单目标视觉跟踪算法研究_2022寒假
单目标视觉跟踪算法研究
1介绍
目标跟踪是对于任一一视频序列,给定第一帧的跟踪目标,在后续的每一帧中给出目标的定位和尺度估计
主要的特点:单目标、目标类别任意
主要的挑战有遮挡、光照变化、非刚性形变、背景杂乱
2相关工作
2.1单目标跟踪数据集
OTB100
TrackingNet: 大规模短时跟踪数据集
OxUvA: 尝试跟踪数据集
GOT-10K: 目标类别及其丰富的短时跟踪数据集
LaSOT:大规模长时跟踪数据集
VOT2016
VOT2017:实时赛道
VOT2018:长时赛道
VOT2019: RGBD&RGBT
2.2单目标跟踪评估指标
One Pass Evaluation(OPE):
Success: 真值与预测目标框的重叠率大于给定阈值的视频帧比率,反映预测目标的大小和尺度的准确性
Precision: 真值与预测目标的中心点距离小于给定阈值的视频帧比率,一般阈值设为20个像素点,可以反映中心位置误差
VOT系列评估指标:
Expect Average Overlap(EAO): 综合精度(A)和鲁棒性(R)的指标,其中基于重叠率计算,鲁棒性基于视频的跟丢次数计算失败率
2.3国内外研究现状及其分析
2.3.1基于相关滤波
KCF, DSST, BACF
缺点:不能应对尺度和长宽比变化
2.3.2基于Siamese的跟踪方法
学习模板与搜索区域的相似性
该类方法大多数不进行在线更新,导致方法辨别性低(导致不如相关滤波)
该类方法的性能对后处理过程的超参数敏感,例如:尺度惩罚、余弦窗口
SiamFC(ECCV16)[1]

通过模板匹配定位目标
骨干网络是一个无填充的AlexNet
SiamRPN(CVPR18)[2]
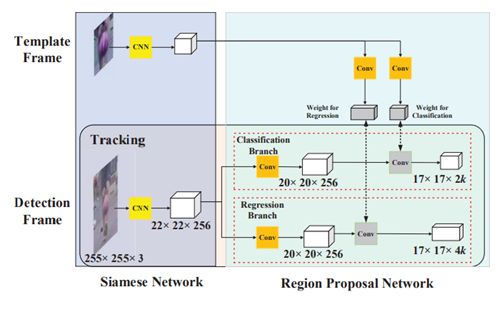
首次将跟踪任务作为one-shot检测任务
将模板信息编码到RPN模块中
没有多尺度,相比于SiamFC速度大幅提升
SiamRPN++(CVPR19)[3]

使用更强大的ResNet-50作为骨干网络
使用Depth-wise correlation进行特征交互
多个RPN模块
SiamMask(CVPR19)[4]
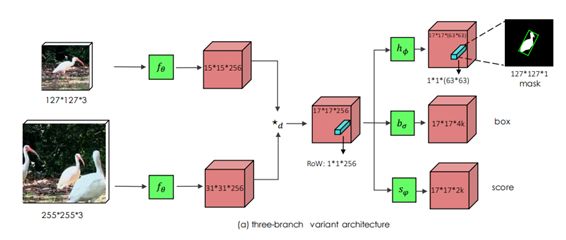
使用ResNet-50作为骨干网络
引入一个掩码分支来统一跟踪和分割任务
SiamFC++(AAAI20)[5]

骨干网络为无填充的Alex/GoogleNet
设计思虑基于FCOS
Anchor-free机制消除了歧义分数(缓解手动设计Anchor不灵活)的问题
Ocean(ECCV20)
2.3.3在线更新的辨别式方法
在线学习一个辨别式分类器来区分背景和目标,eg., MDNet, ATOM, DiMP
在线更新可以捕捉外观变化、适应背景的变化,更加准确,但速度更慢(相比离线)
在线更新可能会引入噪声样本,LTMU被提出来解决“何时更新“的问题
MDNet(CVPR2016)[6]

包含共享层和多个特定于域的分支
共享层用来学习通用的特征表达
每一个域关联一个单独的序列
fc4, fc5, 和特定于域的fc6层的参数会被在线微调
ATOM(CVPR2019)[7]


包含目标估计和分类模块
分类:在线分类器用于目标定位
目标估计:离线训练的IOU预测器进行尺度估计,训练时最大化真值和预测值之间的IOU
调制来自参考和测试分支的特征
DiMP(CVPR2019)[8]

Model Predictor D: 一个辨别式的模型预测框架(修改ATOM的分类分支)
模型初始器仅使用初始目标外观信息预测初始模型权重
模型优化器同时考虑目标和背景样本来处理初始权重
提出一个辨别式损失函数来学习一个鲁棒的目标模型
一个强大的优化策略(不使用固定的学习率,而是设计了梯度下降方式自适应地去学习学习率)来保证快速收敛,借助这个策略,可以超过40FPS
PrDiMP(CVPR2020)[9]

解决问题:跟踪器往往通过预测中心坐标来实现跟踪,对于右图,目标的中心没有落在目标上,因此根据真值框给出的真值response map和网络预测的response map之间会存在差值,导致不确定性和模糊性。
提出一个概率回归模型,来生成一个预测概率分布
网络模型通过最小化预测分布和真实分布的KL散度来训练
KYS(ECCV2020)[10]


解决跟踪中相似目标的干扰(外形相似干扰通常是导致跟踪失败的原因之一)
通过序列来隐式维护可用的场景信息,场景信息被表示为若干个状态向量
通过帧与帧之间的相关性来更新相关的向量
维护场景信息对分辨目标和干扰物起到很大的帮助
PS: Appearance Model 是DiMP
LTMU(CVPR2020)[11]

解决问题:在线更新,错误的样本累积的误差可能会引发模型的退化,尤其是长时中目标消失、重现更常见,所以目标是否更新值得研究
仅仅根据response图的分数来判断跟踪目标是否准确,继而决定是否更新是不可靠的,如上图中失败的案列
提出一个meta-updater来解决“何时更新”问题
设计了一个级联式LSTM框架,搭建一个二值分类器如下图,输入是集成几何、辨别式和外观线索的序列的信息,最终输出一个0或1二值分类分数,确定当前帧是否更新
通过在跟踪器中集成meta-updater,long time跟踪也能利用到精度更高的短时判别式跟踪器,可以保持算法的稳定性。
2.3.4基于Transformer
更少的归纳偏置
建立远距离关联和聚集全局信息
需要大量数据
巨大计算量(于token数量的平方成正比)
单目标跟踪有丰富的数据集,常采用搜索区域的方法进行跟踪,所以图片比较小,token数比较少,所以在一定程度上绕过了Transformer计算量巨大的缺点,因此Transformer在跟踪中,尤其是搜索区域和模板的特征融合上,取得了成功的应用
TransT(CVPR2021)[12]
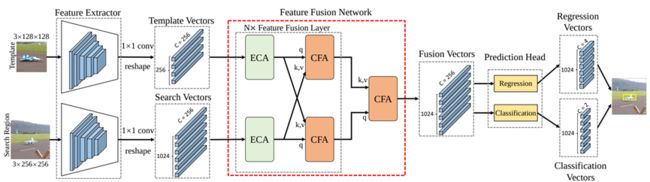
最早应用Transformer到单目标跟踪之一,使用注意力机制解决相关性瓶颈
解决问题:Siamese中的相关运算是一个线性的局部比较,输出是一个丢失了语义信息的相似度图,缺乏语义信息和全局信息,不利于定位中干扰物的排除以及边界框的回归
使用Transformer中的cross-attention取代Siamese常用的相关运算,来进行模板与搜索特征区域的融合,关键是基于self-attention的ECA模块和基于cross-attention的CFA模块,ECA进行全局信息的聚合,CFA进行模板和搜索区域特征的融合,用简单的感知机来进行前景背景的二分类以及边界框的回归,可以达到实时的速度
Transformer通过聚合全局信息和建立远距离特征关联来提升跟踪性能
TMT(CVPR2021)[13]

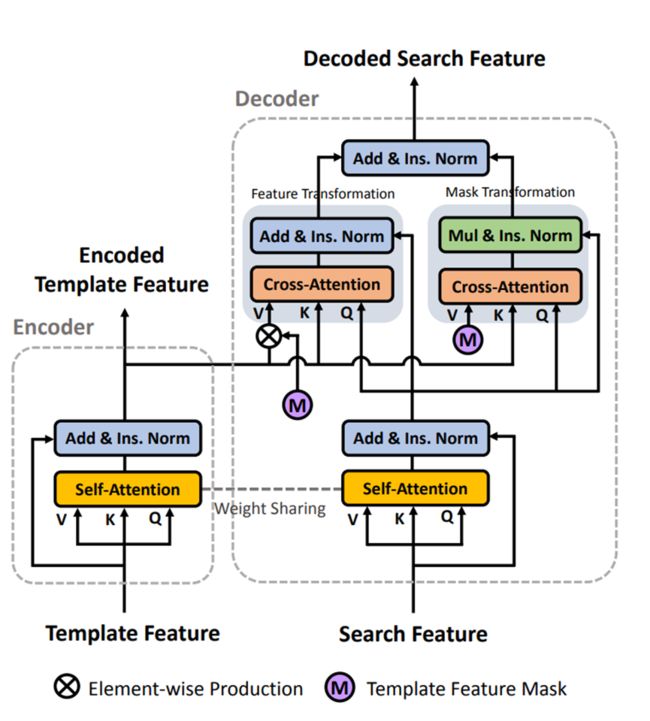
最早应用Transformer到单目标跟踪之一
与TranT不同,使用Transformer来做特征增强,而并不是取代之前的convolution,作者分布应用在Siamese Tracker,Online Tracker和DiMP中,开发了TrDiMP和TrSiam,并且使用了随着跟踪过程跟新的模板集来记录时序信息
Stark(ICCV2021)[14]
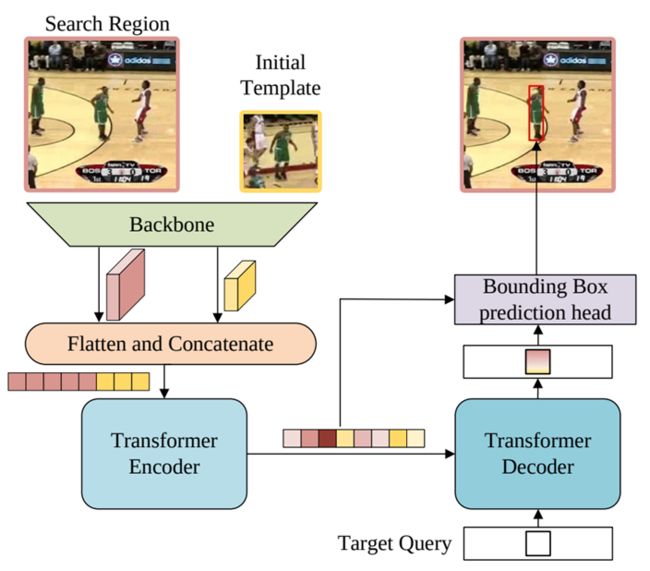
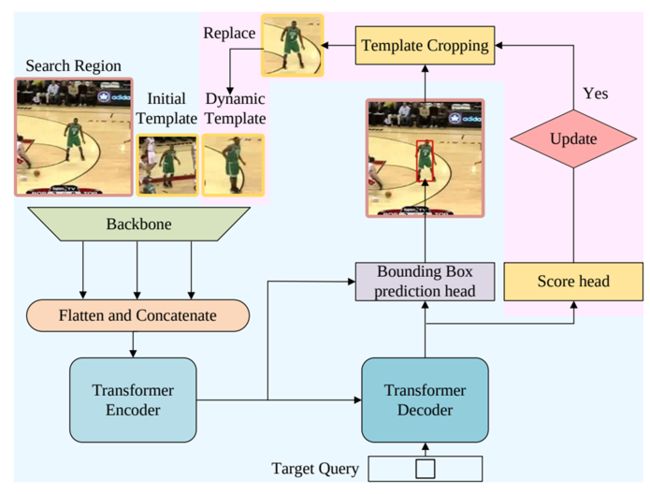

不同于TransT, TMT对分开的模板和搜索区域特征做交互,拼接搜索区域和模板特征,直接输入Transformer的Encoder和Decoder,可以完成两个特征的自注意和互注意
采用动态模块来记录模板信息,设计score head分数模块判断模板好坏来控制模板的更新
角边界框预测模块使回归更加准确
TREG[15]

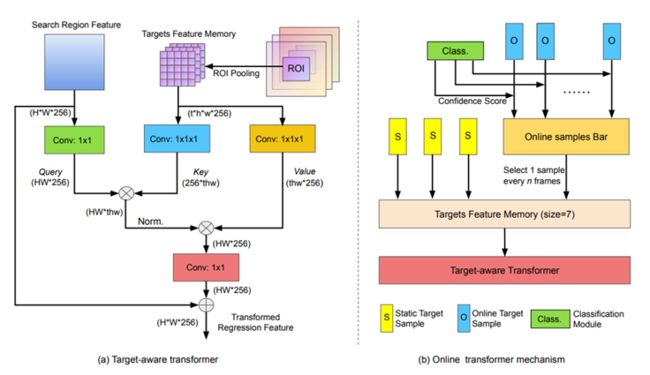
Cross-attention对于模板特征加强后,融合到搜索区域的特征上
目标感知的Transformer
在线的Transformer机制(3帧静态模板和4帧在线更新的模板)
DualTFR(ICCV2021)[16]

最早提出纯Transformer网络,而不是“CNN+Transformer”,CNN的特征并非为跟踪中的匹配来进行设计,因此作者设计了一个基于Attention的主干网络,网络在预训练时,Attention就进行了充足的匹配过程,因此这样的特征会更适合后面的cross-attention,主干网络博客local attention局部注意力模块和global attention全局注意力模块,类似swim transformer,local attention划分窗口和局部的attention增强,而global attention建立远距离依赖和全局感受野
从匹配中学习特征以进行匹配
SwinTrack[17]
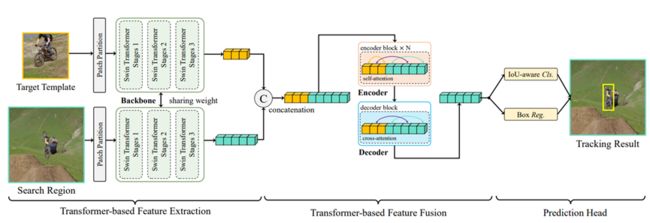
纯Transformer的跟踪方法,将Swin Transformer的特征进行拼接后,送到Transformer的Encoder,进一步提升了跟踪的效果和速度。
2.4单目标跟踪发展趋势
融合检测来实现跟踪成为主流(SOTA Siamese Trackers)
引入mask实现像素级跟踪(SiamMask, VOT20-ST/RT)
数据集巨型化(TrackingNet,LaSOT,GOT-10K)
子领域多样化(LT,RGBD,RGBT)
Transformer会是未来一段时间的热点
5参考文献
[1] Bertinetto L, Valmadre J, Henriques J F, et al. Fully-convolutional siamese networks for object tracking[C]//European conference on computer vision. Springer, Cham, 2016: 850-865.
[2] Li B, Yan J, Wu W, et al. High performance visual tracking with siamese region proposal network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8971-8980.
[3] Li B, Wu W, Wang Q, et al. Siamrpn++: Evolution of siamese visual tracking with very deep networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 4282-4291.
[4] Wang Q, Zhang L, Bertinetto L, et al. Fast online object tracking and segmentation: A unifying approach[C]//Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. 2019: 1328-1338.
[5] Xu Y, Wang Z, Li Z, et al. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(07): 12549-12556.
[6] Nam H, Han B. Learning multi-domain convolutional neural networks for visual tracking[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 4293-4302.
[7] Danelljan M, Bhat G, Khan F S, et al. Atom: Accurate tracking by overlap maximization[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 4660-4669.
[8] Bhat G, Danelljan M, Gool L V, et al. Learning discriminative model prediction for tracking[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 6182-6191.
[9] Danelljan M, Gool L V, Timofte R. Probabilistic regression for visual tracking[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 7183-7192.
[10] Bhat G, Danelljan M, Gool L V, et al. Know your surroundings: Exploiting scene information for object tracking[C]//European Conference on Computer Vision. Springer, Cham, 2020: 205-221.
[11] Dai K, Zhang Y, Wang D, et al. High-performance long-term tracking with meta-updater[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 6298-6307.
[12] Chen X, Yan B, Zhu J, et al. Transformer tracking[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 8126-8135.
[13] Wang N, Zhou W, Wang J, et al. Transformer meets tracker: Exploiting temporal context for robust visual tracking[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1571-1580.
[14] Yan B, Peng H, Fu J, et al. Learning spatio-temporal transformer for visual tracking[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10448-10457.
[15] Cui Y, Jiang C, Wang L, et al. Target transformed regression for accurate tracking[J]. arXiv preprint arXiv:2104.00403, 2021.
[16] Xie F, Wang C, Wang G, et al. Learning Tracking Representations via Dual-Branch Fully Transformer Networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 2688-2697.
[17] Lin L, Fan H, Xu Y, et al. SwinTrack: A Simple and Strong Baseline for Transformer Tracking[J]. arXiv preprint arXiv:2112.00995, 2021.
[18]