BP神经网络应用——数字验证码识别
摘要
神经网络从上世纪40年代被提出至今,得到了不断的补充和发展。后向传播学习的前馈型神经网络(BPNN)作为人工神经网络的一个经典模型,应用最为广泛。
验证码是网络上普遍采用的一种用于真人交互证明的有效方法,本文将采用BP神经网络来实现对验证码图像的识别。验证码的识别,大概分为图片预处理、分割字符、识别字符三个过程,其中分割字符最为困难。本文采用基于遗传算法和最大熵优化的图像分割技术、大津法(OTSU)、自定义阈值三种技术进行字符分割,并作进一步分析。利用英国萨里大学提供的印刷体数字数据集,共10160张图片,90%的数据用于训练BP神经网络,剩余10%的数据用于测试,最终识别准确率达到93.47%,利用训练所得BP模型完成识别字符。
本文基于MATLAB完成数字验证码识别的GUI设计,图像处理,验证码识别等功能,采用多种方法完成图像二值化,最终验证码图像识别效果较佳,具有一定的实用意义。
实现效果

本项目已经放在github上,如果觉得有帮助,可以star一下。地址:https://github.com/jienijieni2/Digital-verification-code-recognition
设计内容
本课题的设计内容主要包括三个部分,分别是BPNN模型构建、生成验证码、识别验证码。
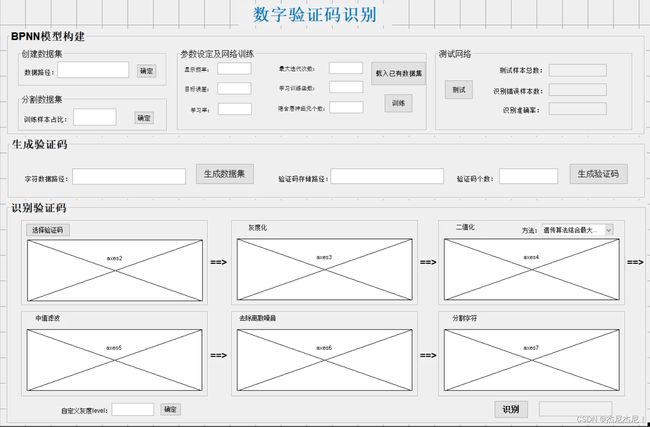
BPNN模型的构建就包括了:
一、数据集的创建与分割,即将图像数据转换为适合神经网络输入的数据,并按照比例分割为训练集和测试集;
二、神经网络的参数设定和训练,包括学习率、训练函数、最大迭代次数等的设定,用训练集训练神经网络;
三、测试神经网络,主要是用测试集数据测试网络的识别准确率。
生成验证码,主要是利用code_source文件夹下‘0-9’十类字符图片,将其转换为一维数据。随机抽取4张字符图片,并随机为之产生一种RGB色彩取值,将其组成一张验证码图片。接着为验证码图片添加噪声,包括椒盐噪声和离散斑点噪声。
识别验证码,分为图片预处理、分割字符、识别字符三个步骤。详细步骤见下文,重点在图像二值化中设计遗传算法,用于求解图像熵最大时的阈值。
具体实现
生成验证码
生成验证码,首先要将图像数据处理为一维数据,得到验证码字符数据集。利用code_source文件夹下‘0-9’十类字符图片,每类10张,合计100张图片,将每张图片进行二值化处理,并转换为一维数据。buildCodeSet()函数完成创建验证码字符数据集的工作。
接着利用创建好的数据集,随机抽取4个字符数据,将其转换为二维形式并拼凑,随机为之产生一种RGB色彩取值,将其组成一张验证码图片。然后在非字符数据区域随机产生离散斑点噪声,程序中设定为4像素大小。最后利用imnoise()函数,以0.02的噪声密度,为图片添加椒盐噪声。getCode()函数完成验证码的生成工作。所得验证码如图所示:

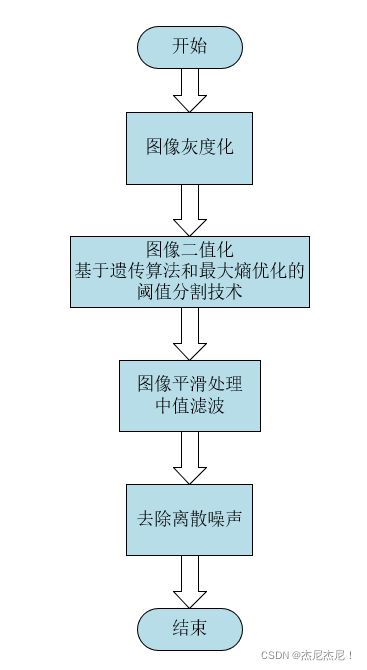
图片预处理
本文对图片进行预处理的流程主要分为四个步骤,首先对图像进行灰度化,转换为灰度图。接着对图像进行二值化,采用的是阈值分割技术,利用遗传算法和最大熵寻找阈值的最优解。然后对二值化的图像进行平滑处理,在尽量保留图像细节特征的情况下,对噪声进行抑制。最后,删去图像中连通域小于指定像素值的小对象,去除离散噪声。预处理的流程图如图所示:
-
图像灰度化
基于文本的验证码通常为会将背景、文本设置为多种色彩,对人眼有一定的干扰效果,但是对于计算机而言,色彩对图像识别算法影响不大,因此先将图像灰度化,有利于减少计算量。彩色图像一般为RGB模型,各种色彩都可以由红绿蓝三原色叠加产生,当R=G=B时,则图像转变为灰度图,三者相等的值称为灰度值Gray。图像灰度化主要有三种方法:
1.最大值法:即取R、G、B三者中最大者作为灰度值,图像亮度较高。
Gray=max(R,G,B)
2.平均值法:即取R、G、B三者的平均值作为灰度值,灰度较为柔和。
Gray=(R+G+B)/3
3.加权平均值法:通过调整R、G、B三者的权重,计算平均值作为灰度值。MATLAB中rgb2gray()函数即采用该方法.
Gray=0.299*R+0.587*G+0.114*B灰度化效果:

-
二值化
图像二值化就是将灰度图处理为黑白图,通过设定阈值,当像素点灰度值大于阈值时,变为白色像素,反之则变为黑色像素。白色逻辑值表示为1,黑色表示为0。通常二值化之后需要做一次反转,将目标部分转变为白色,逻辑值为1,便于计算处理。
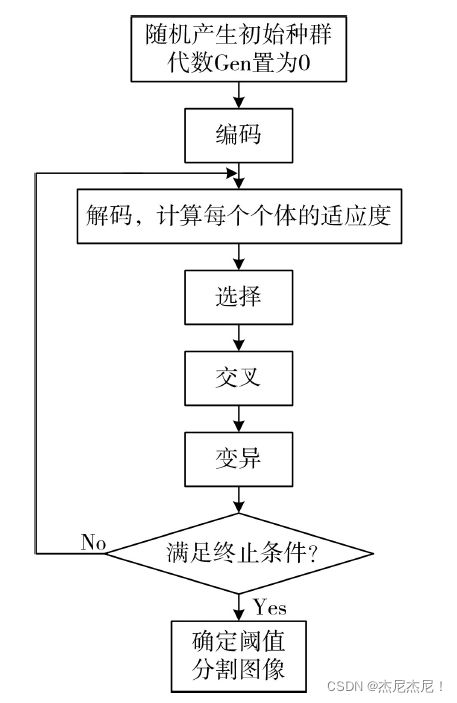
在二值化处理中,关键难点在于如何选定阈值。阈值选定的好坏直接影响二值化后的效果,目前阈值分割的方法很多,如:基于最大熵的阈值分割、最大类间方差法、基于直方图阈值分割法等。本文采用基于遗传算法和最大熵优化结合的方法选取较佳阈值,最大熵可以充分利用图像的空间信息和灰度分布,但是算法复杂度高,计算量大,而遗传算法寻优具有并行性、自适应性,结合两者的优势,图像分割更加精确,计算速度较快。
最大熵阈值分割通过分析每一灰度值的熵值,熵值最大的灰度值即为所求的分割阈值。灰度值取值范围[0,255],通过图像灰度直方图,求得每一灰度值出现的概率,记为Pi,图像的总熵值H为:

定义阈值为k时,
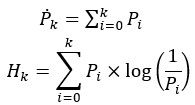
则阈值为k时,熵值H(k)为,
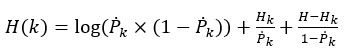
由上述可见,最大熵阈值分割方法计算量很大,而遗传算法恰好可以解决这一缺点,遗传算法正是通过模拟自然界中生物的遗传进化过程,对优化问题的最优解进行搜索。本文将灰度值通过二进制编码的方式构造为染色体,以熵值函数H(k)计算个体适应度,通过选择、交叉、变异的方式,在种群不断迭代的过程中,寻找适应度最佳的染色体,即为最佳分割阈值。本文选择操作采用轮盘赌算法,交叉方式采用单点交叉,变异概率前期设定为0.02,中期为0.03,后期为0.02。算法流程如图所示:
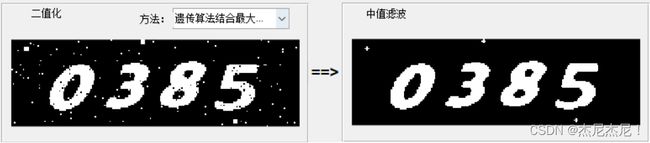
遗传算法改进的最大熵阈值分割技术二值化处理(经过反转)效果:

大津法(OTSU)是一种确定图像二值化分割阈值的算法,又称最大类间方差法。其基本原理是按图像的灰度特性,将图像分成背景和前景两部分,两者的类间方差越大,说明构成图像的两部分的差别越大,因此该方法所求阈值的错分概率最小。使用graythresh()函数可以求得该阈值。
Otsu方法二值化处理(经过反转)效果:

对于特殊图像,若上述方法二值化效果皆不佳,一种方法是通过自定义阈值水平不断调整尝试。自定义阈值水平取值范围为0到1之间,取值0.9时意味着将255×0.9所得的229.5作为灰度阈值,将图像一分为二。
自定义阈值level为0.9时二值化处理(经过反转)效果:

-
图像平滑处理
验证码中通常都会存在大量噪声来防止程序识别,通常采用图像滤波来抑制噪声。中值滤波是一种典型的非线性滤波,是基于排序统计理论的一种能够有效抑制噪声的非线性信号处理技术,基本思想是是将像素点的灰度值修改为邻域灰度值的中值,从而消除椒盐噪声,该方法的优点是可以在消除椒盐噪声的同时保留图像的边缘细节。
图像平滑处理的效果:
-
去除离散噪声
对于验证码图片中的字符,通常是连通的,因此分割字符的一种方法是通过识别连通域。但是验证码图片中还可能存在小面积的像素块,他们是连通的,这对连通域分割字符将造成非常严重的干扰,故需要消除离散噪声,进一步降低噪声干扰。连通域的识别是由连通性的定义决定,通常与4连通和8连通,如图:
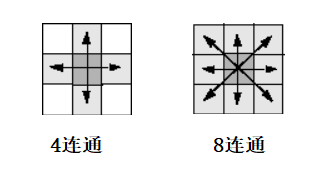
二维图像通常设定为8连通,可以通过删除图片中连通域面积小于指定数值的像素块,来去除离散噪声。去除离散噪声后效果:

分割字符
连通域分割的方法是基于连通域理论和连通域搜索算法,在MATLAB中提供了函数bwlabel()函数对二维二值图像的连通分量进行标注。根据函数标注出的标签,扫描图像即可确定分割出各个字符。该方法的优点是不受字符倾斜、扭曲变形等影响,但只能分割非粘连字符,本文所识别的验证码皆为非粘连数字验证码。采用该方法分割字符,分割效果:

识别字符
-
创建训练集与测试集
本文利用英国萨里大学提供的印刷体数字数据集,包括数字0~9各1016张图片,合计10160张图片。对于每类数字图片,取90%约915张作为训练数据集,取10%约101张作为测试数据集。部分数据集图片如图所示:

对于图像数据,需要进行预处理,转换为适合神经网络输入的数据格式,同时考虑到原数据集图片大小为128px×128px,且已为灰度图像,为了降低神经网络输入层神经元个数,应适当将图片缩放,按如下步骤处理:- 识别图中数字区域并分割;
- 进行图像二值化;
- 缩放至32px×32px;
- 将32行32列的图像矩阵转换为1行1024列的数据;
最终,得到训练数据集为9150行,1024列的矩阵,一行为一个训练样本数据,一列为一维特征值。同时,得到9150行,10列的训练样本标签集矩阵,一行对应一个训练样本,值为1的元素对应的列号即为该样本的标签分类。测试数据集为1010行,1024列的矩阵,测试样本标签为1010行,10列的矩阵。
-
训练神经网络
BP神经网络,即多层前馈式误差反相传播神经网络,是一种有监督的学习模型。其具有输入层、输出层、一层或多层隐层,层与层之间节点多采用全互连方式,同一层节点之间不相连,拓扑结构示意图如图:
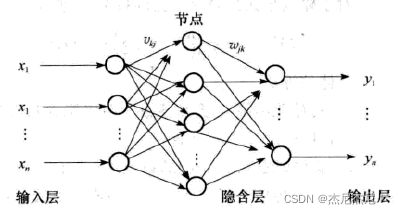
BP算法由两个过程构成:数据流的正向传播和误差信号的反向传播。 正向传播时,传播方向为输入层->隐层->输出层,若在输出层得不到期望的输出,则转向误差信号的反向传播过程。通过两个过程的交替进行,当误差小于预先给定的阈值时,算法终止。
本文所训练的BP神经网络结构如图:
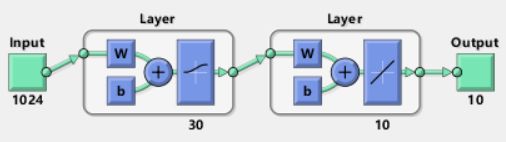
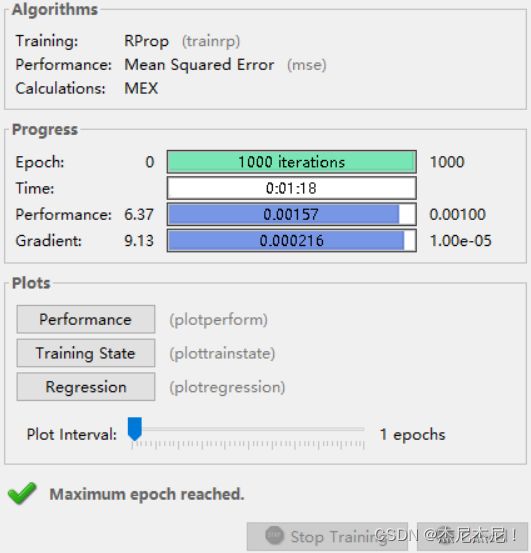
包含一个神经元节点数为1024的输入层,一个神经元节点数为30的隐含层及一个神经元节点数为10的输出层,最终输出字符对应各个分类的后验概率。BP神经网络的参数设定为:目标误差为0.001,最大迭代次数为1000,学习率为0.01,隐含层采用的激活函数是sigmoid函数,输出层采用的激活函数是purelin函数,学习训练函数为trainrp,采用RPROP(弹性BP)算法,对内存需求最小。如图,训练该神经网络耗时1分18秒,均方误差0.00157,非常小,网络性能较好。
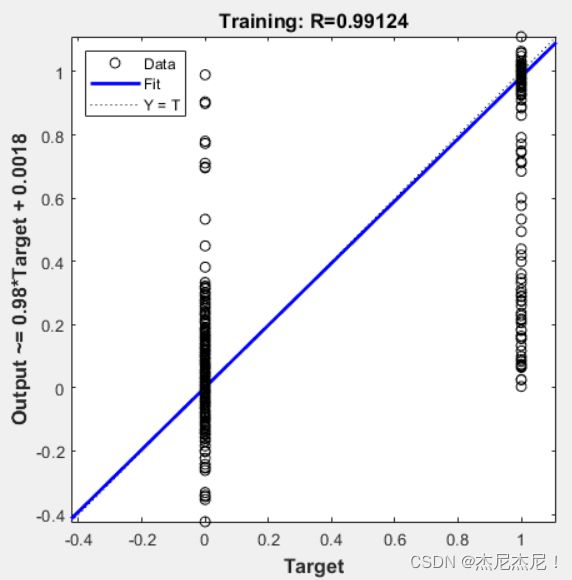
如图,训练所得网络在训练集上的数据拟合程度为0.99124,拟合程度越接近1,表示数据的拟合效果越好。
-
识别结果
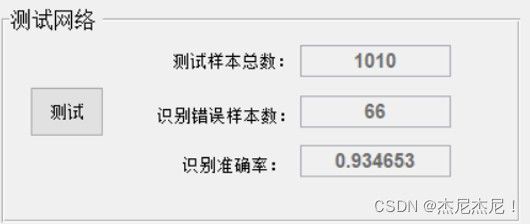
利用训练所得的BP神经网络模型,对测试集数据进行分类,如图,在1010个测试样本中,识别错误的仅66个,识别准确率达到93.47%,训练所得网络识别效果较好。
对于所分割的四个数字字符,也能够正确识别。

总结
本文对基于文本形式的验证码识别的图片预处理、分割字符、识别字符三个主要过程做了详细的分析,通过遗传算法结合最大熵的方法确定了图像二值化的最佳阈值,二值化效果良好,便于后续字符的分割与识别。在验证码识别这一应用领域上,关键难点在于字符的分割与识别。由于验证码种类繁多,目前的验证码识别应用往往只能识别一类验证码,不具有普遍性。本文所完成的验证码识别仅仅针对非粘连的数字验证码,应用领域受限。毫无疑问,粘连验证码的字符分割与识别将更为困难,本文尚未涉及该部分内容,这也是本文的不足之处。同时,目前深层次神经网络的发展前景非常好,若在训练数据足够多的情况下,可以采用目前热门的卷积神经网络来识别字符,可以更好地识别数字、字母的特征,识别效果将进一步改进。
参考文献
[1] 吕刚,郝平.基于神经网络的数字验证码识别研究[J].浙江工业大学报,2010,38(04):
433-436.
[2] 吕霁. 基于神经网络的验证码识别技术研究[D].华侨大学,2015.
[3] 田怀川. 基于神经网络的图形验证码识别及防识别的研究与应用[D].哈尔滨工业大学,2010.
[4] 王美华. 基于神经网络的特定目标检测与识别[D].重庆大学,2017.
[5] 王秋萍,张志祥,朱旭芳.图像分割方法综述[J].信息记录材料,2019,20(07):12-14.
[6] 余荣泉,段先华.基于最大熵和遗传算法的图像分割方法研究[J].计算机与数字工程,2019,47(07):1805-1809.
[7] 宋杨.图像识别处理中的遗传算法分析[J].信息与电脑(理论版),2019(12):38-39.
[8] 高炜. 字符型验证码的分割与识别技术研究[D].合肥工业大学,2013.
[9] Haralick, Robert M., and Linda G. Shapiro, Computer and Robot Vision, Volume I, Addison-Wesley, 1992, pp. 28-48.
注:遗传算法结合最大熵阈值进行二值化的代码非原创,参考网络资料。