Twins: Revisiting the Design of Spatial Attention inVision Transformers解读
文章:https://arxiv.org/abs/2104.13840
代码:GitHub - Meituan-AutoML/Twins: Two simple and effective designs of vision transformer, which is on par with the Swin transformerTwo simple and effective designs of vision transformer, which is on par with the Swin transformer - GitHub - Meituan-AutoML/Twins: Two simple and effective designs of vision transformer, which is on par with the Swin transformer https://github.com/Meituan-AutoML/Twins
https://github.com/Meituan-AutoML/Twins
主要贡献:
1.Twins沿用PVT的整体架构,并且用CPVT中的PEG来替代PE,提出了Twins-PCPVT
2.提出Twins-SVT,将transformer block堆叠设计成global attention和local attention交替使用的形式,并且为了减少计算量,global attention将重要信息总结成m x n个表示,同时每个表示和其他sub-windows进行信息交流。sub-windows的设计借鉴了swin transformer.
Twins-PCPVT
作者认为PVT表现不好的原因是因为它采用了绝对位置编码。对于密集预测任务来说,位置编码需要根据不同尺寸的输入进行改变,因此绝对位置编码用于这样的任务。并且,绝对位置编码破坏了平移不变性(目标的外观发生了某种变化,但是你依然可以把它识别出来)。而swin用了相对位置编码,没有上面的问题自然效果比PVT好。那么PVT如果用了正确的位置编码,效果将会赶超swin。
于是这篇文章将CPVT中提出的条件位置编码(CPE)取代PVT中的位置编码。PEG(简单来说就是没有批归一化的2D深度卷积)产生CPE,把PEG模块放在每一个stage的第一个encoder。另外在最后一个stage用全局平均池化(GAP)代替了一般transformer用的class token。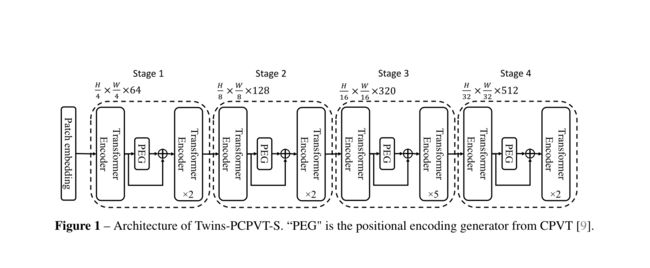
图1 PCPVT 的结构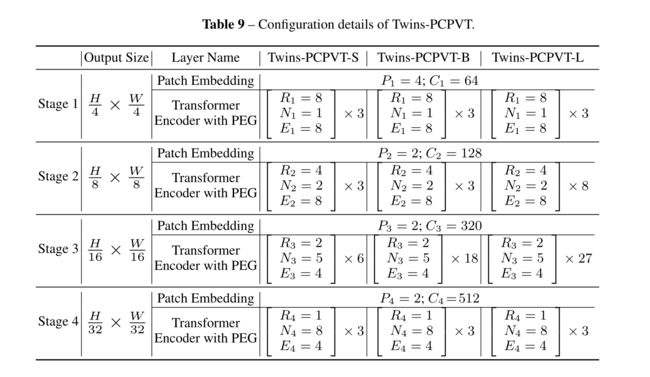
图2 PCPVT 具体配置
PEG代码:
class PosCNN(nn.Module):
def __init__(self, in_chans, embed_dim=768, s=1):
super(PosCNN, self).__init__()
self.proj = nn.Sequential(nn.Conv2d(in_chans, embed_dim, 3, s, 1, bias=True, groups=embed_dim))
self.s = s
def forward(self, x, H, W):
B, N, C = x.shape
feat_token = x
cnn_feat = feat_token.transpose(1, 2).view(B, C, H, W)
if self.s == 1:
x = self.proj(cnn_feat) + cnn_feat
else:
x = self.proj(cnn_feat)
x = x.flatten(2).transpose(1, 2)
return x
def no_weight_decay(self):
return ['proj.%d.weight' % i for i in range(4)]Twins-SVT
提出空间可分离自注意力(SSSA)。里面就是包括两个注意力:
① LSA,局部自注意力,捕获细粒度和短距离信息。
②GSA,全局自注意力,处理长距离和全局信息。
Locally-grouped self-attention (LSA)
将2D特征图划分为mxn个子窗口,每个子窗口大小H/m x W/n。自注意力只在子窗口里面做。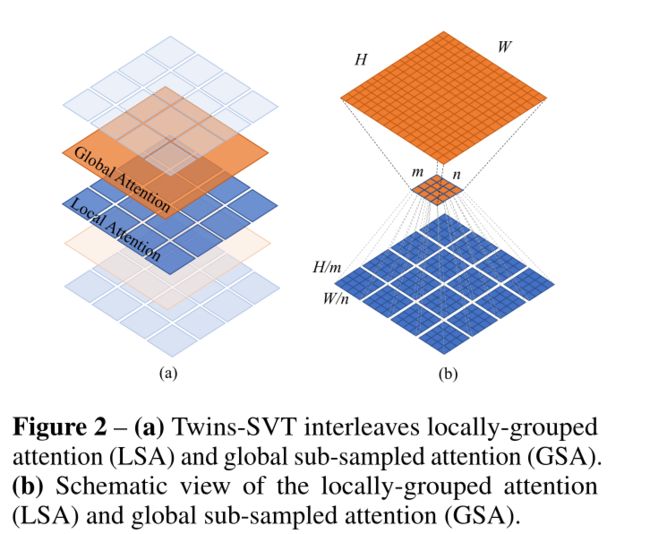
Global sub-sampled attention (GSA).
对于多头自注意力,有多少个头就有多少套mxn的子窗口。每套mxn子窗口选个代表作为key来与其他子窗口进行交互。下采样的话,用的是跨步卷积。
整个SSSA模块可以用下面公式表示,其中FFN就是前馈神经网络,做两次线性变换。

LSA代码:
class GroupAttention(nn.Module):
"""
LSA: self attention within a group
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., ws=1):
assert ws != 1
super(GroupAttention, self).__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.ws = ws
def forward(self, x, H, W):
B, N, C = x.shape
h_group, w_group = H // self.ws, W // self.ws
total_groups = h_group * w_group
x = x.reshape(B, h_group, self.ws, w_group, self.ws, C).transpose(2, 3)
qkv = self.qkv(x).reshape(B, total_groups, -1, 3, self.num_heads, C // self.num_heads).permute(3, 0, 1, 4, 2, 5)
# B, hw, ws*ws, 3, n_head, head_dim -> 3, B, hw, n_head, ws*ws, head_dim
q, k, v = qkv[0], qkv[1], qkv[2] # B, hw, n_head, ws*ws, head_dim
attn = (q @ k.transpose(-2, -1)) * self.scale # B, hw, n_head, ws*ws, ws*ws
attn = attn.softmax(dim=-1)
attn = self.attn_drop(
attn) # attn @ v-> B, hw, n_head, ws*ws, head_dim -> (t(2,3)) B, hw, ws*ws, n_head, head_dim
attn = (attn @ v).transpose(2, 3).reshape(B, h_group, w_group, self.ws, self.ws, C)
x = attn.transpose(2, 3).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return xGSA代码:
class Attention(nn.Module):
"""
GSA: using a key to summarize the information for a group to be efficient.
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
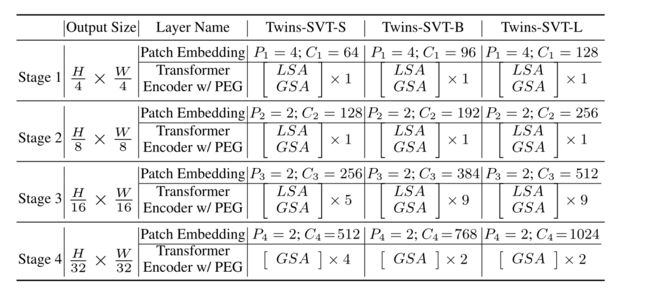
return xSVT具体配置
总结:
看了一下,主要创新点还是在这个全局attention和局部attention交替的设计上。另外也验证了一下PEG在transformer中的有效性。