MindSpore图片分类之代码实现
1. 摘要
在前面两次的分享中,我们主要探讨了LeNet卷积神经网络,分析了卷积、池化、全连接这些操作运算的特点和用法,以及LeNet中每一层的计算和作用。在了解过该网络的原理后,那么本次我们将通过使用MindSpore工具实现MNIST数据集的分类。
2. 模型的构造
对于一个完整图片分类模型,通常有以下几个组成部分。
模型:假设一个样本图片信息是X(i),输出标签为Y,那么我们需要建立基于输入X(i)和输出标签Y的表达式,也就是模型(model)。模型输出的Y是对真实样本的预测或估计,我们通常会允许它们之间有误差。
模型训练:通过数据来寻找特定的模型参数值,使模型在数据上的误差尽可能小。这个过程叫作模型训练(model training)。下面我们介绍模型训练所涉及的3个要素。
训练数据:我们通常使用一系列的真实数据,例如多个图片的真实标签和它们包含的不同像素数组。我们希望在这个数据上面寻找模型参数来使模型的预测结果更接近真实标签。在机器学习术语里,该数据集被称为训练数据集(training data set)或训练集(training set),一个图片被称为一个样本(sample),其真实类别叫作标签(label),用来预测标签的因素叫作特征(feature)。特征用来表征样本的特点。
损失函数:在模型训练中,我们需要衡量预测类别与真实类别之间的误差。通常我们会选取一个非负数作为误差,且数值越小表示误差越小。
优化算法:当模型和损失函数形式较为简单时,最优解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
模型预测:模型训练完成后,我们将模型参数在优化算法停止时的值分别记录。注意,这里我们得到的并不一定是最小化损失函数的最优解,而是对最优解的一个近似。然后,我们就可以使用学出的图片分类模型来估算训练数据集以外任意一张图片所属的类别了。这里的估算也叫作模型预测、模型推断或模型测试。
3. MindSpore代码实现
我们将在下面代码是使用MindSpore深度学习框架实现的,下面逐步分析我们项目中所使用的数据、模型、损失函数、优化算法、模型验证。
3.1 数据集准备
MNIST数据集(Mixed National Institute of Standards and Technology database)是大型手写数字数据库,包含60000个示例的训练集以及10000个示例的测试集,每个样本图像的宽高为28*28的灰度图。
下面提供了两种数据集的使用方式:
(1)数据集已经在同级文件夹目录下时,可执行下段代码解压使用。
def unzipfile(gzip_path):
"""unzip dataset file
Args:
gzip_path: dataset file path
"""
open_file = open(gzip_path.replace('.gz',''), 'wb')
gz_file = gzip.GzipFile(gzip_path)
open_file.write(gz_file.read())
gz_file.close()
(2)文件夹中还没有数据集的时候,需要下载使用。
def download_dataset():
"""Download the dataset from http://yann.lecun.com/exdb/mnist/."""
print("******Downloading the MNIST dataset******")
train_path = "./MNIST_Data/train/"
test_path = "./MNIST_Data/test/"
train_path_check = os.path.exists(train_path)
test_path_check = os.path.exists(test_path)
if train_path_check == False and test_path_check ==False:
os.makedirs(train_path)
os.makedirs(test_path)
train_url = {"http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz", "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz"}
test_url = {"http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz", "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz"}
for url in train_url:
url_parse = urlparse(url)
# split the file name from url
file_name = os.path.join(train_path,url_parse.path.split('/')[-1])
if not os.path.exists(file_name.replace('.gz','')):
file = urllib.request.urlretrieve(url, file_name)
unzipfile(file_name)
os.remove(file_name)
for url in test_url:
url_parse = urlparse(url)
# split the file name from url
file_name = os.path.join(test_path,url_parse.path.split('/')[-1])
if not os.path.exists(file_name.replace('.gz','')):
file = urllib.request.urlretrieve(url, file_name)
unzipfile(file_name)
os.remove(file_name)
3.2 数据增强
主要是对数据进行归一化和丰富数据样本数量。常见的数据增强方式包括裁剪、翻转、偏移变化等等。MindSpore通过调用map方法在图片上执行增强操作。
import mindspore.dataset as ds import mindspore.dataset.transforms.c_transforms as C import mindspore.dataset.transforms.vision.c_transforms as CV from mindspore.dataset.transforms.vision import Interfrom mindspore.common import dtype as mstype def create_dataset(data_path, batch_size=32, repeat_size=1, num_parallel_workers=1): """ create dataset for train or test Args: data_path: Data path batch_size: The number of data records in each group repeat_size: The number of replicated data records num_parallel_workers: The number of parallel workers """ # define dataset mnist_ds = ds.MnistDataset(data_path) # define operation parameters resize_height, resize_width = 32, 32 rescale = 1.0 / 255.0 shift = 0.0 rescale_nml = 1 / 0.3081 shift_nml = -1 * 0.1307 / 0.3081 # define map operations resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR) # resize images to (32, 32) rescale_nml_op = CV.Rescale(rescale_nml, shift_nml) # normalize images rescale_op = CV.Rescale(rescale, shift) # rescale images hwc2chw_op = CV.HWC2CHW() # change shape from (height, width, channel) to (channel, height, width) to fit network. type_cast_op = C.TypeCast(mstype.int32) # change data type of label to int32 to fit network # apply map operations on images mnist_ds = mnist_ds.map(input_columns="label", operations=type_cast_op, num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(input_columns="image", operations=resize_op, num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(input_columns="image", operations=rescale_op, num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(input_columns="image", operations=rescale_nml_op, num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(input_columns="image", operations=hwc2chw_op, num_parallel_workers=num_parallel_workers) # apply DatasetOps buffer_size = 10000 mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size) # 10000 as in LeNet train script mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True) mnist_ds = mnist_ds.repeat(repeat_size) return mnist_ds
3.3 模型构建
根据MNIST数据集的性质,这里我们使用图像分类任务的标准算法卷积神经网络-LeNet。卷积神经网络采用分层的结构对图片进行特征提取,由一系列的网络层堆叠而成,比如卷积层、池化层、激活层、全连接层、输出层,LeNet模型的详细结构可参考上篇MindSpore图片分类之LeNet网络池化和全连接。
import mindspore.nn as nn from mindspore.common.initializer import Normalclass LeNet5(nn.Cell): """ Lenet network structure """ #define the operator required def __init__(self, num_class=10, num_channel=1): super(LeNet5, self).__init__() self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid') self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid') self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02)) self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02)) self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02)) self.relu = nn.ReLU() self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) self.flatten = nn.Flatten() #use the preceding operators to construct networks def construct(self, x): x = self.max_pool2d(self.relu(self.conv1(x))) x = self.max_pool2d(self.relu(self.conv2(x))) x = self.flatten(x) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) x = self.fc3(x) return x
3.4 定义损失函数
模型在项目中的职责是拟合数据的规则特性,拟合的程度我们引入损失函数表示,接下来需要定义损失函数(Loss)。损失函数是深度学习的训练目标,也叫目标函数,可以理解为神经网络的输出(Logits)和标签(Labels)之间的距离,是一个标量数据。
本次模型输出是⼀个图像类别这样的离散值。对于这样的离散值预测问题,我们可以使⽤诸如softmax回归在内的分类模型。和线性回归不同,softmax回归的输出单元从⼀个变成了多个,且引⼊了softmax运算 使输出更适合离散值的预测和训练。
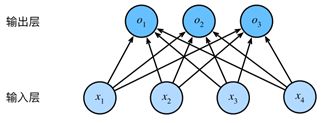
图1:softmax全连接运算图
o1 = x1w11 + x2w21 + x3w31 + x4w41 + b1,
o2 = x1w12 + x2w22 + x3w32 + x4w42 + b2,
o3 = x1w13 + x2w23 + x3w33 + x4w43 + b3.
既然分类问题需要得到离散的预测输出,⼀个简单的办法是将输出值oi当作预测类别是i的置信 度,并将值最⼤的输出所对应的类作为预测输出,即输出argmaxioi。然而,直接使⽤输出层的输出有两个问题。⼀⽅⾯,由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。另⼀⽅⾯,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
softmax运算符(softmax operator)解决了以上两个问题。它通过下式将输出值变换成值为正且 和为1的概率分布:
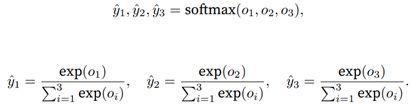
图2:softmax运算符计算图
容易看出yˆ1 + ˆy2 + ˆy3 = 1且0 ≤ yˆ1, yˆ2, yˆ3 ≤ 1,因此yˆ1, yˆ2, yˆ3是⼀个合法的概率分布。这时候,如 果yˆ2 = 0.8,不管yˆ1和yˆ3的值是多少,softmax运算不改变预测类别输出。
使⽤softmax运算后可以更⽅便地与离散标签计算误差。我们已经知道,softmax运算 将输出变换成⼀个合法的类别预测分布。
实际上,真实标签也可以⽤类别分布表达:对于样本i,我们构造向量y (i) ∈ R q ,使其第y (i)(样本i类别的离散数值)个元素为1,其余为0。这样我们的 训练⽬标可以设为使预测概率分布yˆ(i)尽可能接近真实的标签概率分布y(i)。
我们可以像线性回归那样使⽤平⽅损失函数∥yˆ(i) − y (i)∥ 2/2。然而,想要预测分类结果正确,我们其实并不需要预测概率完全等于标签概率。我们只需要其中的一个预测值足够大,就足够我们分类使用。例如我们预测一个数字图片类别为“1”的预测值为0.6,预测为“7”和“9”的值为0.2,或者预测为“7”和的值为0.35,预测为“9”的值为0.05,两种情况下分类都是正确的,但是计算的损失值是不同的。改善上述问题的⼀个⽅法是使⽤更适合衡量两个概率分布差异的测量函数。其中,交叉熵(cross entropy)是⼀个常⽤的衡量⽅法。图像分类应用通常采用交叉熵损失(CrossEntropy)。

图3:交叉熵损失函数表达式
其中带下标的y(i)j是向量y(i)中⾮0即1的元素,需要注意将它与样本i类别的离散数值,即不带下标的y(i)区分。在上式中,我们知道向量y (i)中只有第y(i)个元素y(i) y(i)为1,其余全为0,于是H(y (i) , yˆ (i) ) = − log yˆ(i) y(i)。也就是说,交叉熵只关⼼对正确类别的预测概率,因为只要其值⾜ 够⼤,就可以确保分类结果正确。当然,遇到⼀个样本有多个标签时,例如图像⾥含有不⽌⼀个物体时,我们并不能做这⼀步简化。但即便对于这种情况,交叉熵同样只关⼼对图像中出现的物体类别的预测概率。假设训练数据集的样本数为n,交叉熵损失函数定义为

图4:简化交叉熵损失表达式
从另⼀个⻆度来看,最小化交叉熵损失函数等价于最⼤化训练数据集所有标签类别的联合预测概率。
from mindspore.nn.loss import SoftmaxCrossEntropyWithLogits if __name__ == "__main__": ... #define the loss function net_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean') ...
3.5 定义优化器
损失函数的定义方便了样本的输出与标签之间误差的计算,也就是损失值,但仅仅是计算出了损失值是不够的,到这里模型还是一个“死”的,我们需要通过减小损失值的形式优化模型参数,优化器用于神经网络求解(训练)。由于神经网络参数规模庞大,无法直接求解,因而深度学习中采用随机梯度下降算法(SGD)及其改进算法进行求解。MindSpore封装了常见的优化器,如SGD、ADAM、Momemtum等等。本例采用Momentum优化器,通常需要设定两个参数,动量(moment)和权重衰减项(weight decay)。
本次体验项目中使用的是动量法。目标函数有关自变量的梯度代表了目标函数在自变量当前位置下降最快方向。因此,梯度下降也叫最陡下降。每次迭代中,梯度下降根据自变量当前位置,沿着当前位置的梯度更新自变量。然而,如果自变量的迭代方向仅仅取决于自变量当前位置,这可能会带来一些问题。
例如我们使用一个输入和输出分别为二维向量x=[x1,x2]⊤和标量的⽬标函数。
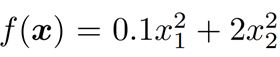
图5:二维目标函数
基于这个目标函数的梯度下降,演示使用学习率为0.4时自变量的迭代轨迹。

图6:目标函数自变量迭代轨迹
可以看到,目标函数在竖直方向比在水平方向的斜率的绝对值更大。因此给定学习率,梯度下降迭代自变量时会使自变量在竖直方向比在水平方向移动幅度更大。那么,我们需要一个较小的学习率从而避免自变量在竖直方向上越过目标函数最优解。然而这样也会造成自变量在水平方向上朝最优解移动变慢。
动量法的提出就是解决梯度下降中的上述问题的。设置时间步t的自变量为Xt,随机梯度为gt,学习率为ηt。动量法创建速度变量v0,并将其元素初始化成0。在 时间步t > 0,动量法对每次迭代的步骤做如下修改:
vt ← γvt−1 + ηtgt
xt ← xt−1 − vt
其中,动量超参数γ满⾜0≤γ<1。当γ=0时,动量法等价于梯度下降。
if __name__ == "__main__": ... #learning rate setting lr = 0.01 momentum = 0.9 #create the network network = LeNet5() #define the optimizer net_opt = nn.Momentum(network.trainable_params(), lr, momentum) ...
3.6 训练网络
配置模型保存:在上述几步机制设置完成后,便可以开始训练网络了。MindSpore提供了callback机制,可以在训练过程中执行自定义逻辑,这里使用框架提供的ModelCheckpoint为例。 ModelCheckpoint可以保存网络模型和参数,以便进行后续的fine-tuning(微调)操作。
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig if __name__ == "__main__": ... # set parameters of check point config_ck = CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10) # apply parameters of check point ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", config=config_ck) ...
配置训练网络
通过MindSpore提供的model.train接口可以方便地进行网络的训练。LossMoniter可以监控训练过程中loss值的变化。 这里把epoch_size设置为1,对数据集进行1个迭代的训练。
from mindspore.nn.metrics
import Accuracyfrom mindspore.train.callback
import LossMonitorfrom mindspore.train import Model
...def train_net(args, model, epoch_size, mnist_path, repeat_size, ckpoint_cb, sink_mode):
"""define the training method"""
print("============== Starting Training ==============")
#load training dataset
ds_train = create_dataset(os.path.join(mnist_path, "train"), 32, repeat_size)
model.train(epoch_size, ds_train, callbacks=[ckpoint_cb, LossMonitor()], dataset_sink_mode=sink_mode)
...
if __name__ == "__main__":
...
epoch_size = 1
mnist_path = "./MNIST_Data"
repeat_size = 1
model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()})
train_net(args, model, epoch_size, mnist_path, repeat_size, ckpoint_cb, dataset_sink_mode)
...

......................
图7:模型训练loss值变化图
如上图中所示,我们在配置完成模型、损失函数、优化器后,启动模型训练后的loss值变化情况。经过我们设定次数的迭代后,此时的loss值已经非常小,表示经验误差很小,但并不表示模型的泛化误差会很小,所以需要保存模型参数,检验模型的泛化误差,也叫验证模型。
3.7 验证模型
在得到模型文件后,通过模型运行测试数据集得到的结果,验证模型的泛化能力。使用model.eval接口读入测试数据集。使用保存后的模型参数进行推理。使用准确率检测模型的泛化性能。
from mindspore.train.serialization import load_checkpoint, load_param_into_net
...def test_net(args,network,model,mnist_path):
"""define the evaluation method"""
print("============== Starting Testing ==============")
#load the saved model for evaluation
param_dict = load_checkpoint("checkpoint_lenet-1_1875.ckpt")
#load parameter to the network
load_param_into_net(network, param_dict)
#load testing dataset
ds_eval = create_dataset(os.path.join(mnist_path, "test"))
acc = model.eval(ds_eval, dataset_sink_mode=False)
print("============== Accuracy:{} ==============".format(acc))
if __name__ == "__main__":
...
test_net(args, network, model, mnist_path)
![]()
图8:模型预测准确率
模型验证时,首先将训练模型保存的参数文件传入,预测数据集喂给模型预测使用。本次训练得到的准确率为0.963...,表示泛化误差很小。证明模型并未有过拟合现象,模型的鲁棒性能很好。但每次训练得到的模型并不是完全一致的,所以验证模型时得到的准确率也不一定相同。超参数的的调整是否有效果,模型验证的结果是很直观的表示。
4. 总结
本次分享内容首先归纳通常机器学习项目的组成部分,由数据集、模型、损失函数、优化器、模型预测这几部分组成。并且在每一个部分中,又有很多不同的方法。例如卷积模型有LeNet和ResNet等等。我们的需要做的是从分析数据集特性开始,然后在每一个部分中选择合适的方法构建出一个完整的项目,使用数据集训练、预测,最终保存符合我们要求的模型。
以上是个人的一些总结,有不足和错误之处,还请多多留言指导。