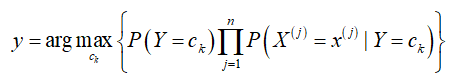参考链接:1.https://blog.csdn.net/li8zi8fa/article/details/76176597;
2.https://www.cnblogs.com/lliuye/p/9178090.html
3.https://blog.csdn.net/zengxiantao1994/article/details/72787849
4.https://monkeylearn.com/blog/practical-explanation-naive-bayes-classifier/
5.华校专,《Python大战机器学习》,电子工业出版社
本文目标:直观理解朴素贝叶斯是怎么做到分类的(how it works for classification),即形象并具体地说明算法步骤和思路来源。
基础:贝叶斯定理,即后验概率的计算公式。包括条件概率、先验概率、后验概率等概念。
0、朴素贝叶斯是什么?
朴素贝叶斯法(Naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入/输出的联合概率分布;然后基于此模型,对给定的输入 x ,利用贝叶斯定理求出后验概率最大的输出 y 。——《统计学习方法》
看完定义,其实朴素贝叶斯(Naive Bayes)是属于机器学习算法下的监督学习算法中的分类算法。
1、贝叶斯定理
又称贝叶斯公式,目的是通过先验概率和类条件概率来求后验概率。
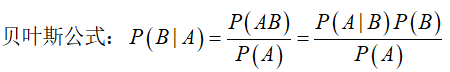
举例来说:已知:在夏季,某公园男性穿凉鞋的概率为1/2,女性穿凉鞋的概率为2/3,并且该公园中男女比例通常为2:1,问题:若你在公园中随机遇到一个穿凉鞋的人,请问他的性别为男性或女性的概率分别为多少?
|
|


其实上述例子中,A就是一种特征,B1和B2就是类别标签,因此用于贝叶斯分类任务的贝叶斯公式可以这样理解:

朴素贝叶斯分类又是啥意思呢?
首先,它所解决的分类问题中,特征X有很多维度,即它是一个向量,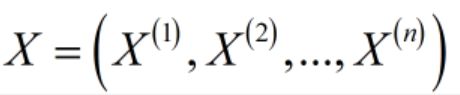 ,如此n维的特征X会带来指数级数量的参数(后面再讲);
,如此n维的特征X会带来指数级数量的参数(后面再讲);
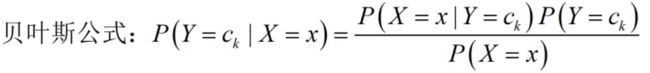 ,其中k取1,2,...,K。(代表一共有类别Y一共有K类)
,其中k取1,2,...,K。(代表一共有类别Y一共有K类)
其次,朴素的意思就是,对类条件概率做了条件独立性假设,就是下面的等式被它假设成立了:
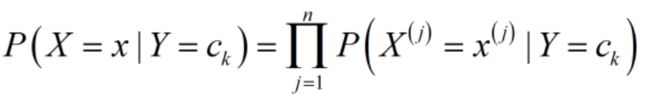 ,也就是说,本来X包含了n个的特征
,也就是说,本来X包含了n个的特征 ,一般情况下则n个特征的联合分布的概率不会是各个特征各自的概率分布的乘积,除了这n个特征互相之间是独立的,因此朴素所代表的是一种假设,而且是很强的假设。
,一般情况下则n个特征的联合分布的概率不会是各个特征各自的概率分布的乘积,除了这n个特征互相之间是独立的,因此朴素所代表的是一种假设,而且是很强的假设。
2.朴素贝叶斯的参数估计
朴素贝叶斯算法中,训练阶段(学习)就是从训练集中,估计出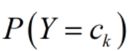 和
和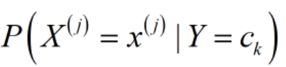 。也就是估计先验概率分布和类条件概率分布。
。也就是估计先验概率分布和类条件概率分布。
先验概率的极大似然估计为:
 ,也就是说,从训练集(样本)中ck所占比例就认为是总体中ck所占比例,即P(Y=ck)。
,也就是说,从训练集(样本)中ck所占比例就认为是总体中ck所占比例,即P(Y=ck)。
条件概率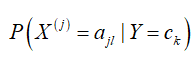 的极大似然估计为:
的极大似然估计为:

3.朴素贝叶斯的算法流程
算法步骤:
1.计算先验概率的估计值以及条件概率的估计值:

2.对于给定的实例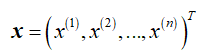 ,计算:
,计算:
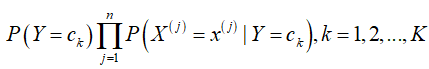
3.计算并返回实例x的分类y: