【深入浅出向】从自信息到熵、从相对熵到交叉熵,nn.CrossEntropyLoss, 交叉熵损失函数与softmax,多标签分类
文章目录
- 什么是信息
-
- 信息与消息的区别
- 信息测度:自信息
- 熵:信源的信息测度
-
- 信息熵
- 联合熵与条件熵
- 机器学习中的交叉熵
-
- 相对熵与交叉熵
- 机器学习中的相对熵与交叉熵[^2]
- 多分类中的交叉熵[^3]
- Pytorch中的交叉熵
-
- nn.CrossEntropyLoss
- nn.BCELoss
先给出本文的主要参考: 国防科技大学-信息论与编码基础(国家级精品课) 1
两年前我写过 softmax回归与交叉熵损失函数, 但是理解远远不够,本篇我们会从信息论最根本的信息出发,一步步看到为什么多分类问题中用softmax+交叉熵作为损失函数,最后会给一个多标签分类的例子加深这一认知。
什么是信息
信息是事物运动状态或存在方式的不确定性的描述(Shannon信息)
信息与消息的区别
消息:用文字、符号、语言、数据、音符、图片等能被人们感觉器官所感知的形式,把客观物质的运动和主观思维活动表达出来就称为消息。

通过消息的传递,使得我们消除不确定性(由于随机性而没有把握的因素),从而获得信息。
以通信过程为例:要传递的是信息,但是信息是抽象的东西难以捕捉,于是进行有形的实体进行搭载描述,这样说明就会方便一些。这个用来搭载描述的就是消息。以前不知道的东西,通过消息的传递,现在知道了,这个时候就会说我们获得了信息。
信息测度:自信息
信息量的大小,该用什么样的函数进行描述?这就涉及到了信息测度,也就是我需要定量的找一个函数来描述这个信息量的大小。下面先介绍自信息:

一个满足上述性质的函数 I I I即为
I ( a i ) = l o g r 1 P ( a i ) I(a_i)=log_r\frac{1}{P(a_i)} I(ai)=logrP(ai)1
不同对数底,自信息函数有不同的单位bit, nat, hart. r=2 bit; r=e nat; r=10 hart
自信息有两个含义:
(A)当 a i a_i ai发生以前,表示 a i a_i ai的不确定性
(B)当 a i a_i ai发生以后,表示 a i a_i ai提供的信息量
同样地,也会有联合自信息,条件自信息。这些我们会和后面的熵放到一起讲。
熵:信源的信息测度
信息熵
熵是平均自信息,对给定的信源分布,信息熵是一个固定值
为什么要引入信息熵?用前面提到的自信息不是也可以作为信息测度吗?举个例子:一个离散的随机变量,有0.99和0.01的概率输出不同的值,比如我们要反映这个变量的信息量大小,我看到一个输出值我计算 − l o g 0.99 -log0.99 −log0.99,没问题。但是问题是再来一个输出值呢?我重新算一个 − l o g 0.01 -log0.01 −log0.01嘛,这对一个随机变量整出两个度量,不太友好,合理的做法是取他们的数学期望。


由于其是平均自信息,所以表示的是随机变量X每个具体取值所提供的平均信息量,单位是bit/sig
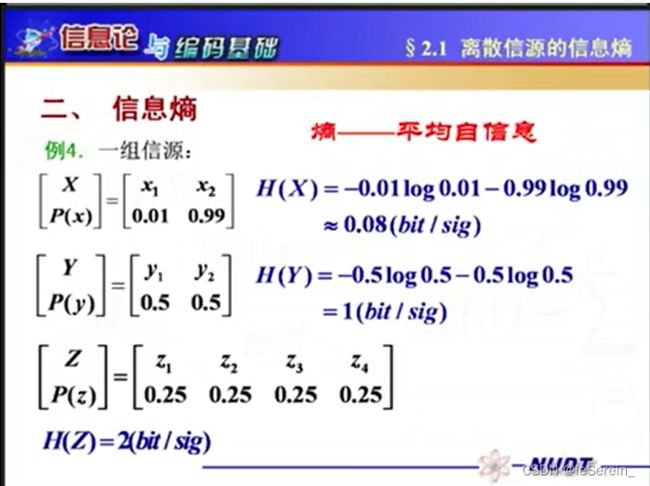
与自信息类比,其也有两个含义:
(A)描述信源X的平均不确定性,一个随机变量的熵越大,它的不确定性越大,正确估计其值的可能性越小
(B)平均每个信源符号所携带的信息量
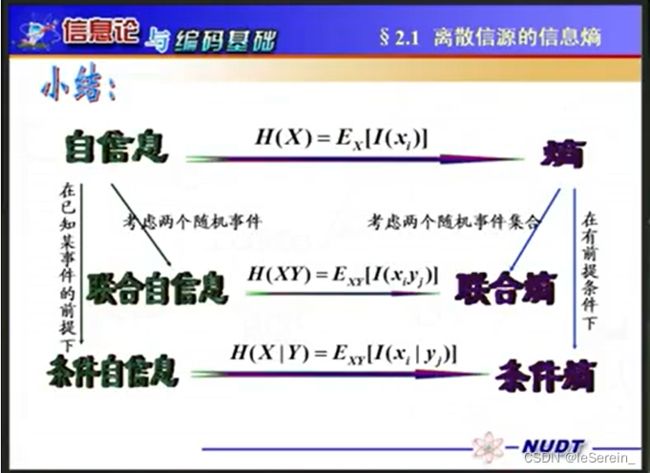
联合熵与条件熵
-
联合熵(joint entropy):如果X,Y是一对离散型随机变量X,Y~p(x, y),X,Y的联合熵为
H ( X , Y ) = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) l o g 2 p ( x , y ) H(X,Y)=-\sum_{x \in X}\sum_{y \in Y}p(x,y)log_2p(x,y) H(X,Y)=−x∈X∑y∈Y∑p(x,y)log2p(x,y)表示的是一对随机变量平均所需要的信息量 -
条件熵(conditional entropy):给定随机变量X的情况下,随机变量Y的条件熵定义为:
H ( Y ∣ X ) = ∑ x ∈ X p ( x ) H ( Y ∣ X = x ) = ∑ x ∈ X p ( x ) [ − ∑ y ∈ Y p ( y ∣ x ) l o g 2 P ( y ∣ x ) ] = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) l o g 2 p ( y ∣ x ) \begin{aligned} H(Y \mid X)&=\sum_{x \in X}p(x)H(Y \mid X=x) \\ &= \sum_{x \in X}p(x)\left[ -\sum_{y \in Y}p(y \mid x)log_2P(y \mid x)\right] \\ &=-\sum_{x \in X}\sum_{y \in Y}p(x,y)log_2p(y \mid x) \end{aligned} H(Y∣X)=x∈X∑p(x)H(Y∣X=x)=x∈X∑p(x)⎣ ⎡−y∈Y∑p(y∣x)log2P(y∣x)⎦ ⎤=−x∈X∑y∈Y∑p(x,y)log2p(y∣x)
机器学习中的交叉熵
相对熵与交叉熵
-
相对熵(relative entropy),或称Kullback-Leibler divergence,K-L距离或K-L散度
两个概率分布 p ( x ) p(x) p(x)或者 q ( x ) q(x) q(x)的相对熵定义为:
D ( p ∣ ∣ q ) = ∑ x ∈ X p ( x ) log p ( x ) q ( x ) D(p||q)=\sum_{x \in X}p(x)\text{log}\frac{p(x)}{q(x)} D(p∣∣q)=x∈X∑p(x)logq(x)p(x)
相对熵被用以衡量两个随机分布的差距,当两个随机分布相同时,其相对熵为0. 当两个随机分布差距增加时,相对熵也相应增加 -
交叉熵(cross entropy)
如果一个随机变量X~p(x), q(x)为用于近似p(x)的概率分布,那么随机变量X和模型q之间的交叉熵定义为
H ( X , q ) = H ( X ) + D ( p ∣ ∣ q ) = − ∑ x p ( x ) log q ( x ) \begin{aligned} H(X, q)&=H(X)+D(p||q) \\ &=-\sum_xp(x)\text{log}q(x) \end{aligned} H(X,q)=H(X)+D(p∣∣q)=−x∑p(x)logq(x)
交叉熵用以衡量估计模型与真实概率分布之间的差异
机器学习中的相对熵与交叉熵2
在机器学习中经常用 p ( x ) p(x) p(x)表示真实数据的概率分布(真实数据的概率分布往往无法获得,一般通过大量的训练数据来近似)假设我们通过某个模型得到了训练数据的概率分布 q ( x ) q(x) q(x),由于真实数据的概率分布 p ( x ) p(x) p(x)往往是不变的,因此最小化交叉熵 H ( p , q ) H(p,q) H(p,q),就等效于最小化相对熵 D ( p ∣ ∣ q ) D(p||q) D(p∣∣q)
习惯上机器学习算法中通常采用交叉熵计算损失函数,例如在某机器学习任务中定义损失函数为交叉熵:Loss=H(p, q)。假设我们训练到得到一个非常好的模型,即 p ( x ) ≈ q ( x ) p(x) \approx q(x) p(x)≈q(x),此时Loss不会降低为0,而是一个很小的值,如Loss=2,它表示真实数据自身的熵为 H ( p ) = 2 H(p)=2 H(p)=2。如果选择相对熵作为损失函数,即Loss=D(p||q)。同样假设我们训练得到一个非常好的模型,即 p ( x ) ≈ q ( x ) p(x) \approx q(x) p(x)≈q(x),此时,Loss=0,意味着两个概率分布几乎一样。
实际上,上述两种方法所得到的Loss仅仅是数值上的区别,训练得到的模型是完全一样的。
事实上交叉熵公式也比相对熵公式好算
多分类中的交叉熵3
尽管交叉熵刻画的是两个概率分布之间的距离,但是神经网络的输出却不一定是一个概率分布。为此我们常常用Softmax回归将神经网络前向传播得到的结果变成概率分布。
softmax常用于多分类过程中,它将多个神经元的输出,归一化到( 0, 1) 区间内,因此Softmax的输出可以看成概率,从而来进行多分类。
Q:为何分类用交叉熵?
A:见下图
Q:为何不用MSE计算 loss?
A:MSE是凸函数,logits先经过Softmax,再经过MSE形成的为非凸函数,不好优化;而用 Cross Entropy Loss 计算 loss,就还是一个凸优化问题,用梯度下降求解时,凸优化问题有很好的收敛特性。3
Pytorch中的交叉熵
nn.CrossEntropyLoss
以下内容转载自:pytorch中交叉熵损失nn.CrossEntropyLoss()的真正计算过程,侵删。
对于多分类损失函数Cross Entropy Loss,就不过多的解释,网上的博客不计其数。在这里,讲讲对于CE Loss的一些真正的理解。
首先大部分博客给出的公式如下:
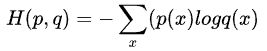
其中p为真实标签值,q为预测值。
在低维复现此公式,结果如下。在此强调一点,pytorch中CE Loss并不会将输入的target映射为one-hot编码格式,而是直接取下标进行计算。
import torch
import torch.nn as nn
import math
import numpy as np
#官方的实现
entroy=nn.CrossEntropyLoss(
input=torch.Tensor([[0.1234, 0.5555,0.3211],[0.1234, 0.5555,0.3211],[0.1234, 0.5555,0.3211],])
target = torch.tensor([0,1,2])
output = entroy(input, target)
print(output)
#输出 tensor(1.1142)
#自己实现
input=np.array(input)
target = np.array(target)
def cross_entorpy(input, target):
output = 0
length = len(target)
for i in range(length):
hou = 0
for j in input[i]:
hou += np.log(input[i][target[i]])
output += -hou
return np.around(output / length, 4)
print(cross_entorpy(input, target))
#输出 3.8162
我们按照官方给的CE Loss和根据公式得到的答案并不相同,说明公式是有问题的。
正确公式
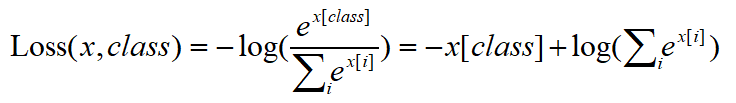
实现代码如下
import torch
import torch.nn as nn
import math
import numpy as np
entroy=nn.CrossEntropyLoss()
input=torch.Tensor([[0.1234, 0.5555,0.3211],[0.1234, 0.5555,0.3211],[0.1234, 0.5555,0.3211],])
target = torch.tensor([0,1,2])
output = entroy(input, target)
print(output)
#输出 tensor(1.1142)
#%%
input=np.array(input)
target = np.array(target)
def cross_entorpy(input, target):
output = 0
length = len(target)
for i in range(length):
hou = 0
for j in input[i]:
hou += np.exp(j)
output += -input[i][target[i]] + np.log(hou)
return np.around(output / length, 4)
print(cross_entorpy(input, target))
#输出 1.1142
对比自己实现的公式和官方给出的结果,可以验证公式的正确性。
观察公式可以发现其实nn.CrossEntropyLoss()是nn.logSoftmax()和nn.NLLLoss()的整合版本。
nn.logSoftmax(),公式如下
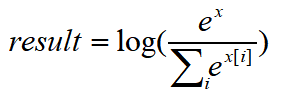
nn.NLLLoss(),公式如下
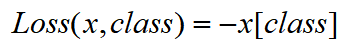
将nn.logSoftmax()作为变量带入nn.NLLLoss()可得
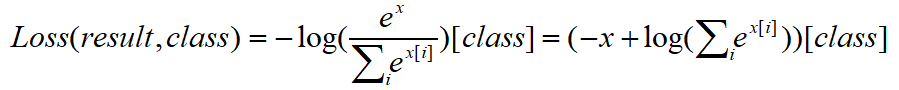
因为
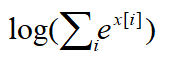
可看做一个常量,故上式可化简为:
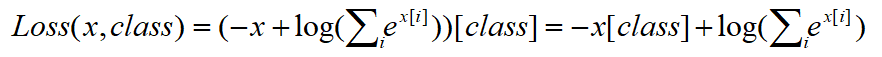
对比nn.Cross Entropy Loss公式,结果显而易见。
验证代码如下。
import torch
import torch.nn as nn
import math
import numpy as np
entroy=nn.CrossEntropyLoss()
input=torch.Tensor([[0.1234, 0.5555,0.3211],[0.1234, 0.5555,0.3211],[0.1234, 0.5555,0.3211],])
target = torch.tensor([0,1,2])
output = entroy(input, target)
print(output)
# 输出为tensor(1.1142)
m = nn.LogSoftmax()
loss = nn.NLLLoss()
input=m(input)
output = loss(input, target)
print(output)
# 输出为tensor(1.1142)
综上,可得两个结论:
1.nn.Cross Entropy Loss的公式。
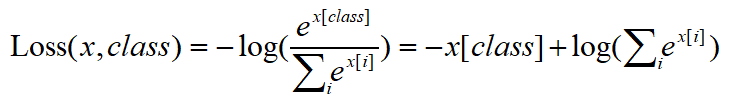
2.nn.Cross Entropy Loss为nn.logSoftmax()和nn.NLLLoss()的整合版本。
CELoss的公式来源
来自:pytorch中的cross_entropy函数
交叉熵是常见的损失函数,之前的文章中已经详细介绍了交叉熵的公式由来(交叉熵详解),公式如下:
![]()
如果用在多分类问题中当做损失函数的话,一般会这样写:
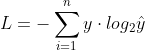
其中y是真实分类,是一个标签值; 是模型预测结果,包含了属于每种标签的概率(此时这几个概率相加还不等于1)。在上面说了函数的输入分别是input和target,那么y就对应target这个向量,就对应input这个矩阵。但是现在就出现了两个问题:
是模型预测结果,包含了属于每种标签的概率(此时这几个概率相加还不等于1)。在上面说了函数的输入分别是input和target,那么y就对应target这个向量,就对应input这个矩阵。但是现在就出现了两个问题:
1、target就是一个标签值,无法与input直接进行运算,那么我们就对这个target先进行one-hot编码,使二者的维度相同。 比如target的值是[3],共有5个类,那么转换为one-hot编码之后就是:[0,0,0,1,0]。
2、input中的预测值不能直接代表概率,而且这几个值相加不为1,这时就进行一个softmax操作,让模型的输出值满足上面两个条件,对输出结果的归一化公式如下:
![\hat{y}=P(\hat{y}=i|x)=\frac{e^{input_{[i]}}}{\sum_{j=1}^{n}e^{input_{[j]}}}](http://img.e-com-net.com/image/info8/7a914832925540748b9b969db96e4947.gif)
将![]() 带入到上面的损失函数公式中进行推导:
带入到上面的损失函数公式中进行推导:
![L=-\sum_{i=1}^{n}y\cdot log_{2}\hat{y}=-\sum_{i=1}^{n}y\cdot \frac{e^{input_{[i]}}}{\sum_{j=1}^{n}e^{input_{[j]}}}=-\sum_{i=1}^{n}y(input[i]-log_{2}\sum_{j=1}^{n}e^{input_{[j]}})](http://img.e-com-net.com/image/info8/dbbedc99ec464191bce5b69b0438814f.gif)
在第一点中我们已经将y转换为了[0,0,0,1,0]这样的编码,可见式子中只有target那一项的损失值需要计算,其他与0相乘就都消掉了,所以式子中最外层那个连加号就可以去掉了。最后式子就简化为:
![L=-input[target]+log_{2}\sum_{j=1}^{n}e^{input_{[j]}}](http://img.e-com-net.com/image/info8/29753413b9194877bf73989f572310c0.gif)
nn.BCELoss
BCE主要适用于二分类的任务,而且多标签分类任务可以简单地理解为多个二元分类任务叠加。因为一张图可能有多个标签,因此使用softmax不太合适,改之采用sigmoid输出概率值。所以BCE经过简单修改也可以适用于多标签分类任务。
使用BCE之前,需要将输出变量量化在[0,1]之间(可以使用Sigmoid激活函数)。上边我们也深度刨析了Sigmoid和Softmax两种激活函数,探究其统计学本质,Sigmoid的输出为伯努利分布,也就是我们常说的二项分布;而Softmax的输出表示为多项式分布。所以Sigmoid通常用于二分类,Softmax用于多类别分类。4
pytorch使用时,CrossEntropyLoss的input是直接网络的输出,label是数;BCELoss的input是网络的输出再经过sigmoid, label是one-hot编码
一个多标签的实例可以看我传的这个代码:https://github.com/ppx-hub/multi-label-sand
其中就用了BCELoss来训练网络,让不是这类的输出尽可能为负值,让是这类的输出尽可能为正值。而判断是否是多个标签则通过设定一个阈值,对输出的概率与阈值大小进行判断,大于阈值则存在该目标。这是一个简单的判断过程,主要是体会BCELoss对每个目标是否存在进行的损失计算。
国防科技大学-信息论与编码基础(国家级精品课) ↩︎
国科大自然语言处理课件 ↩︎
简单谈谈Cross Entropy Loss ↩︎ ↩︎
损失函数 | BCE Loss(Binary CrossEntropy Loss) ↩︎