对于语义通信、一致性误差、均匀与非均匀量化和最小二乘法的一点见解
P0:语义通信
语义通信目前大多数是基于任务的,同时考虑语义和语用的信息处理和传递方式,与传统的通信方式相比较。语义通信的优势在于:语义通信更倾向于以任务为主体,或者说是先理解后传输,从而达到通信的本质:即需要什么就传什么,对原来信号进行有选择性压缩。语义通信方面比较常用的一些是联合信源信道编码策略,并且进行可以利用数据驱动的深度学习技术对联合信源信道进行处理。
①即语义通信过程仅仅传输的是我对此任务所需要的一些信息
②通信主要专注于信息传递的过程,虽然信源理解过程增加了语义编码复杂度,但是却换来了传输信息的大量减少,即我仅仅传输对解决任务有关的信息,对其他信息进行压缩。而一般的通信过程不会判断出有用信息,从而对有用信息也进行了和无用信息一样的处理,导致准确度的降低
③因为都需要进行信源信道编码,语义信源编解码的优势在于对信息进行有针对性的压缩,保留我们需要的有用信息
P1: Error Consistency
A consistency error refers to the occurrence of the values of two or more data items which do not satisfy some predefined relationship between those data items。(一致性错误是指出现两个或多个数据项的值,这些值不满足这些数据项之间的某些预定义关系。)
-
one:论文一:Beyond accuracy: quantifying trial-by-trial behaviour of CNNs and humans by measuring error consistency
网址:https://arxiv.org/abs/2006.16736
认知科学和行为神经科学以及机器学习和人工智能研究中的一个核心问题是确定两个或多个决策者——无论是大脑还是算法——是否使用相同的策略。
仅靠准确性无法区分策略:两个系统可能会使用非常不同的策略达到相似的准确性。如果两个系统的性能达到或接近上限,例如卷积神经网络 (CNN) 和人类视觉对象识别,那么区分精度的需求就显得尤为紧迫。在这里,我们介绍了反复试验的错误一致性(Error Consistency),这是一种定量分析,用于衡量两个决策系统是否系统地在相同的输入上出错。如果我们想确定决策者之间的相似处理策略,在一次次试验的基础上产生一致的错误是必要条件。我们的分析适用于比较算法与算法、人与人、算法与人的比较.
我们在这里介绍错误一致性3,这是一种定量分析,用于测量两个黑盒感知系统是否系统地在相同输入上出错。无论在 Marr 的实现级别 [12] 有任何潜在差异(可能非常大,例如在两个不同的神经网络架构之间,甚至在 CNN 和人类观察者之间更大),我们只能得出结论,如果两个系统使用类似的策略,这些系统会产生类似的错误:不仅是相似数量的错误(以准确性衡量),而且在相同输入上也会出现错误,即如果两个系统发现相同的单个刺激困难或容易(以错误一致性衡量)。变量之间的相关性并不意味着直接的因果关系,然而,相关性确实至少暗示了通过其他变量的间接因果关系。对于错误一致性,零错误一致性意味着两个决策者没有使用相同的策略。虽然错误一致性可以应用于跨领域、任务和领域(包括视觉、听觉处理等),但我们认为它在深度学习、神经科学和认知科学的交叉点特别重要。在不同的点上,大脑和 CNN 都被描述为黑盒机制 。
决策者是执行决策规则的任何(活的或人造的)实体。决策规则是定义从输入到输出的映射的函数(有关决策规则的分类,请参见 [4])。请注意,相同的决策规则可能来自不同的策略。我们使用术语策略与术语算法同义。
-
two:论文二:Multimodal assessment of apparent personality using feature attention and error consistency constraint
网址:https://www.sciencedirect.com/science/article/abs/pii/S0262885621000688
我们提出了一个新颖的多模态框架来识别视频中个人的明显个性,以解决这个问题。
FFM是一个基于五个维度的人格描述模型,作为对人格的完整描述。各种研究人员在人格理论的独立著作中确定了相同的五个因素 [11,12,13]。因此,用FFM定义人格是可靠的
我们提出的模型基于四种模式估计特征水平,即面部外观、环境外观(场景)、语音和转录语音。为此,我们为每种模式设计了一个子网络,其中我们利用最先进的(预训练的)深度架构作为我们模型的主干,并用长短期记忆(LSTM)网络对其进行补充,以利用时间信息。为了有效地融合多模态表示,我们设计并使用了一个特征注意层。此外,在损失函数中引入了错误一致性约束,以防止对某些特征的过度拟合。为了进行有效的建模,采用了两阶段训练,我们首先单独训练特定于模态的网络,在组合这些子网络后,以多模态方式对整个模型进行微调。使用在 ChaLearn First Impressions V2 挑战数据集 [14] 上提出的方法获得了最先进的结果。
我们提出了一种新的多模态方法来估计明显的人格特征。我们的方法依赖于四个子网络,每个子网络都专注于特定的模态,即环境外观、面部外观、语音和转录语音。这些子网络采用最先进的深度架构(例如,ResNet-v2-101、VGGish、ELMo)作为主干,并辅以额外的 LSTM 层以利用时间信息。为了更有效的建模,首先,上述每个子网络都已使用相应骨干网络的(预训练)权重参数进行初始化,并以特定于模态的方式进行训练(微调)。然后,这些子网络(在去除它们的回归层之后)被特征注意和回归层组合和补充。在子网络的参数保持冻结的同时,整个网络的新层已经过训练,以最小化预测五种人格特征的平均 MAE,并使用建议的误差使每种模态的误差尽可能接近一致性约束。通过这种方式,我们的模型可以防止由于联合多任务优化而过度拟合某些特定特征。尽管提出的架构是端到端可训练的,但我们遵循了分层训练,以最大限度地降低计算成本,同时提高效率。

图1 论文中对error consistency的应用
为了训练得到 的多模态模型,我们提出了一个基于 MAE 的损失函数,其中包括一个额外项:误差一致性,该术语强制特定特征的错误彼此相似。
第二项强制误差一致性,它被定义为五个人格特征的 MAE 的标准差。这样,可以实现有效的正则化。换句话说,错误一致性项可以防止某些人格特征出现高水平的错误,而模型会过度拟合其他特征。在训练过程中,使用 Adam 优化器,我们根据最小验证错误确定学习率。
P2: adptive bit allocation
不定长编码(变长编码):每个符号的码长与其概率相匹配,概率大的信息符号编以短的码字,概率小的符号编以长的码字。
香农编码方法:

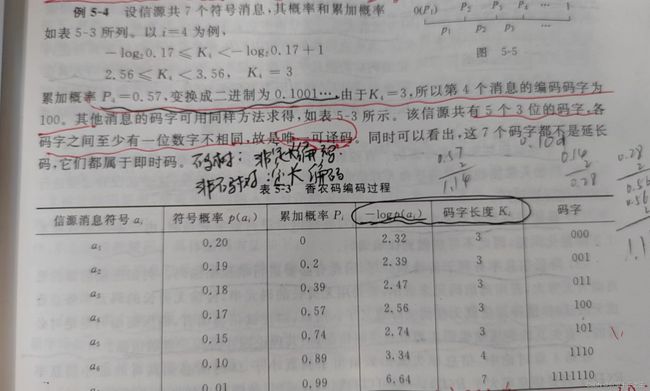
图2 香农编码方法
霍夫曼编码:
哈夫曼(赫夫曼,哈弗曼)编码算法(带源码+解析) (biancheng.net)
可以根据权重不同进行编码。

图3 霍夫曼编码方法
LZ编码:香农编码和霍夫曼编码都需要精确已知信源的概率分布,在实际的应用中,确切的获知信源统计特性有时是非常困难的,有时信源的统计特性还会随时发生变化,因此需要一种与信源统计特性无关的信源编码方法,称为通用信源编码。LZ系列算法的思想是将字典技术应用于通用数据压缩领域。而且可以从理论上证明LZ系列算法同样可以逼近信息熵的极限。

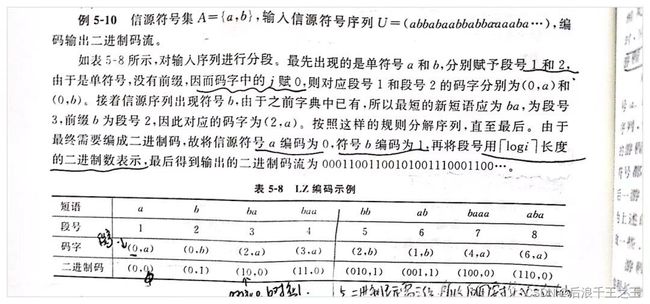
图 4 LZ编码方法
P3:上次的量化问题
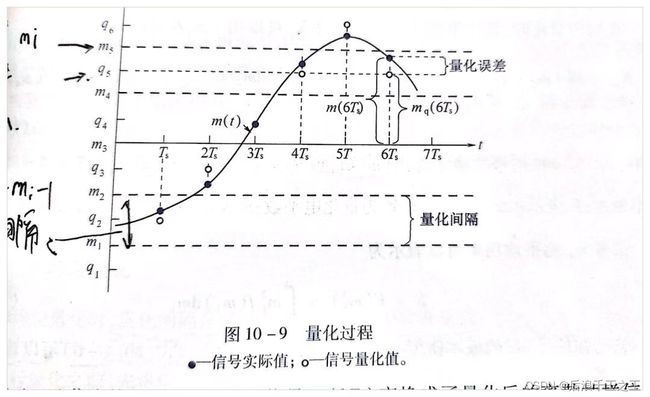
图 5 均匀量化过程

图 6 非均匀量化过程
4最小二乘法:
参考1:最小二乘法(least sqaure method) - 知乎(最小二乘法)
参考2:5.4 加权最小二乘法_jhshanvip的博客-CSDN博客_加权最小二乘法(加权最小二乘法)

图 7 最小二乘法概念
最小二乘法是使 ∑ i( b − a x ) 2 最小,这表明每次测量的重要性一样,但实际中有时存在某些测量更重要,某些更不重要。因此对很重要的(即对结果影响较大)测量特征误差的加权值应该更大,而对不太重要的测量特征的误差加权值应该更小,即最终损失函数应该是∑ i wi*( b − a x ) 2 ,这是加权最小二乘法的约束。