多分类问题:初试手写数字识别
参考视频:09.多分类问题_哔哩哔哩_bilibili
文章目录
-
- 1 多分类问题:Softmax
- 2 手写数字识别
1 多分类问题:Softmax
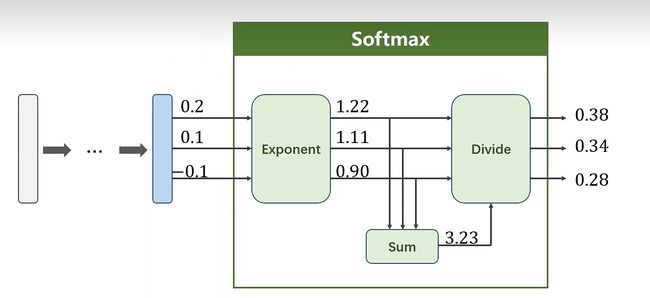
解决多分类问题需要用到Softmax分类器
将线性运算的所有结果变成正值,且和为1
P ( y = i ) = e Z i ∑ K − 1 j = 0 e Z j , i ∈ { 0 , . . . K − 1 } P(y=i)=\frac{e^{Z_i}}{\sum_{K-1}^{j=0}e^{Z_j}},i\in\{0,...K-1\} P(y=i)=∑K−1j=0eZjeZi,i∈{0,...K−1}
2 手写数字识别
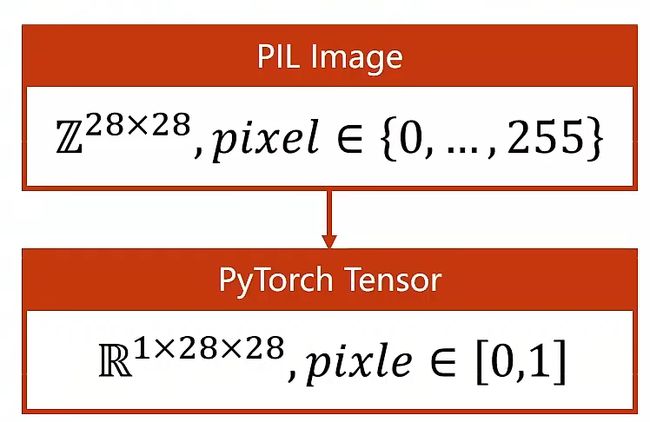
MNIST数据集中单张数字图片是 28 * 28 = 784的矩阵,每个像素点的取值是{0,255},需要将每个像素点的值映射到{0,1}之间。
在这个例子中,要把原始图像转变成张量,(1X28X28)其中1表示通道(手写数字图片是灰度图片只有单通道),28X28表示宽高:
所以我们每个批量输入神经网络的数据将会是(N,1,28,28)的四阶张量
我们需要把这个四阶张量转换成(N,784)的矩阵,即把每一张图片展平,每一行是784个元素

这次除了训练集,还加入了测试集
完整代码如下:
import torch
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
import torch.optim as optim
import torch.nn.functional as F
# 1 准备数据集
batch_size = 64
# 将{0,255}的像素值压缩到{0,1}
# 将图像转变成PyTorch中的Tensor
transform = transforms.Compose([
transforms.ToTensor(),
# 归一化,均值,标准差
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='dataset/mnist',
train=True,
transform=transform,
download=False)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='dataset/mnist',
train=False,
transform=transform,
download=False)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) # 测试集不需要打乱
# 2 设计模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # 将批量输入的图像展平,-1表示自动计算行数
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不做激活
model = Net()
# 3 构建损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 4 训练
def train(epoch):
running_loss = 0
for i, data in enumerate(train_loader, 0):
inputs, target = data # 输入和标签
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
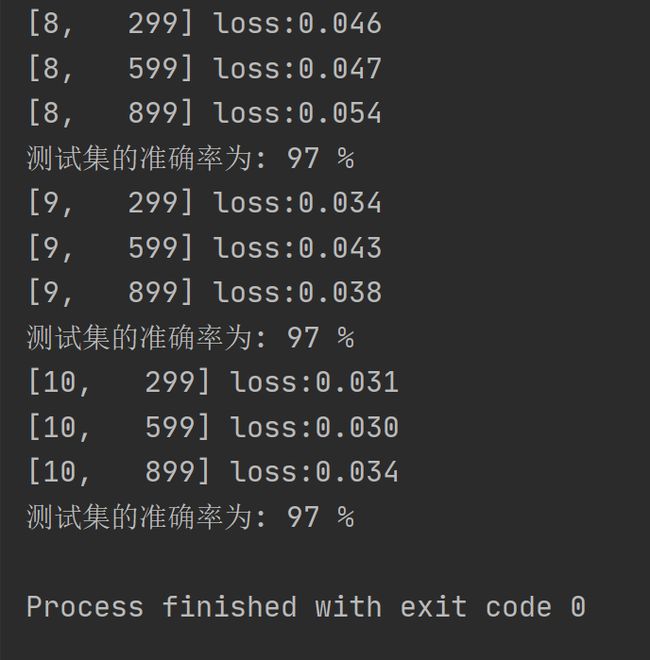
if i % 300 == 299:
print('[%d, %5d] loss:%.3f' % (epoch + 1, i, running_loss / 300))
running_loss = 0.0
# 5 测试
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
# 取每一行最大值为预测结果
_, predicted = torch.max(outputs.data, dim=1) # 返回最大值和下标,下划线为占位符,无意义
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('测试集的准确率为: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
经过10轮训练后,对测试集的准确率达到了97%,运行结果如下: