VisionTransformer(二)—— 多头注意力-Multi-Head Attention及其实现
多头注意力-Multi-Head Attention及其实现
目录
多头注意力-Multi-Head Attention及其实现
前言
一、为什么要有Attention,注意力是什么?
二、Attention具体实现
三、Image中Attention的理解
三、Multi-Head Attention 多头注意力是什么
四、Multi-Head Attention 多头注意力实现
总结
前言
之前说到VIT中,个人觉得值得学习的地方有两处,一处是Patch Embedding即如何将image当成context处理。第二个就是今天要说的多头注意力-Multi-Head Attention。
VisionTransformer(一)—— Embedding Patched与Word embedding
在了解attention之前,请确保知道embedding Patch在做什么,因为其得到的Patch即为attention的输入。
这里的一些解释和想法来源与下面这篇文章:The Illustrated Transformer
虽说本文标题是多头注意力,但重点还是在讲解注意力机制,毕竟只要理解了注意力机制,多头注意力也不是什么难事了。
在了解VIT中的Attention在做什么,我觉得也有必要先直观的理解Attention是什么,到底在做什么。而Attention这个机制最早也是用于NLP领域,所以下面先以context为例再扩展到image上,而attention最开始也是用于机器翻译上,所以以机器翻译的角度去理解会比较好。
一、为什么要有Attention,注意力是什么?
直观的说,一个句子要想翻译的好,则必须要求考虑上下文的信息。
如:The animal didn't cross the street because it was too tired将其翻译成中文,这里面就涉及了it这个词的翻译,具体it是指代animal还是street就需要根据上下文来确定,所以现在问题就变成,如何让机器学习上下文,或者说对于机器来说什么是上下文。
这里引入特征工程里的一个叫做交互特征的方法(实质上,个人觉得attention就是一种在网络内部的特征工程)
有两个特征,分别为性别和收入,则这两个特征做交互特征(简单的说即两个特征相乘),则可以得到如:此数据为男人的状态下收入为多少的特征,则可以利用这个特征去分析性别对收入的影响,相对于同时考虑了性别和收入的关系。
那么借鉴这个思想,相对于引入一个相乘的交互关系就可以去表示上下文信息了。而Attention在本质上用一句话概括就是:带权重的相乘求和。
在Attention中,假如我们要翻译it这个词,这时候it这个词称为query(Q)待查询。查询什么呢,查询句子中的其他单词包括自己(这里其他的单词包括自己称为(keys(K)),这里的查询操作相对于上文说的相乘,而在Attention中用的是点乘操作。如果还记得Attention的输入是Patch embedding的结果,即是一个个N维空间的向量,即Q和K代表的内容都为N维空间的向量,那么点乘即可以表示这两个向量的相似程度——Q*K = |Q||K|cosθ,即可得到下图。

颜色越深表示与其点乘得到的结果越大(这里是学习后的结果),it和animal的相似度比较大,而后was和because这种无关的词相似度就较低了。
Q和K相乘后可以得到一个代表词和词之间相似度的概念,这里记为S。如果我们对这个S取softmax,是不是相对于就得到了当前要查询的Q,到底对应哪个词的概率比较大的概率,这里记为P。
而Attention就是对P做权重加和的结果,而为什么还要对P做权重(这个权重也是可学习的)加和呢,其实我觉得这才是Attention的精髓,因为每个权重即代表了网络对于哪个概率对应下的内容更加注意,对于哪些内容不需要注意,使网络可以更加关注与需要注意的东西,其他无关的东西,通过这个权重,相对于舍弃了。而我们记这个权重为V。
至此,我们就得到了我们的attention,网络的注意力。
二、Attention具体实现
根据上面的内容可以得出,应该对attention有个大致的了解了。
但我上面没有说Q,K,V这三个东西是怎么来的,Q,K,V实际上是由我上篇文章也即对context或者image做embedded 得到的Patch和Wq,Wk,Wv三个需要学习的矩阵相乘映射得来,所以算上这一步,整个Attention可以分为四步:
- 由embedded得到的Patch和需要学习的Wq,Wk,Wv矩阵相乘得到Q,K,V
- 由Q和K计算出来相似度S
- 由S经过Softmax计算出代表候选词概率P(在Scaled Dot-Product Attention中,计算Softmax之前,将S除以了一个系数)
- 对P进行权重加和得到attention
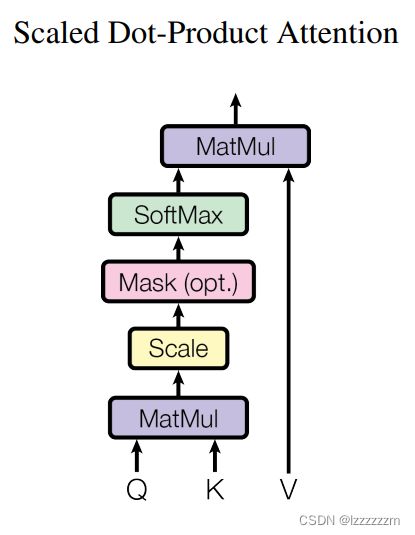
结合作者的图,就更好理解了。
三、Image中Attention的理解
我们知道了context中的attention实质上是解决context中的上下文信息,即对于一个长序列来说,其是否可以在看到后文时,仍记得前文的信息。
那么对于image来说,我们将image分成了一个个的块,attention则可以认为,当我们需要翻译(识别)一只狗时,其是否可以注意到哪些块(Patch)是与这只狗有关的,哪些是无关的。
与上面类似,如果it和animals计算出占比较大,那么在图片中,与狗有关的patch则也会计算较大的权重,如果做一个mask在原图上,则可以得到下面这张图。

三、Multi-Head Attention 多头注意力是什么
其实如果懂得了attention是什么,那么多头注意力就比较简单了。
我们把单头的注意力当成,一个人去决策it到底属不属于animals。那么多头就相对于是有多个人同时去决策it到底属于animals,street还是其他什么的。而最后的结果也应该由这多个人的结果取权重求和决定。
所以在实现上多头注意实际上就是在单头的基础上增添num_heads个维度,且在最后输出attention时增加一个权重矩阵就好了。
可以看出多头注意力增强了网络的稳定性和鲁棒性。
四、Multi-Head Attention 多头注意力实现
整个attention的实现,照上面说的四步,加上多头注意力最后的权重求和,五步即可解决。
而第一步和第二步其实可以通过一个矩阵解决。

代码中还要一些细节就是论文里提到的了,不过多说了。
class Attention(nn.Module):
def __init__(self,
embed_dim,
num_heads,
scalar):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = int(embed_dim / num_heads)
self.all_head_dim = self.head_dim * num_heads
print(self.all_head_dim)
self.scalar = scalar
# 将qkv三个矩阵写到一起
self.qkv = nn.Linear(in_features=embed_dim,
out_features=self.all_head_dim*3,
bias=False
)
self.Softmax = nn.Softmax(-1)
self.proj = nn.Linear(in_features=self.all_head_dim,
out_features=embed_dim,
bias=False)
def transpose_multi_head(self, x):
# x [B, N, all_head_dim]*3
new_shape = x.shape[:-1] + (self.num_heads, self.head_dim)
x = x.reshape(new_shape)
# X [B, N, num_heads, head_dim]
x = x.transpose(1,2)
return x
def forward(self, x):
# X: [Batchsize, Patchszize, embed_dim]
B, N, _ = x.shape
qkv = torch.chunk(self.qkv(x), 3, 2)
# qkv: [Batchsize, Patchsize, all_head_dim]*3
q, k, v = map(self.transpose_multi_head, qkv)
# q, k, v: [Batchsize, num_head, Patchsize, head_dim]
attn = torch.matmul(q, k.transpose(2, 3)) / self.scalar
# attn: [Batchsize, num_head, Patchsize, Patchsize]
attn = self.Softmax(attn)
attn = torch.matmul(attn, v)
# attn: [Batchsize, num_head, Patchsize, head_dim]
attn = attn.transpose(1, 2)
# attn: [Batchsize, Patchsize, num_head, head_dim]
attn = attn.reshape([B, N, -1])
# attn: [Batchsize, Patchsize, num_head*head_dim]
attn = self.proj(attn)
return attn总结
整篇文章里的一些概念,为了讲的通俗易懂一点,有些概念并不准确,但我个人认为只要理解attention在做什么,就像只要了解卷积在做什么就够了。使用时其实也就可以帮他当作nn.conv2d一样,用在网络里。