图像清晰化代码实战详解——基于tensorflow2.x(适合新手)
观看前需要先大概了解卷积运算,和tensorflow2基本操作,本文主要详解代码实战,原理仅简单介绍
原理简介:
模型结构为U-net,主要通过一系列卷积和反卷积,最终将原图像大小翻倍(像素翻倍),实现清晰化。通过跨层concat(拼接),可以使模型同时具有提取抽象特征以及提取细节的能力。(注意concat是某个维度上的拼接,而不是直接相加)。模型的输入是一张图片,输出的图片长度宽度均为原图的两倍,可以达到比原图更清晰的效果。U-net结构图如下,转自知乎。
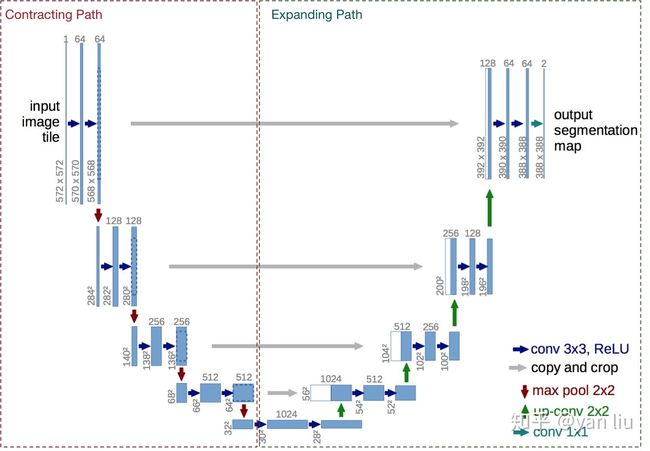
代码详解
数据集图片文件处理
数据集可以是自己在一个文件夹里放一堆图片。图片可以是风景,可以是漫画,可以是其他,尽量是同一种类型的图片(不要将现实照片与漫画放一起),这样有针对性的训练效果会比较好。
import os
#参数
path1 = 'A' #存放图片的文件夹,需要根据自己的文件夹路径改
path2 = 'B' #如果只有一个文件夹,可以把这个注释掉
#获取所有图片的路径列表
files_list1 = [os.path.join(path1, name) for name in os.listdir(path1)]
files_list2 = [os.path.join(path2, name) for name in os.listdir(path2)]
files_list = files_list1 + files_list2 #生成所有图片的路径列表
#删除不符合尺寸的图片
kk = 0
im_size = 512
for b in files_list:
img = tf.io.read_file(b)
test_pic = tf.io.decode_image(img, channels=3) #解码图片
if test_pic.shape[0] os.listdir将列出当前路径的所有文件名,后用os.path.join把文件夹路径和文件名拼接,最后添加到一个列表里,列表包含了一个文件夹内的所有文件路径。
由于图片有RGB三个通道,所以需要用tf.io.decode_image(img, channels=3)解码图片,解码后的形状为(高度,宽度,3),用if来判断高度或宽度过小的图片,这些图片不利于训练,将被删除
以上操作将删除文件夹中图片长度或者宽度小于512的图片,这是为了在接下来的训练中,能够对数据集进行统一尺寸的裁剪。512这个数值并不是固定的,可以改成256,128之类的数值。这取决与你训练时想要用的图片大小。(由于会删除图片,可以在运行前先备份一下图片文件夹,以免删除重要图片)
处理完之后,可以进行下一步
数据预处理
导入库:
import tensorflow as tf
from tensorflow import keras
import os
数据预处理方法
#参数
train_input_size = 256 #训练时的输入图片大小,可以调整
train_target_size = train_input_size*2 #训练的目标图片大小,最大值是上文判断的大小
jpge_quality_min = 50 #模糊最小值(取值0-1,越大图片越清晰)
jpge_quality_max = 75 #模糊最大值
noise_stddev=0.015 #噪声标准差
@tf.function
def trans_func(files):
img_bin = tf.io.read_file(files)
#调用tf.cond判断图片是否为jepg(jpg),如果是则用jpeg解码方式,如果不是则用png解码方式
img_decode = tf.cond(
tf.image.is_jpeg(img_bin),
lambda: tf.image.decode_jpeg(img_bin, channels=3),
lambda: tf.image.decode_png(img_bin, channels=3)
)
target_img = tf.image.convert_image_dtype(img_decode, tf.float32) # 转为tf.float32
target_img = tf.image.random_crop(target_img, [train_target_size, train_target_size, 3]) #随机裁剪
target_img = tf.image.random_flip_left_right(target_img) # 随机左右翻转
target_img = tf.image.random_contrast(target_img, 0.25, 0.75) #随机调整图像对比度
target_img = tf.image.random_brightness(target_img, 0.2) #随机调整图像亮度
train_img = tf.image.resize(target_img, [train_input_size, train_input_size],
method=train_resize_mhd) # 缩放到固定大小,这个大小是输出的一半
train_img = tf.image.random_jpeg_quality(train_img, min_jpeg_quality=jpge_quality_min,
max_jpeg_quality=jpge_quality_max) #模糊处理
noise = tf.random.normal(shape=[train_input_size, train_input_size, 3], stddev=noise_stddev)
train_img = train_img + noise #添加噪声
return [train_img, target_img]tf.cond()是先看第一个参数bool值,如果为True,则调用jepg(jpg)解码方法,如果为False则用png解码方式。
用tf.image.convert_image_dtype()而不是tf.cast(),虽然两者对张量操作可以达到相同的效果,但是后者在之后转unit8类型数据会出问题,导致图片编码异常,所以只能用前者。
这个方法,首先对图片进行了解码,并且转为tf.float32便于模型训练,并且进行了随机翻转和微调,增加了数据的多样性。
因为输出值target_image形状大小(高度,宽度)是输入值train_img的两倍。之后将图片resize成原来的一半大小,作为模型训练的输入值。为了让模型有到更强的效果,所以针对输入值train_img,要添加模糊化(random_jpeg_quality)以及噪声(noise),增加训练难度。
最后把[train_img, target_img]返回
tf数据集生成
path1 = 'A' #第一个存放图片的文件夹
path2 = 'B' #第二个存放图片的文件夹,如果只有一个图片文件夹可以把这个删掉
#获取所有图片路径列表
files_list1 = [os.path.join(path1, name) for name in os.listdir(path1)]
files_list2 = [os.path.join(path2, name) for name in os.listdir(path2)]
files_list = files_list1 + files_list2 #图片路径列表拼接
print('图片总数量:',len(files_list))
#生成tf的Dataset
ds = tf.data.Dataset.from_tensor_slices(files_list)
ds = ds.shuffle(10000) #随机打乱
ds = ds.map(trans_func, num_parallel_calls=-1, deterministic=False)
#调用上面的预处理函数
ds = ds.batch(8) #设置batch大小生成dataset,之后就可以构建模型,开始训练了
U-net模型构建
class Repairer(keras.Model):
def __init__(self):
super(Repairer, self).__init__()
self.level_1_conv1 = keras.layers.Conv2D(64, 3, 1, 'same', activation='elu')
self.level_1_conv2 = keras.layers.Conv2D(64, 3, 1, 'same', activation='elu')
self.level_1_pool = keras.layers.MaxPooling2D()
self.level_2_conv1 = keras.layers.Conv2D(128, 3, 1, 'same', activation='elu')
self.level_2_conv2 = keras.layers.Conv2D(128, 3, 1, 'same', activation='elu')
self.level_2_pool = keras.layers.MaxPooling2D()
self.level_3_conv1 = keras.layers.Conv2D(256, 3, 1, 'same', activation='elu')
self.level_3_conv2 = keras.layers.Conv2D(256, 3, 1, 'same', activation='elu')
self.level_3_pool = keras.layers.MaxPooling2D()
self.level_4_conv1 = keras.layers.Conv2D(512, 3, 1, 'same', activation='elu')
self.level_4_conv2 = keras.layers.Conv2D(512, 3, 1, 'same', activation='elu')
self.level_4_pool = keras.layers.MaxPooling2D()
self.level_3_conv1t = keras.layers.Conv2DTranspose(256, 3, 2, 'same', activation='elu')
self.level_3_concat = keras.layers.Concatenate()
self.level_3_conv2t = keras.layers.Conv2DTranspose(256, 3, 1, 'same', activation='elu')
self.level_2_conv1t = keras.layers.Conv2DTranspose(128, 3, 2, 'same', activation='elu')
self.level_2_concat = keras.layers.Concatenate()
self.level_2_conv2t = keras.layers.Conv2DTranspose(128, 3, 1, 'same', activation='elu')
self.level_1_conv1t = keras.layers.Conv2DTranspose(64, 3, 2, 'same', activation='elu')
self.level_1_concat = keras.layers.Concatenate()
self.level_1_conv2t = keras.layers.Conv2DTranspose(64, 3, 1, 'same', activation='elu')
self.level_0_conv1t = keras.layers.Conv2DTranspose(64, 3, 2, 'same', activation='elu')
self.level_0_concat = keras.layers.Concatenate()
self.level_0_conv2t = keras.layers.Conv2DTranspose(64, 3, 2, 'same', activation='elu')
self.level_0_conv3t = keras.layers.Conv2D(64, 3, 1, 'same', activation='elu')
self.level_0_conv4t = keras.layers.Conv2D(64, 3, 1, 'same', activation='linear')
self.model_output = keras.layers.Conv2D(3, 3, 1, 'same', activation='elu')
def call(self,image_tffloat32):
level_1_conv1 = self.level_1_conv1(image_tffloat32)
level_1_conv2 = self.level_1_conv2(level_1_conv1)
level_1_pool = self.level_1_pool(level_1_conv2)
level_2_conv1 = self.level_2_conv1(level_1_pool)
level_2_conv2 = self.level_2_conv2(level_2_conv1)
level_2_pool = self.level_2_pool(level_2_conv2)
level_3_conv1 = self.level_3_conv1(level_2_pool)
level_3_conv2 = self.level_3_conv2(level_3_conv1)
level_3_pool = self.level_3_pool(level_3_conv2)
level_4_conv1 = self.level_4_conv1(level_3_pool)
level_4_conv2 = self.level_4_conv2(level_4_conv1)
level_4_pool = self.level_4_pool(level_4_conv2)
level_3_conv1t = self.level_3_conv1t(level_4_pool)
level_3_concat = self.level_3_concat([level_3_conv1t, level_4_conv2])
level_3_conv2t = self.level_3_conv2t(level_3_concat)
level_2_conv1t = self.level_2_conv1t(level_3_conv2t)
level_2_concat = self.level_2_concat([level_2_conv1t, level_3_conv2])
level_2_conv2t = self.level_2_conv2t(level_2_concat)
level_1_conv1t = self.level_1_conv1t(level_2_conv2t)
level_1_concat = self.level_1_concat([level_1_conv1t, level_2_conv1])
level_1_conv2t = self.level_1_conv2t(level_1_concat)
level_0_conv1t = self.level_0_conv1t(level_1_conv2t)
level_0_concat = self.level_0_concat([level_0_conv1t, level_1_conv1])
level_0_conv2t = self.level_0_conv2t(level_0_concat)
level_0_conv3t = self.level_0_conv3t(level_0_conv2t)
level_0_conv4t = self.level_0_conv4t(level_0_conv3t)
model_output = self.model_output(level_0_conv4t)
return model_output我在这里全用了elu激活,也可以修改成别的。模型输入形状是[b,256,256,3],输出是[b,512,512,3],可以将图片高度与宽度翻倍,像素增加。b是batch大小,256是我的模型输入图高度宽度,512是模型输出图高度宽度,这个可以根据自己数据处理时的裁剪的大小来修改。(注意:由于模型对与形状的限制,高与宽必须是16的倍数)
开始训练!
epochs = 10 #迭代数据集次数
optimizer=keras.optimizers.Adam(learning_rate=0.0000003) #优化器
repairer = Repairer()
#加载曾经的权重
if os.path.exists('repairer.h5'):
print('加载权重...')
repairer.load_weights('repairer.h5')
#训练
for epoch in range(epochs):
total_loss = []
for n,(x,y) in enumerate(ds):
with tf.GradientTape() as tape:
y_pred = repairer(x)
loss = keras.backend.mean(keras.backend.abs(y - y_pred))
grads = tape.gradient(loss, repairer.trainable_variables)
optimizer.apply_gradients(zip(grads, repairer.trainable_variables))
total_loss.append(loss)
print('epoch:',epoch,' , loss:',sum(total_loss)/(n+1))
repairer.save_weights('repairer.h5')训练并且自动保存模型权重文件,如果当前文件夹已经有模型权重文件,则加载并开始训练
生成清晰图片
#生成清晰图片保存到当前文件夹
#注意输入图片的大小,必须把图片像素裁剪成16的倍数(高宽可以不一样)
test_pic_bin = tf.io.read_file('xxx.jpg') #读取要被清晰化的图片路径
test_pic = tf.io.decode_image(test_pic_bin, channels=3) #解码图片
test_pic = tf.image.convert_image_dtype(test_pic, tf.float32) #转为float32给模型训练
tshape = test_pic.shape #获取图片形状
x_tshape = int(tshape[1]/16)*16 #输入高度,将把图像微微裁剪一点点(因为要满足16的倍数)
y_tshape = int(tshape[0]/16)*16 #输入宽度,将把图像微微裁剪一点点(因为要满足16的倍数)
print(y_tshape,x_tshape)
test_pic = tf.image.random_crop(test_pic, [y_tshape, x_tshape, 3]) #裁剪
test_pic = tf.expand_dims(test_pic, axis=0) #增加一个batch维度,便于输入模型
output = repairer(test_pic) #输入模型,生成结果
output_image = tf.clip_by_value(output,0,1) #把数值裁剪到0-1的范围内
output_image = tf.image.convert_image_dtype(output_image, dtype=tf.uint8) #转为unit8
output_image = tf.image.encode_png(output_image[0]) #编码
tf.io.write_file(r'test1.png', output_image) #保存输出的清晰图片到文件夹
需要将图片高度和宽度裁剪为16的倍数,所以先获取图片形状,将其除16,并用int化为整数,再乘16,以这个尺寸为传入图像,只会比原图稍微小一点点。
因为颜色值的范围是0-1之间,而模型有可能会预测出超出这个范围的数值,所以需要把模型输出的值全部裁剪到0-1的范围,再进行编码。
个人测试效果如下


可以看出来,在简单的任务上,该模型可以弱化锯齿效果,使线条更平滑。


将风景图放大后,可以发现物体边缘模糊的地方变得更清晰一些了。
本人水平有限,文中的不足与错误之处,恳请大家纠正。
如果我的文章对您有用,请点个赞或随意打赏。您的支持将鼓励我继续创作!