深度学习模型试跑(八):QueryInst

目录
- 前言
- 一.模型解读
-
- 1.动机
- 2.做法
- 二.模型训练
-
- 1.数据转换
- 2.配置
- 3.开始训练
- 三.模型推理
前言
项目地址:
华中科技大学&腾讯
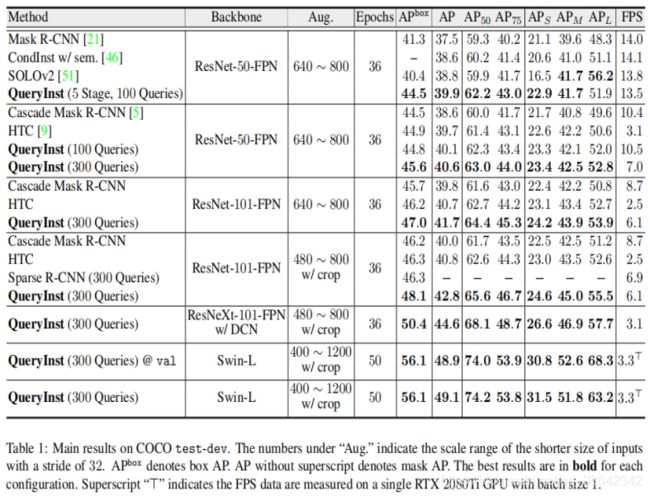
官方参数:
测试数据集:coco/Cityscapes/YouTube-VIS

一.模型解读
具体参考
1.动机
(省略常规操作如先捧对手、尽数它们的优点等…然而)之前得分比较高的例如Cascade Mask R-CNN 、 HTC这类non-query范例如果直接放到以query为基准的检测器下是十分效率底下的。在这篇文章中作者提出了QueryInst,基于query的实例分割,通过在动态mask heads上并行监督驱动,使得mask 的梯度不仅可以回溯到骨架网络的特征提取器中,并且对于目标query而言,它也可以在不同阶段本质上是一一对应。这些queries隐式携带了多阶的mask信息,这些信息会在最终的mask生成器中被动态mask头里的ROI特征提取器所使用。并且,在不同阶段不同子任务例如目标检测和实力分割当中,queries不仅可以互相分享而且可以互相利用的,使得这种query将协调合作的机制充分挥发了。总而言之,整个思路有以下优点:成功地在基于query的端到端检测框架中使用并行动态mask头的新角度解决实例分割问题;成功地通过利用共享query和多头自注意力设计为基于查询的目标检测和实例分割建立了任务联合范式;将QueryInst延展到例如YouTube-VIS数据集上,表现SOTA.
2.做法
主旨就是将单个实例instance都当作单个查询query.网络由一个基于目标检测器的query和六个动态并行监督的mask头组成。
对于Query based Object Detector,使用了Sparse R-CNN,它有六个query阶段。对于Mask Head Architecture,作者首先基于Mask R-CNN的mask结构,设计了Vanilla Mask Head…
二.模型训练
我的环境
os: win10
cuda: 11.0
gpu: RTX3090
torch: 1.7.0
官方给了安装流程,不过有的库在安装时会报错;最好的方法是把库的原始项目文件下下来安装,例如apex/pycocotools/mmcv等。
整个模型是基于mmdetection设计的,所以我训练流程都是按mmdetection制作数据流程来写的。
1.数据转换
我的数据是由labelme制作的,在网上搜了个脚本自己改了一下转成了coco类型数据;
# -*- coding:utf-8 -*-
import argparse
import json
import matplotlib.pyplot as plt
import skimage.io as io
import cv2
from labelme import utils
import numpy as np
import glob
import PIL.Image
class MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(MyEncoder, self).default(obj)
class labelme2coco(object):
def __init__(self, labelme_json=[], save_json_path='./tran.json', dir=''):
self.labelme_json = labelme_json
self.save_json_path = save_json_path
self.dir = dir
self.images = []
self.categories = []
self.annotations = []
# self.data_coco = {}
self.label = []
self.annID = 1
self.height = 0
self.width = 0
self.save_json()
def data_transfer(self):
for num, json_file in enumerate(self.labelme_json):
with open(json_file, 'r') as fp:
data = json.load(fp) # 加载json文件
self.images.append(self.image(data, num, self.dir))
for shapes in data['shapes']:
label = shapes['label']
if label not in self.label:
self.categories.append(self.categorie(label))
self.label.append(label)
points = shapes['points'] # 这里的point是用rectangle标注得到的,只有两个点,需要转成四个点
points.append([points[0][0], points[1][1]])
points.append([points[1][0], points[0][1]])
self.annotations.append(self.annotation(points, label, num))
self.annID += 1
def image(self, data, num, from_dir):
image = {}
# img = utils.img_b64_to_arr(data['imageData']) # 解析原图片数据
# img=io.imread(data['imagePath']) # 通过图片路径打开图片
img = cv2.imread('./%s/' % from_dir + data['imagePath'], 0)
height, width = img.shape[:2]
img = None
image['height'] = height
image['width'] = width
image['id'] = num + 1
image['file_name'] = data['imagePath'].split('/')[-1]
self.height = height
self.width = width
return image
def categorie(self, label):
categorie = {}
categorie['supercategory'] = 'Cancer'
categorie['id'] = len(self.label) + 1 # 0 默认为背景
categorie['name'] = label
return categorie
def annotation(self, points, label, num):
annotation = {}
annotation['segmentation'] = [list(np.asarray(points).flatten())]
annotation['iscrowd'] = 0
annotation['image_id'] = num + 1
# annotation['bbox'] = str(self.getbbox(points)) # 使用list保存json文件时报错(不知道为什么)
# list(map(int,a[1:-1].split(','))) a=annotation['bbox'] 使用该方式转成list
annotation['bbox'] = list(map(float, self.getbbox(points)))
annotation['area'] = annotation['bbox'][2] * annotation['bbox'][3]
# annotation['category_id'] = self.getcatid(label)
annotation['category_id'] = self.getcatid(label) # 注意,源代码默认为1
annotation['id'] = self.annID
return annotation
def getcatid(self, label):
for categorie in self.categories:
if label == categorie['name']:
return categorie['id']
return 1
def getbbox(self, points):
# img = np.zeros([self.height,self.width],np.uint8)
# cv2.polylines(img, [np.asarray(points)], True, 1, lineType=cv2.LINE_AA) # 画边界线
# cv2.fillPoly(img, [np.asarray(points)], 1) # 画多边形 内部像素值为1
polygons = points
mask = self.polygons_to_mask([self.height, self.width], polygons)
return self.mask2box(mask)
def mask2box(self, mask):
'''从mask反算出其边框
mask:[h,w] 0、1组成的图片
1对应对象,只需计算1对应的行列号(左上角行列号,右下角行列号,就可以算出其边框)
'''
# np.where(mask==1)
index = np.argwhere(mask == 1)
rows = index[:, 0]
clos = index[:, 1]
# 解析左上角行列号
left_top_r = np.min(rows) # y
left_top_c = np.min(clos) # x
# 解析右下角行列号
right_bottom_r = np.max(rows)
right_bottom_c = np.max(clos)
# return [(left_top_r,left_top_c),(right_bottom_r,right_bottom_c)]
# return [(left_top_c, left_top_r), (right_bottom_c, right_bottom_r)]
# return [left_top_c, left_top_r, right_bottom_c, right_bottom_r] # [x1,y1,x2,y2]
return [left_top_c, left_top_r, right_bottom_c - left_top_c,
right_bottom_r - left_top_r] # [x1,y1,w,h] 对应COCO的bbox格式
def polygons_to_mask(self, img_shape, polygons):
mask = np.zeros(img_shape, dtype=np.uint8)
mask = PIL.Image.fromarray(mask)
xy = list(map(tuple, polygons))
PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)
mask = np.array(mask, dtype=bool)
return mask
def data2coco(self):
data_coco = {}
data_coco['images'] = self.images
data_coco['categories'] = self.categories
data_coco['annotations'] = self.annotations
return data_coco
def save_json(self):
self.data_transfer()
self.data_coco = self.data2coco()
# 保存json文件
json.dump(self.data_coco, open(self.save_json_path, 'w'), indent=4, cls=MyEncoder) # indent=4 更加美观显示
if __name__ == '__main__':
dir = 'val2017' ###修改这个文件夹名,依次为val2017、train2017;
labelme_json = glob.glob('./%s/*.json' % dir)
# labelme_json=['./1.json']
labelme2coco(labelme_json, '.\\instances_%s.json' % dir, dir)
运行后会生成json格式的文件,放到annotations下就行了。
2.配置
在QueryInst工程目录下,参考queryinst_r50_fpn_1x_coco.py这个脚本,我复制了一个新脚本queryinst_r50_fpn_1x_coco_scratch.py.
修改的地方我用中文注释出来了,实际应用的时候不要带中文。
queryinst_r50_fpn_1x_coco_scratch.py
_base_ = [
'../_base_/datasets/scratch_instance.py',#用于数据配置
'../_base_/schedules/schedule_160k.py', #训练的超参数
'../_base_/default_runtime.py'#默认的运行配置
]
num_stages = 6
num_proposals = 100
model = dict(
type='QueryInst',
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=0,
add_extra_convs='on_input',
num_outs=4),
rpn_head=dict(
type='EmbeddingRPNHead',
num_proposals=num_proposals,
proposal_feature_channel=256),
roi_head=dict(
type='QueryRoIHead',
num_stages=num_stages,
stage_loss_weights=[1] * num_stages,
proposal_feature_channel=256,
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=2),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
mask_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=2),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=[
dict(
type='DIIHead',
num_classes=80,#保持为80,不然会报错
num_ffn_fcs=2,
num_heads=8,
num_cls_fcs=1,
num_reg_fcs=3,
feedforward_channels=2048,
in_channels=256,
dropout=0.0,
ffn_act_cfg=dict(type='ReLU', inplace=True),
dynamic_conv_cfg=dict(
type='DynamicConv',
in_channels=256,
feat_channels=64,
out_channels=256,
input_feat_shape=7,
with_proj=True,
act_cfg=dict(type='ReLU', inplace=True),
norm_cfg=dict(type='LN')),
loss_bbox=dict(type='L1Loss', loss_weight=5.0),
loss_iou=dict(type='GIoULoss', loss_weight=2.0),
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=2.0),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
clip_border=False,
target_means=[0., 0., 0., 0.],
target_stds=[0.5, 0.5, 1., 1.])) for _ in range(num_stages)
],
mask_head=[
dict(
type='DynamicMaskHead',
dynamic_conv_cfg=dict(
type='DynamicConv',
in_channels=256,
feat_channels=64,
out_channels=256,
input_feat_shape=14,
with_proj=False,
act_cfg=dict(type='ReLU', inplace=True),
norm_cfg=dict(type='LN')),
dropout=0.0,
num_convs=4,
roi_feat_size=14,
in_channels=256,
conv_kernel_size=3,
conv_out_channels=256,
class_agnostic=False,
norm_cfg=dict(type='BN'),
upsample_cfg=dict(type='deconv', scale_factor=2),
loss_dice=dict(type='DiceLoss', loss_weight=8.0)) for _ in range(num_stages)]),
# training and testing settings
train_cfg=dict(
rpn=None,
rcnn=[
dict(
assigner=dict(
type='HungarianAssigner',
cls_cost=dict(type='FocalLossCost', weight=2.0),
reg_cost=dict(type='BBoxL1Cost', weight=5.0),
iou_cost=dict(type='IoUCost', iou_mode='giou',
weight=2.0)),
sampler=dict(type='PseudoSampler'),
pos_weight=1,
mask_size=28,
debug=False) for _ in range(num_stages)
]),
test_cfg=dict(rpn=None, rcnn=dict(max_per_img=num_proposals, mask_thr_binary=0.5, nms=dict(type='nms', iou_threshold=0.7))))
# optimizer
optimizer = dict(_delete_=True, type='AdamW', lr=0.000025, weight_decay=0.0001)
optimizer_config = dict(_delete_=True, grad_clip=dict(max_norm=1, norm_type=2))
# learning policy
lr_config = dict(policy='step', step=[8, 11], warmup_iters=1000)
total_epochs = 200 #总共的epoch数,尽量设置大一点
在解释3个对应的配置脚本
scratch_instance.py
# dataset settings
dataset_type = 'PGDataset' #make a copy of class:CocoDataset and change its name just like 'PGDataset' in ./mmdet/datasets/coco.py
data_root = 'data/C1-label/'#change it to the location of your dataset
classes = ('scratch', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat',
'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot',
'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop',
'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush') #把coco类复制过来,把自己用到的标签逐一替换,其它的保留(反正用不上了;我这里只有一类);coco.py里也这样做
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type=dataset_type,
classes=classes,
ann_file=data_root + 'annotations/instances_train2017.json',
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
classes=classes,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
classes=classes,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))
evaluation = dict(metric=['bbox', 'segm'])
schedule_160k.py
# optimizer
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[16, 19])
# runtime settings
# runner = dict(type='IterBasedRunner', max_iters=160000)
runner = dict(type='EpochBasedRunner', max_epochs=200) #max_epochs要和total_epochs相等
evaluation = dict(interval=4000, metric='mIoU')
default_runtime.py
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook') #打开Tensorboard
])
# yapf:enable
custom_hooks = [dict(type='NumClassCheckHook')]
dist_params = dict(backend='gloo') #设置为gloo,NCCL只支持linux系统
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
不要减少类别,不然会有如下相似的错误:
AssertionError: The num_classes (3) in Shared2FCBBoxHead of MMDataParallel does not matches the length of CLASSES 80) in CocoDataset
如果你有解决方法,最好不要像我这配置classes
3.开始训练
训练脚本:
python tools/train.py configs/queryinst/queryinst_r50_fpn_1x_coco_scratch.py
训练的时候会报错,
错误1:
data[‘category_id’] = self.cat_ids[label]
IndexError: list index out of range
解决方法:
我到mmdet/datasets/coco.py下,找到每个self.cat_ids[label]的位置,然后在前面添加一句if label < 1:
例如
for i in range(bboxes.shape[0]):
if label < 1:
data = dict()
data['image_id'] = img_id
data['bbox'] = self.xyxy2xywh(bboxes[i])
data['score'] = float(bboxes[i][4])
data['category_id'] = self.cat_ids[label]
json_results.append(data)
错误2:想不起来啦,暂时先放着
三.模型推理
from mmdet.apis import init_detector, inference_detector, show_result_pyplot
config_file = 'configs/queryinst/queryinst_r50_fpn_1x_coco_scratch.py'
# download the checkpoint from model zoo and put it in `checkpoints/`
# url: https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth
checkpoint_file = 'checkpoints/pg_c1/latest.pth'
device = 'cuda:0'
# init a detector
model = init_detector(config_file, checkpoint_file, device=device)
# inference the demo image
result1 = inference_detector(model, 'demo/demo_c1_0.bmp')
# visualize the results in a new window
show_result_pyplot(model, 'demo/demo_c1_0.bmp', result1)
# inference the demo image
result2 = inference_detector(model, 'demo/demo_c1_1.bmp')
# visualize the results in a new window
show_result_pyplot(model, 'demo/demo_c1_1.bmp', result2)

参数验证:(忘记开tensorboard了,mmcv自带的感觉看起来不习惯)
