LSTM的输入与输出
2020/02/07 -
今天重新开启代码的测试过程,发现对于LSTM的输入输出还是不够理解,所以这部分今天需要再把这部分内容弄一下。
2020/02/07 -
我觉得我重新编写这部分代码之后,反而这部分内容有些迷惑了。
对这部分内容的整体架构有些不理解。
我现在疑惑的一个地方就是,如果输入和输出的步长不相等怎么办?
我本来的时候是用dense的方式,后来看了一下好像不对,就是timedistributed这个东西,具体是不是要应用呢?我不是明白。
所以我这里得把这个东西给弄明白。
2020/02/07 -
今天明白的一个东西,就是timedistributed这个东西。有这个东西反而引发我对整个LSTM的思考。就是针对他的输入和输出问题。
2020/02/08 -
首先,关于LSTM的单个cell的具体内容,我就不展开了。
我要说明就是,他这个东西在实际应用中,或者说在我现在遇见的预测行为中是怎么使用的,他们是怎么实现预测的。
-
各种预测行为的图示
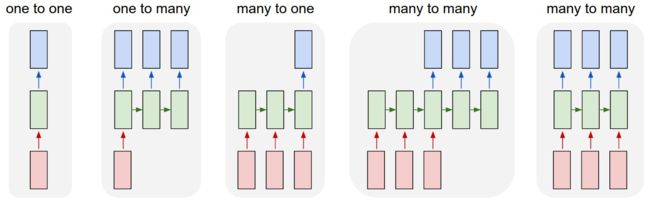 各种LSTM的模型
各种LSTM的模型
上面这个图的模型基本上算是涵盖了很多内容。
其中我一致使用的是mant-to-one的形式,因为我前段时间进行的预测行为都是预测最后的单个数值。这个是没有什么问题的。
这种many-to-one,在lstm的默认行为中是因为return_sequencs参数为false,那么最后拿出来的数据,只有最后一个步长的东西,所以我原来的时候,进行的实验都是没有问题的。但是最近做的实验,是预测后来的时间端内的数据,虽然数据维度上,通过最后的dense能够对上(完全是因为这是单维变量进行预测,如果多维的情况下是不能实现的)。
所以这里就明白了,如果你是要进行many-to-one的形式,这里的many和one 应该是指步长的内容。只需要使用默认的预测行为即可,最后通过dense来进行相关的实验。
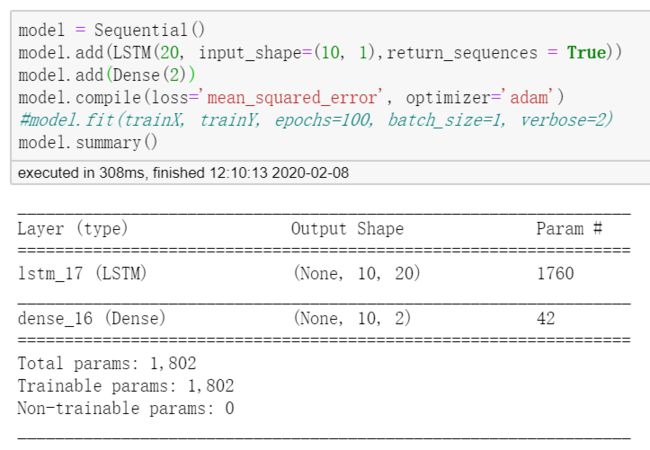
相关代码如下:
model = Sequential()
model.add(LSTM(20, input_shape=(10, 1),return_sequences = False))
model.add(Dense(2))
model.compile(loss='mean_squared_error', optimizer='adam')
#model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
model.summary()上述代码输出如下:

关于具体的参数个数这里不探讨,这里的关键行为是他最后的输出就是2维的,而且只是dense的参数个数。
前面的文章中,也提到过,每层的输出就是hidden_neutrons的维度(默认行为下)。
最后的dense层也是只对最后一个输出的步长的数值内容进行FC全连接层的运算。通过这个单元的个数就可以计算这个参数的个数是否正确20 * 2 + 2。
- many-to-many的形式
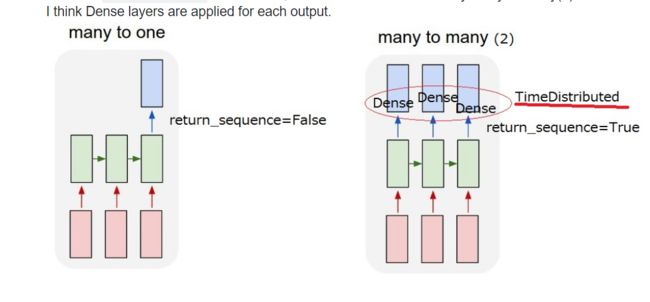
many-to-many的形式是两种,可以从图中看出(最后两个图),最后一个比较好理解,直接上代码。
model = Sequential()
model.add(LSTM(20, input_shape=(10, 1),return_sequences = True))
model.add(TimeDistributed(Dense(2)))
model.compile(loss='mean_squared_error', optimizer='adam')
#model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
model.summary()

可以看到这个输出已经变成三维了,多了一个步长的内容。
同时一定要注意到,这个东西输出的步长和输入的步长一定是一致的。这个是默认的行为。
因为到对最终输出的序列的每个步长都进行处理,所以需要利用这个timedistributed函数来进行处理,这个东西他会对这一层的每个步长都进行相同的权值计算,所以可以看出为什么这个东西最后一层的参数和上面的个数是一样的。
但是在学习这个东西的时候,我也发现了一个问题,那就是说,我直接使用了dense,不使用timedistributed函数的时候,也是得出了这样的参数个数。
这里其实就让我感觉到非常不对劲了?那么他这个形式是什么呢?
查找资料的时候发现了这个内容。

问答[1]把我上面总结的一些内容也给说明了(可以多次查看,内容还算清楚),但是没有直面回答问题,但是在他们的沟通中,解决了问题。意思就是,这个东西他们在这个场景下是一致的,但是如果你利用cnn这种形式,就必须使用timedistributed。
问答[2]更直接的说明了这个问题(这个后面可以再细看,因为他的解释角度不一样了又)。
问答[3]也说明了这个问题,下面是他使用的一个图片。
但是我今天看到了一个比较全面的对one-to-many和many-to-many形式的指导文章。(这里全面是指代码比较全面,还包括一些编码器的东西)。文章[4]。但是这里的一个原因就是说,他的这些形式,跟我理解的还不太一样。我个人更倾向于问答[5]给出的代码示例。虽然[4]的代码示例是正确的,从这个输入输出数据的维度上来匹配,但是感觉从意义上不对,可能这个就跟自己具体进行实验的时候,或者说你针对的问题相关了。
同时,对于不同长度的情况下,问答[5]中也给出了相应的示例。他应该是在最后的时候
参考
[1]timedistributeddense-vs-dense-in-keras-same-number-of-parameters/44616780#44616780
[2]what-is-the-role-of-timedistributed-layer-in-keras?rq=1
[3]how-to-use-return-sequences-option-and-timedistributed-layer-in-keras
[4]solving-sequence-problems-with-lstm-in-keras-part-2/