1kyi(6)
其为对于给定的上下文嵌入 u ^ k \hat{u}_k u^k,来自 N ′ N' N′个可用的候选的 k k k个最佳匹配中真正例的召回率。 y i y_i yi 表示每一个候选的二进制标签,即1表示目标话语,0表示噪声话语。此处我们报告 R 5 @ 1 , R 5 @ 2 , R 11 @ 1 , R 11 @ 2 R_5@1,R_5@2,R_{11}@1,R_{11}@2 R5@1,R5@2,R11@1,R11@2。

- Results.为简单起见,我们将上下文相关的编码器称为CODE。我们在三种不同容量(SMALL, MID, LARGE)的数据集上训练CODE.训练细节见附录A.2。
表1列出了在测试集上的结果。对于SMALL CODE,对于带有5个候选answers的实例,有78%的实例可以选择正确的answer;对于带有11个候选answers的的实例,有56.2%的实例可以选择正确的answer。准确率比随机选择高很多,随机选择的正确率分别是 1 5 , 1 11 \dfrac{1}{5},\dfrac{1}{11} 51,111。通过将模型的容量增加到MID和LARGE,我们又相继提高了几个百分点的召回率。这证明了CODE确实可以捕获对话的结构并在所提出的ConvCom任务中表现良好。
3 Fine-tuning Strategy
3.1 Experimental Setup
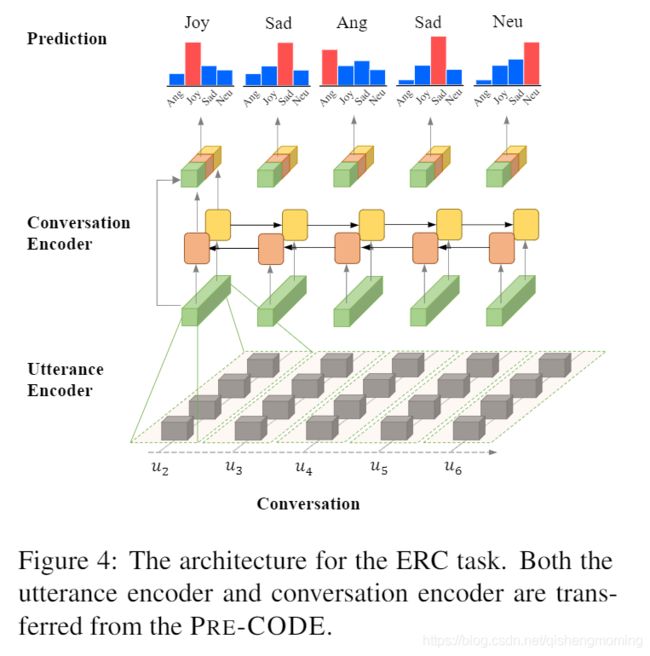
- ERC Architecture.为了将预训练的CODE模型(PRE-CODE)迁移到ERC任务上,仅仅需要添加一个全连接层(FC)然后跟上一个softmax函数来形成新的架构。图4展示了这个结构,在送入FC之前,我们还将上下文独立的话语嵌入与上下文相关的话语嵌入进行了连接。
我们采用了加权分类交叉熵来优化模型参数:
L = − 1 ∑ i = 1 N L i ∑ i = 1 N ∑ j = 1 L i ω ( c i ) ∑ c = 1 ∣ C ∣ o j c log 2 ( o ^ j c ) (7) \mathcal{L}=-\dfrac{1}{\sum_{i=1}^NL_i}\sum\limits_{i=1}^N\sum\limits_{j=1}^{L_i}\omega(c_i)\sum\limits_{c=1}^{|\mathcal{C}|}o_j^c\log_2(\hat{o}_j^c)\tag{7} L=−∑i=1NLi1i=1∑Nj=1∑Liω(ci)c=1∑∣C∣ojclog2(o^jc)(7)
其中 ∣ C ∣ |\mathcal{C}| ∣C∣ 表示情感类别的数量, o j o_j oj表示正确标签的one-hot向量, o ^ j \hat{o}_j o^j是softmax输出。权重 ω ( c i ) \omega(c_i) ω(ci)与在训练集中的类别 c c c的比率成反比,类别 c c c的power rate为0.5。 - Compared Methods.
- bcLSTM (Poria et al., 2017)
- bcGRU
- CMN (Hazarika et al., 2018b)
- SA-BiLSTM (Luoet al., 2018),
- CNN-DCNN (Khosla, 2018)
- SCNN (Zahiri and Choi, 2018)
- HiGRU (Jiao et al.,2019)
- CODE-MID without pre-training
- PRE-CODE-MID
- ERC Datasets.5个ERC数据集,细节见附录A.3。
- IEMOCAP (Busso et al., 2008)
- Friends (Hsu et al., 2018)
- EmotionPush (Hsu et al., 2018)
- EmoryNLP (Zahiri and Choi, 2018)
- MOSEI (Zadeh et al.,2018)
- Evaluation.报告所有情感类别的宏平均F1和加权精确度(WA)


- Results.我们在5个数据集上训练实现基线并微调PRE-CODE。每一个结果都是重复5次实验的平均值,训练细节见附录A.3。
我们在表2和表3中展示了主要的结果,本文的提出的PRE-CODE方法比基线高出至少2个百分点。我们还通过对PRE-CODE和CODE-MID的F1分数使用双向t检验来进行显着性检验。对于IEMOCAP,EmoryNLP, MOSEI∗, Friends,EmotionPush的P-values分别是 0.0107,0.0038, 0.0011, 0.0003, 0.0068。因此,IEMOCAP的结果在统计学上具有显着性水平,显着性水平为0.05,而其他四个数据集的显着性水平为0.01。它证明了将知识从无监督的对话数据转移到ERC任务的有效性。
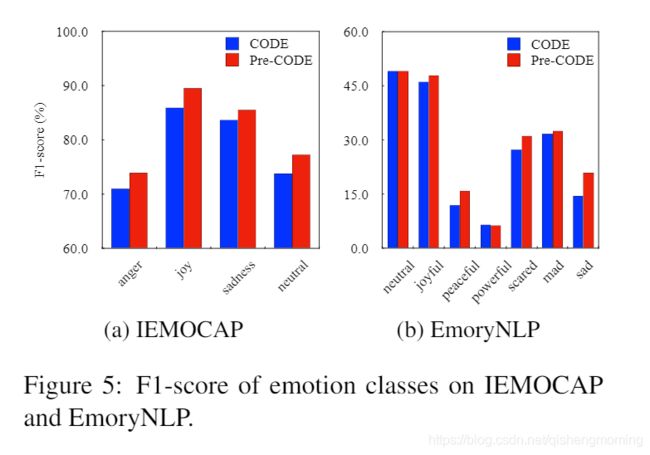
为了检查预训练对哪些方面的帮助最大,我们在图5中显示了IEMOCAP和EmoryNLP上每个情感类的F1得分。如图所示,我们的PRE-CODE特别的提高了占少数的情感类别的表现,如IEMOCAP中的anger和sadness,EmoryNLP中的peaceful和sad。这些结果表明,预训练可以缓解在占少数的类别上的表现不平衡的问题,同时可以维持在占多数的类别上的良好表现。
3.2 Discussion
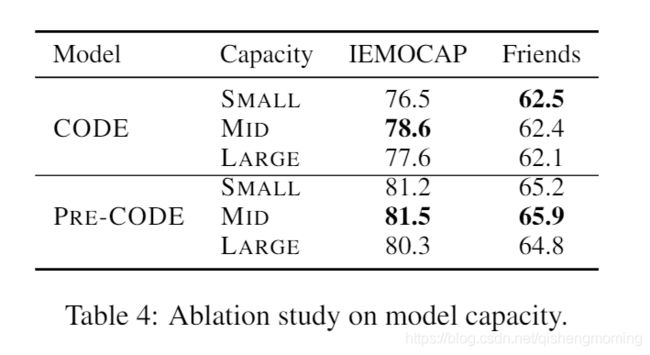
- Model Capacity.我们调查了模型性能如何受参数数量的影响,如表4所示。我们发现:
- 在所有的情形之下PRE-CODE的表现优于CODE,这表明不论ERC模型容量大小,预训练是提高ERC模型性能的有效方法。
- PRE-CODE在容量为SMALL和MID中的表现更好,我们推测ERC的数据集非常稀少,以至于无法将LARGE PRE-CODE的预训练参数转换为ERC的最佳参数。

- Layer Effect.我们研究了不同的预训练层如何影响模型性能,如表5所示。CODE+Pre-U 表示只有话语编码器的参数由PRE-CODE来初始化,我们的结论是,预先训练能更好地实现话语嵌入,并有助于模型更有效地捕捉话语层面的上下文。除此之外,PRE-CODE+Re-W表示我们将PRE-CODE重新多训练了10个epoch来调整原来固定的单词嵌入。结果表明,预训练词嵌入并不一定会提高模型的性能,但可能会破坏习得的话语和会话编码器。
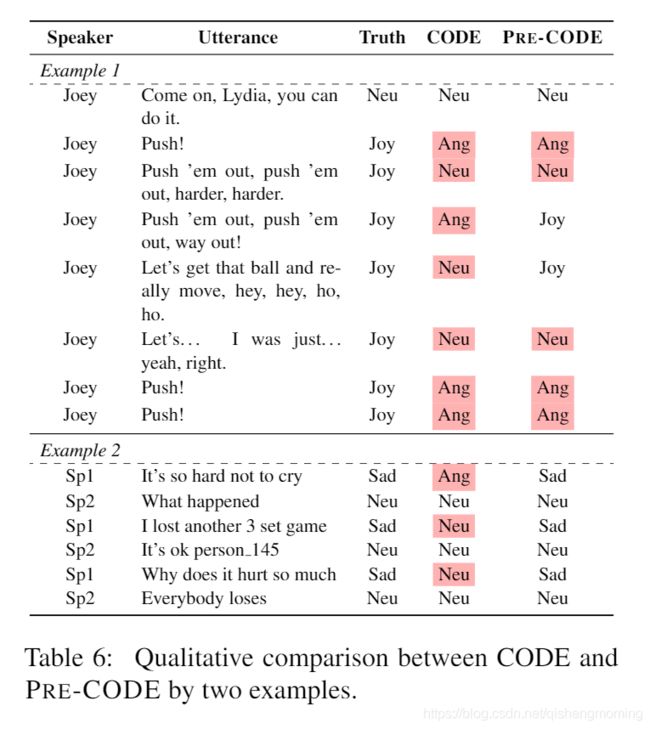
- Qualitative Study.在表6中,我们提供了CODE和PRE-CODE之间进行比较的两个例子。第一个例子是Frends中Joy连续说的几句话。它表明CODE倾向于识别带有感叹号的话语为angry,而带有句号的话语为中立。这个问题也出现在短话语的PRE-CODE中,如"Push!",其带有很少并且容易误导别人的信息。通过添加其他特征(如音频和视频)或许可以缓解此问题。尽管如此,PRE-CODE在较长的话语上比CODE表现得更好。另一个示例来自EmotionPush,它是几乎没有标点符号的消息。CODE模型预测几乎所有的话语都是Neutral的,这可能是因为大多数训练话语都是Neutral的。但是,PRE-CODE可以识别次要类别,如Sad,这证明预训练可以缓解类别失衡的问题。
4 Conclusion
在这项工作中,我们提出了一种新的方法来利用无监督会话数据来帮助ERC任务。本文提出的conversation completion任务对于上下文相关模型的预训练是有效的,并进一步微调以显著提高ERC的性能。未来的方向包括探索用于预训练的高级模型(例如TRANSFORMER),对无监督数据进行域匹配以及多任务学习以减轻迁移学习中可能出现的灾难性遗忘问题。
附录
A.1 Related Work
数十年来,对无监督数据的预训练一直是研究的活跃领域。Mikolovet al. (2013) and Pennington et al. (2014) 引导学习原始单词上的密集词嵌入,以进行下游任务。Melamud et al. (2016) 提出利用LSTM学习上下文中的词嵌入,以消除词义歧义。最近,ELMo(Peters等人,2018)通过语言模型提取了上下文相关的特征,并将这些特征集成到特定于任务的架构中,从而在几个主要的NLP任务上获得了最新的结果。与这些基于特征的方法不同,另一个趋势是通过语言模型目标对某些体系结构进行预训练,然后针对有监督的下游任务微调该体系结构 (Howardand Ruder, 2018; Radford et al., 2018; Devlin et al.,2019)。之前没有任何工作试图解决数据稀缺性的问题。另一方面,现有的迁移学习研究主要集中在预训练通用语句编码器,如ELMo、GPT和BERT。
但是我们的PRE-CODE超出了句子级别,专门用于对话或演讲中的句子序列。因此,需要对预训练任务进行定制,为此我们提出了ConvCom任务。部分受Word2vec(Mikolov等人,2013)和响应选择任务(Tong等人,2017)的启发,我们的ConvCom任务的不同之处在于,它对上下文顺序进行建模,同时提供历史和未来上下文。相反,Word2vec忽略了上下文词的顺序,并且响应选择通常仅提供历史上下文。
A.2 Pre-training Strategy

-
Dataset Creation.我们未标记的对话数据来自名为OpenSubtitle(Lison and Tiedemann 2016)的开源数据库,其中包含大量电影和电视节目的字幕。具体来说,我们检索2016年全年的英文字幕,包括25466个html文件。我们从所有html文件中提取文本字幕,并对其进行预处理,如下所示:
- 对于每个情节,删除前十个话语和最后十个话语,以防它们只是说明而不是对话,特别是在电视节目中;
- 按照均匀分布,将每一集中的对话随机分为含有5~100个话语的较短的对话
- 如果一个对话中有超过一半的话语单词数少于八个则将其删除。这样做是为了迫使对话捕获更多信息。
- 按照90:5:5的比例,将所有简短对话随机分到训练集,验证集和测试集中。
表7累出了数据集的统计信息,其中,#Conversation表示数据集中的会话数,Avg.#Utternace是每个对话的平均话语数,以及Avg.#Word是每个话语中token的平均数量。总的来说,有超过60K的对话数目,其中包含超过20万的话语,其不REC数据集大100多倍,见表8。
-
Noise Utterances.我们对训练集、验证集和测试集中的每个话语随机采样10个噪声话语。在每个集合中,一个对话共享从集合内其他地方采样的十个噪声话语。在训练过程中,我们既可以使用预先选择的噪声话语,也可以动态采样任意数量的噪声话语。我们使用验证集选择模型参数,并评估测试集上的模型性能。
-
Training Details.使用Adam优化器,初始学习率为 2 × 1 0 − 4 2\times10^-4 2×10−4,每当验证集的召回率 R 11 @ 1 R_{11}@1 R11@1停止增长时,以0.75的比率衰减。话语编码器和对话编码器的dropout比率为0.5.为防止梯度爆炸,采用了范数为5的梯度裁剪,训练集中的每一个话语被当作一个batch,每一个话语充当每一轮的目标话语。在训练过程中为每一个对话随机采样10个噪声话语,并在每个epoch都验证模型。CODE最多与训练20个epoch,并采用了patience为3的early stopping来选择最优的参数。注意,我们在预训练过程中固定单词嵌入,目的是为了专注于话语编码器和对话编码器。
A.3 Fine-tuning Strategy
- ERC Datasets.我们的PRE-CODE和实施的基准在五个ERC数据集上进行了微调,它们是,IEMOCAP,Friends,EmotionPush,EmoryNLP, MOSEI∗,,对于MOSEI,我们对其进行预处理以适应ERC任务,并在此将预处理后的数据集命名为MOSEI *。具体来说,我们使用了MOSEI的原始文本,其中超过14k的话语没有标注,而其他话语则被标注上了一种或多种情感标签。对于未标记的话语,我们只是将其从数据集中删除。对于具有一个以上情感标签的话语,我们通过多数票或最高情感强度总和(如果有多个多数票)确定其主要情感。对于所有情感类别获得零票的话语,我们将其标注为other。对于前三个数据集,我们遵循先前的工作(Poria et al., 2017; Hsu et al., 2018)仅考虑了四个情感类别,即anger,joy,sadness,neutral。对于EmoryNLP,我们考虑所有情感类别,正如(Zahiri and Choi,2018)那样,对于MOSEI∗考虑6个情感类别(neutral除外)。除了IEMOCAP,所有数据集都包含训练集,验证集和测试集。因此,我们遵循(Poria et al., 2017)使用前四节作为训练集,最后一节作为测试集。验证集是从随机洗牌的训练集中以80:20的比例提取的。统计信息见表8。
外)。 - Training Details.我们仍然选择Adam作为优化器,并针对基准调整学习率。一般来说,除了MOSEI∗使用学习率 5 × 1 0 − 5 5\times10^-5 5×10−5,学习率为 2 × 1 0 − 4 2\times10^-4 2×10−4对其他多有数据集最合适。对于PRE-CODE的微调,使用基线的学习率或基线的学习率的一半,并报告更好的结果。我们监视验证集上的平均宏F1并当其不再增加时衰减学习率。对于处理IEMOCAP之外的所有数据集,衰减率为0.75,early stopping 的patience 为6。因为IEMOCAP对话的数量更少,将衰减率和early stopping 的patience分别设置为0.95和10。