情感计算——多模态情感识别
一、 背景和意义
1. 情感是通过多种模态的形式进行表达的
情感涉及主观经历、生理反应和行为反应;
每个人都有自己的主观感受,身体会出现一系列的生理反应,并且通过表情、言语和肢体动作等行为方式表示情感;
多模态情感识别就是通过这些生理反应和行为反应(即多模态信息)来识别和预测情感。
2. 情感是通过多种模态的形式进行表达的
人们在高兴时说话节奏欢快,表现在说话的音调和语速上,同时面部会微笑,眯眼,此时语音和表情同时表达出高兴的情感状态;
当一个人难过时,往往不会怎么说话,情感识别难以单靠语音单模态信息,难过体现在表情上往往伴随着面部嘴角下垂、皱眉等。
3. 多模态情感识别
情感识别分析语音信号、视觉信号和生理信号来识别人的情感状态,利用多通道情感信息之间的互补性来提高情感识别的准确率。
4. 单模态情感识别鲁棒性不足、识别率不高
当人类主观上对情感信号加以掩饰或者单一通道的情感信号受到其它信号的影响时,情感识别性能将会明显下降,如面部表情容易被遮挡、语音容易受噪声干扰
二、 研究现状与进展
1. 1997 年,Duc 等人最先提出“多模态”(Multi-modal)的概念,通过基于贝叶斯理论的统计方法进行分析识别;
2. 2001-2006 年,Ross 等出版了《Handbook of Multibiometrics》,进一步阐述多模态识别理论,自动计算并分析多源信息,综合各类信息决策最终结果;
3. 麦格克效应揭示了大脑在进行感知时,不同感官会被无意识地自动结合在一起对信息进行处理,任何感官信息的缺乏或不准确,都将导致大脑对外界信息的理解产生偏差;
4. Mello采用统计学方法比较了单模态和多模态的准确性,实验结果表明多模态表情识别要优于单模态识别的性能。
5. 国外主要研究单位
麻省理工学院(media lab):Synthetic intelligence laboratory 团队基于脑科学探索多模态情感
卡内基梅隆大学(在AI,计算机,robot方面很强):MultiComp Lab 团队研究多模态情感分析
南洋理工大学:SenticNet Team 团队研究概念层面的情感分析
帝国理工大学:MultiMT 项目旨在探索多模态信息分享
自动化所;清华大学;西北工业大学;东南大学;中国人民大学;中科院心理所
三、 多模态情感识别数据库
1. 多模态离散情感数据库
AFEW (EmotiW 竞赛数据库):英文离散多模态情感数据库,从电影电视片段中截取;依托ICMI这个国际会议;
CHEAVD (MEC(多模态情感挑战赛)竞赛比赛数据):中文离散多模态情感数据库(从电影、电视和访谈片段中截图);自动化所做的;
2. 连续多模态情感数据库
RECOLA (AVEC 2015):自然状态下录制的交互对话场景,针对一个具体问题进行讨论,包括音频、视频和生理信号;识别得到情感的维度的表示用的VAD模型;
SEWA (AVEC 2017):自然状态下录制的交互对话场景,每次对话的两位录制者先观看一段
商业广告然后自由发言做出评价,包括音频、视频和文本信号;依托ACM下的多媒体会议(multi media)
四、多模态情感融合方法
1. 融合哪些模态?前期融合,后期融合?特征层融合,决策层融合,模型层融合?
2. 特征层融合

每个模态都有一个向量,都提取出来,形成超大维的矢量;
特征层融合往往会面临着特征维数过大问题,故需采取一定的措施对融合后的特征进行降维,避免冗余甚至引发“维数灾难”;
主成分分析方法是一种典型的降维方法,根据各类特征对情感识别的重要性进行筛选,去除冗余信息;降维是在统计上进行新的近似;
3. 基于主成分分析的特征层融合
把给定的一组相关变量通过某种线性变换转变成另一种不相关的变量;
通过选取方差较大的少数维特征用以替代原先的高维特征,最大限度的保留原有信息达到降维目的。

4. 基于多核融合学习的多模态特征融合
每个模态构建一个核,试图发现最优的融合多模态特征的方式;
核替换原来的特征参数;
把低维的数据映射到高维的特征空间(核空间),并通过核函数在核空间进行特征融合;
5. 先方式进行不同模态特征参数提取--最常用的深度神经网络方式
端到端的编码层: 对输入参数层层抽象;输入信号的一种表示; 因此可以用该层输出作为信息元的特征参数;
MFCC--音频参数
HOG--人脸参数
任何信息经过特征参数提取都会丢失内容;
结果发现通过DL的方法,效果更好;
多模态特征表示包含联合表示和协同表示
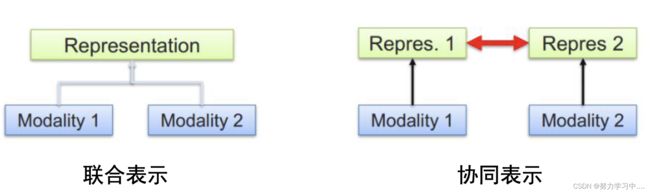
6. 多模态特征表示学习
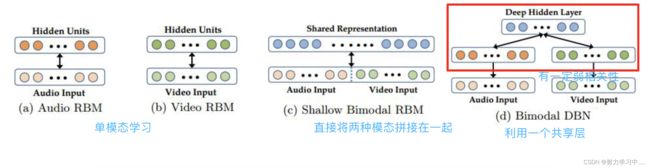
特征层融合:只是融合在一起,就是认为信息量变大了,但模态与模态相互关系没有考虑;
该融合方法利用不同模态相互之间的联系,但没考虑到各情感特征的差异性,同时该融合策略难以表示不同模态之间的时间同步性;(声音悲伤和表情悲伤可能不同步)
7. 决策层融合
决策层融合首先分别提取不同模态的特征,并将其送入各自的分类器中,再依据某种原则将各个分离器的结果进行融合决策,获得最终的识别结果;

表面上是模式识别,本质上是一个决策过程(控制方面)
相比于特征层融合,决策层融合对外界干扰具有很好的鲁棒性,在决策的过程中,对分类器权值进行优化匹配,具有较好的识别能力;
均值规则(加权平均);最大值规则;多数投票规则;线性加权;
分类器方法;贝叶斯推论;神经网络;最大熵模型。
优点:允许对各个模态的数据采用最适合的机器学习算法进行单独建模;决策层的融合较特征层融合更易进行,该方法充分考虑了不同模态特征的差异性,各个模态可以选择各自最合适的分类器进行分类;
缺点:不能充分利用不同模态特征所蕴含的类别信息;
8. 模型层融合
多流融合隐马尔可夫模型是一种通用的模型级模态融合手段;
来自每个模态的特征都能用一个组件隐马尔可夫模型建模,根据最大熵准则和最大互信息评价标准,这个组件隐马尔可夫模型与其它组件之间有最优的连接;
不同组件隐马尔可夫模型的状态转移不一定同时发生;
如果一个组件隐马尔可夫模型损坏了,其它组件仍能正常工作;相比于其它基于隐马尔可夫模型的融合方法,多流融合隐马尔可夫模型在复杂度和性能之间有更好的平衡。
五、 基于多模态融合的情感识别
1.子空间融合
基本假设:
虽然不同模态的原始数据不在同一空间中,但它们在高层语义的空间中拥有很强的相关性,因此可以把不同模态数据投影到同一个子空间中,之后进行子空间融合;
典型方法:
基于分布匹配的子空间融合;
基于相关性分析的子空间融合;
基于多模态共性与特性的子空间融合;
2. 细粒度融合
基本假设:
不同模态信息的表示粒度通常不同,这导致了从同一样本中抽取不同的模态特征具有不同的序列长度,传统方法将不同粒度特征在句子级别进行压缩对齐;
但近年来研究,将字词级别信息压缩为句子级别信息容易导致原始数据内部结构及时序关系受到破坏进而影响情感识别系统的性能;
近年来研究人员直接将细粒度特征作为输入信息,有效利用了细粒度信息之间的时序关系以及交互模式,实现了高效的多模态信息融合。
基于硬对齐的细粒度融合算法
利用强制对齐算法获取每个词的时间边界信息,然后计算不同模态信息在词级别的特征表示,将对齐后的结果用于多模态融合。

基于软对齐的细粒度融合算法
在模型内部实现异构特征融合
3. 模态缺失
实际场景中多种因素会导致数据缺失:
对于音频模态,视频中有时人物可能会保持静默状态;
对于文本模态,由于语音识别系统局限可能会出现模型不认识的字或词;
对于视频模态,视频中的人脸可能因为一些原因在一些时刻没有出现在摄像头范围内;
传感器(麦克风、摄像头等)出现故障时也会导致模态信息缺失。
4. 模态缺失解决方法:
基本假设:
由于原始的完整多模态数据是自然产生的,因此模态间因为共有信息的存在会有一致相关性,而且各模态内也存在着时序相关性。当出现部分模态某些或全部时刻的信息缺失后,这两种相关性就会遭到破坏,用线性代数中的语言描述就是,完整多模态数据的秩应该比缺失后的多模态数据的秩要小
解决方法:
在模型损失部分增加低秩正则项
特征抽取:多模态特征作为输入,分别经过各自的时序编码器后得到隐层特征。对于每一时刻,采用张量融合方法来整合不同模态的信息。将不同时刻多模态融合特征之和作为整个句子的特征;
模型训练:低秩正则项作用于该句子级别的特征,使其能够通过这一约束迫使网络利用模态间的一致相关性和模态内的时序相关性来恢复那些缺失的部分模态信息;
缺失数据补全:利用模态内的时序信息和模态间的共有信息来恢复出缺失时刻的模态信息。
六、总结
1. 多模态信息对于鲁棒的情感识别具有十分重要的作用;
2. 目前研究较多主要集中在音频、视频和文本三个模态;
3. 不同的多模态融合方法的效果不同,主要包括特征层融合、决策层融合和模型层融合;
4. 决策层融合是目前采用比较多的方法,效果也较好。
5. 随着深度学习的发展,基于神经网络的模型层融合取得了较好的效果。
参考: 国科大-情感计算课件