Windows10安装和使用Tensorflow1.x Object Detection API
文章目录
- Windows10安装和使用Tensorflow1.x Object Detection API
- 一、前言
- 二、环境安装
-
- 环境说明
- 1.显卡检测
- 2.显卡驱动安装
- 2.protocolbuffers安装
- 3.Python环境安装
- 4.Tensorflow-gpu安装
- 5.Object-detection安装
-
- 安装 visual-cpp-build-tools
- 安装 cocoapi
- 安装 object-detection api
- 安装 jupyter
- 编写测试程序
- 运行官方例子
- 三、自定义目标检测
-
- 流程说明
- 前期准备
- 1.收集和标注图片
-
- 收集图片
- 标注图片
- 2.创建训练集和测试集
-
- XML转CSV
- 生成record文件
- 3.训练模型
-
- 标注映射文件
- 训练配置文件
- 开始训练
- 4.目标检测
-
- 导出pb模型
- 执行目标检测
- 四、其它
-
- 1.VS安装
- 2.CUDA安装
- 3.cuDNN安装
Windows10安装和使用Tensorflow1.x Object Detection API
一、前言
- TensorFlow Object Detection API 是一个基于TensorFlow的开源框架,可轻松构建,训练和部署对象检测模型。
TensorFlow Object Detection API:https://github.com/tensorflow/models/tree/master/research/object_detection
object-detection api 安装:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1.md
TensorFlow 1 Detection Model Zoo:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md
LabelImg(github):https://github.com/tzutalin/labelImg
github 镜像站点:https://hub.fastgit.org
TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10:https://github.com/EdjeElectronics/TensorFlow-Object-Detection-API-Tutorial-Train-Multiple-Objects-Windows-10
Anacoda安装和使用:https://blog.csdn.net/u011424614/article/details/105579502
- 版本选择
Tensorflow GPU 支持:
1.总体介绍:https://www.tensorflow.org/install/gpu?hl=zh-cn
2.版本对应软件包:https://www.tensorflow.org/install/source?hl=zh-cn#linux
检测GPU是否支持CUDA:
1.新显卡查询:https://developer.nvidia.com/cuda-gpus
2.旧显卡查询:https://developer.nvidia.com/cuda-legacy-gpus
二、环境安装
环境说明
-
操作系统:Windows 10 专业版
-
虚拟环境:Anaconda
-
开发工具:PyCharm 2020.1
-
根据所使用的 tensorflow 版本和操作系统,安装相应的 GPU 软件包,当前以
tensorflow-1.x为例
经过测试的构建配置:https://www.tensorflow.org/install/source?hl=zh-cn#linux
| 版本 | Python版本 | 编译器 | 构建工具 | cuDNN | CUDA |
|---|---|---|---|---|---|
| tensorflow_gpu-1.15.0 | 2.7、3.3-3.7 | GCC 7.3.1 | Bazel 0.26.1 | 7.4 | 10.0 |
1.显卡检测
-
本地查看显卡:
此电脑(右击) –管理–设备管理–显示适配器 -
Nvidia 官网查看 GPU 是否支持CUDA,并查看对应 GPU 的计算能力
CUDA GPU:https://developer.nvidia.com/cuda-gpus
| GPU | Compute Capability |
|---|---|
| NVIDIA Quadro P4000 | 6.1 |
2.显卡驱动安装
- 下载并安装本机的显卡驱动(已安装的可以跳过)
资源下载:https://www.nvidia.com/drivers

- 下载完成后,Windows 软件安装
2.protocolbuffers安装
protocolbuffers 资源下载:https://hub.fastgit.org/protocolbuffers/protobuf/releases
- 下载并解压 protoc-3.15.6-win64.zip
- 配置环境变量:PATH 中配置解压路径;例如:
C:\protoc-3.15.6-win64\bin
3.Python环境安装
- 使用 Anaconda 创建 python 环境
Anacoda安装和使用:https://blog.csdn.net/u011424614/article/details/105579502
- 创建虚拟环境
#-- 查看虚拟环境
> conda info -e
#-- 创建 python 的虚拟环境
> conda create -n tf1-env python=3.7
#-- 切换/激活 环境
> activate tf1-env
4.Tensorflow-gpu安装
pip 设置镜像源:https://blog.csdn.net/u011424614/article/details/114199102
- windows 开始菜单 – Anaconda Prompt
#-- 切换/激活 环境
> activate tf1-env
#-- 查看环境已安装的包列表
> conda list
#-- 安装 tensorflow (包含 cuda 和 cudnn 环境)
> conda install tensorflow-gpu=1
- 当前文章 tensorflow-gpu 版本:1.15.0
5.Object-detection安装
安装 visual-cpp-build-tools
Microsoft C++ Build Tools下载:https://download.microsoft.com/download/5/f/7/5f7acaeb-8363-451f-9425-68a90f98b238/visualcppbuildtools_full.exe
- 下载并安装 Microsoft C++ Build Tools
安装 cocoapi
- windows 开始菜单 – Visual C++ Build Tools – Visual C++ 2015 x64 Native Build Tools Command Prompt (以管理员身份运行)
- Native Build Tools Command Prompt 窗口中输入指令
#-- 切换/激活 环境
> activate tf1-env
#-- 安装 git 模块
> conda install git
#-- 安装 cython 模块
> conda install cython
#-- 下载并编译 cocoapi
> pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
#-- (备用) 镜像站点下载并编译 cocoapi
> pip install git+https://hub.fastgit.org/philferriere/cocoapi.git#subdirectory=PythonAPI
安装 object-detection api
镜像站点下载 models:https://hub.fastgit.org/tensorflow/models/tree/master/research/object_detection
#-- 下载 models
> git clone https://github.com/tensorflow/models.git
#-- (备用)下载 models
> git clone https://hub.fastgit.org/tensorflow/models.git
> cd models/research
#-- 编译 protos.
> protoc object_detection/protos/*.proto --python_out=.
#-- 安装 TensorFlow Object Detection API.
> copy .\object_detection\packages\tf1\setup.py .\setup.py
> python -m pip install --use-feature=2020-resolver .
#-- 测试安装是否成功
> python object_detection/builders/model_builder_tf1_test.py
安装 jupyter
#-- 安装 ipykernel (用于快速切换jupyter的虚拟环境)
> conda install ipykernel
#-- 安装 nb_conda (用于快速切换jupyter的虚拟环境)
> conda install nb_conda
#-- 运行 jupyter
> jupyter notebook
- 自动打开浏览器窗口:
http://localhost:8888/tree
jupyter notebook 快捷键说明:工具栏 – Help – Keyboard Shortcuts
上方插入cell:a
下方插入cell:b
删除cell:dd
执行本单元代码,并跳到下一单元:Shift + Enter
执行本单元代码,留在本单元:Ctrl + Enter
编写测试程序
tensorflow官网 - 使用 GPU:https://www.tensorflow.org/guide/gpu?hl=zh-cn
- jupyter 浏览器页面 –
New–tf1-env
import tensorflow as tf
# 打印出可用的 GPU 数量
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
运行官方例子
- object-detection 官方例子目录:object_detection\colab_tutorials
- jupyter notebook 打开 object_detection_tutorial.ipynb
- jupyter notebook 打开 ipynb 文件后切换环境:工具栏 – Kernel – Change Kernel – 选择环境
三、自定义目标检测
流程说明

前期准备
- 创建目录:models\research\object_detection\my_pkg
- images :存放训练集和测试集的图片和标注文件
- train 文件夹:存放训练图片和标注文件
- test 文件夹:存放测试图片和标注文件
- training :训练配置文件和训练产生的过程文件
- log 文件夹:存放训练生成的模型文件
- inference_graph :pb模型导出文件夹
- 激活 python 环境(详情查看 二、环境安装)
> activate tf1-env
> cd models\research\object_detection
- 下载 Faster-RCNN-Inception-V2
TensorFlow 1 Detection Model Zoo:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md
Faster-RCNN-Inception-V2:http://download.tensorflow.org/models/object_detection/faster_rcnn_inception_v2_coco_2018_01_28.tar.gz
- 将 faster_rcnn_inception_v2_coco_2018_01_28.tar.gz 解压到 my_pkg 中
1.收集和标注图片
收集图片
- 可以收集拍摄或网络下载
- 图片数量建议 200 张以上
- 图片越大(占用空间和分辨率),训练的时间越长
- 80% 作为训练图,20%作为测试图
标注图片
LabelImg(github):https://github.com/tzutalin/labelImg
- 使用 LabelImg 标注图片,并生成标注文件(xml 格式)
- 将 图片 和 标注文件 保存到 images/train 和 images/test 两个文件夹中
2.创建训练集和测试集
- 通过标注图片创建训练集和测试集
XML转CSV
- 创建 my_pkg / xml_to_csv.py
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
for folder in ['train','test']:
image_path = os.path.join(os.getcwd(), ('images/' + folder))
xml_df = xml_to_csv(image_path)
xml_df.to_csv(('images/' + folder + '_labels.csv'), index=None)
print('Successfully converted xml to csv.')
main()
- 执行脚本
#-- 执行目录:models\research\object_detection\my_pkg
> python xml_to_csv.py
- csv 文件生成在 my_pkg \ images 文件夹中,分别是 train_labels.csv 和 test_labels.csv
生成record文件
- 创建 my_pkg / generate_tfrecord.py
"""
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
# Create test data:
python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
from tensorflow.python.framework.versions import VERSION
if VERSION >= "2.0.0a0":
import tensorflow.compat.v1 as tf
else:
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('image_dir', '', 'Path to the image directory')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'nine':
return 1
elif row_label == 'ten':
return 2
elif row_label == 'jack':
return 3
elif row_label == 'queen':
return 4
elif row_label == 'king':
return 5
elif row_label == 'ace':
return 6
else:
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), FLAGS.image_dir)
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()
- 编辑 generate_tfrecord.py , 将标签修改为 标注图片 步骤中的标注
def class_text_to_int(row_label):
if row_label == 'nine':
return 1
elif row_label == 'ten':
return 2
elif row_label == 'jack':
return 3
elif row_label == 'queen':
return 4
elif row_label == 'king':
return 5
elif row_label == 'ace':
return 6
else:
None
- 执行脚本
#-- 执行目录:models\research\object_detection\my_pkg
> python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
> python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
- record 文件生成在 my_pkg 文件夹中,分别是 train.record 和 test.record
- 将 record 文件剪切到 my_pkg \ training 文件夹中
3.训练模型
标注映射文件
-
创建 my_pkg / training / labelmap.pbtxt
id 和 name 对应 generate_tfrecord.py 脚本(生成 record 文件)中 class_text_to_int 方法的内容
参考:models \ research \ object_detection \ data
item {
id: 1
name: 'nine'
}
item {
id: 2
name: 'ten'
}
item {
id: 3
name: 'jack'
}
item {
id: 4
name: 'queen'
}
item {
id: 5
name: 'king'
}
item {
id: 6
name: 'ace'
}
训练配置文件
-
拷贝 my_pkg \ faster_rcnn_inception_v2_coco_2018_01_28 \ pipeline.config 至 my_pkg \ training
-
编辑 pipeline.config
-
第 3 行:num_classes 标注的数量
num_classes: 6
-
第 83 行:batch_size 设置批量处理的数量,根据 GPU 的内存调整
batch_size: 1
-
第 91 行:manual_step_learning_rate
initial_learning_rate: 0.0005 schedule { step: 1 learning_rate: .0005 } schedule { step: 900000 learning_rate: .00005 } schedule { step: 1200000 learning_rate: .000005 } -
第112 行:fine_tune_checkpoint 配置 前期准备 的 faster_rcnn_inception_v2_coco_2018_01_28 解压目录中的文件
fine_tune_checkpoint: "【全路径】/faster_rcnn_inception_v2_coco_2018_01_28/model.ckpt"
-
第 114 行:num_steps 设置训练步数
num_steps: 50000
-
第 116 行:train_input_reader
label_map_path: "【全路径】/labelmap.pbtxt"input_path: "【全路径】/train.record"
-
第 122 行:eval_config
num_examples: 67设置为测试集的图片数量
-
第 127 行:eval_input_reader
label_map_path: "【全路径】/labelmap.pbtxt"input_path: "【全路径】/test.record"
开始训练
- 执行脚本
#-- 执行目录:models\research
> python object_detection/legacy/train.py --pipeline_config_path=object_detection/my_pkg/training/pipeline.config --train_dir=object_detection/my_pkg/training/log
#-- (备用)动态设置训练步数
> python object_detection/legacy/train.py --pipeline_config_path=object_detection/my_pkg/training/pipeline.config --train_dir=object_detection/my_pkg/training/log --num_train_steps=50000 --sample_1_of_n_eval_examples=1 --alsologtostderr
- 查看监控面板
#-- 执行目录:models\research
> tensorboard --logdir=【全路径】/object_detection/my_pkg/training/log
建议将 loss 值至少训练到 0.8 以下,或者最好稳定在 0.05 以下(注意:使用不同模型,这个数值会变化)
4.目标检测
导出pb模型
- –trained_checkpoint_prefix model.ckpt-xxxxx:xxxxx 为训练模型对应的数值
- –output_directory 模型输出目录
#-- 执行目录:models\research
> python object_detection/export_inference_graph.py --input_type image_tensor --pipeline_config_path object_detection/my_pkg/training/log/pipeline.config --trained_checkpoint_prefix object_detection/my_pkg/training/log/model.ckpt-55250 --output_directory object_detection/my_pkg/inference_graph
执行目标检测
- 创建 object_detection \ my_pkg \ Object_detection_image.py
######## Image Object Detection Using Tensorflow-trained Classifier #########
#
# Author: Evan Juras
# Date: 1/15/18
# Description:
# This program uses a TensorFlow-trained neural network to perform object detection.
# It loads the classifier and uses it to perform object detection on an image.
# It draws boxes, scores, and labels around the objects of interest in the image.
## Some of the code is copied from Google's example at
## https://github.com/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb
## and some is copied from Dat Tran's example at
## https://github.com/datitran/object_detector_app/blob/master/object_detection_app.py
## but I changed it to make it more understandable to me.
# Import packages
import os
import cv2
import numpy as np
import tensorflow as tf
import sys
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
# Import utilites
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
# Name of the directory containing the object detection module we're using
MODEL_NAME = 'inference_graph'
IMAGE_NAME = 'test1.jpg'
# Grab path to current working directory
CWD_PATH = os.getcwd()
# Path to frozen detection graph .pb file, which contains the model that is used
# for object detection.
PATH_TO_CKPT = os.path.join(CWD_PATH,MODEL_NAME,'frozen_inference_graph.pb')
# Path to label map file
PATH_TO_LABELS = os.path.join(CWD_PATH,'training','labelmap.pbtxt')
# Path to image
PATH_TO_IMAGE = os.path.join(CWD_PATH,IMAGE_NAME)
# Number of classes the object detector can identify
NUM_CLASSES = 6
# Load the label map.
# Label maps map indices to category names, so that when our convolution
# network predicts `5`, we know that this corresponds to `king`.
# Here we use internal utility functions, but anything that returns a
# dictionary mapping integers to appropriate string labels would be fine
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# Load the Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
sess = tf.Session(graph=detection_graph)
# Define input and output tensors (i.e. data) for the object detection classifier
# Input tensor is the image
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Output tensors are the detection boxes, scores, and classes
# Each box represents a part of the image where a particular object was detected
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represents level of confidence for each of the objects.
# The score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
# Number of objects detected
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Load image using OpenCV and
# expand image dimensions to have shape: [1, None, None, 3]
# i.e. a single-column array, where each item in the column has the pixel RGB value
image = cv2.imread(PATH_TO_IMAGE)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_expanded = np.expand_dims(image_rgb, axis=0)
# Perform the actual detection by running the model with the image as input
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict={image_tensor: image_expanded})
# Draw the results of the detection (aka 'visulaize the results')
vis_util.visualize_boxes_and_labels_on_image_array(
image,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8,
min_score_thresh=0.60)
# All the results have been drawn on image. Now display the image.
cv2.imshow('Object detector', image)
# Press any key to close the image
cv2.waitKey(0)
# Clean up
cv2.destroyAllWindows()
-
第 33 行:MODEL_NAME = ‘inference_graph’
- 设置模型名称
-
第 34 行:IMAGE_NAME = ‘test1.jpg’
- 设置目标检测图
-
第 41 行:PATH_TO_CKPT = os.path.join(CWD_PATH,MODEL_NAME,‘frozen_inference_graph.pb’)
- 设置载入模型的名称
-
第 44 行:PATH_TO_LABELS = os.path.join(CWD_PATH,‘training’,‘labelmap.pbtxt’)
- 设置标注文件目录和标注文件名称
-
执行脚本
#-- 执行目录:models\research\object_detection\my_pkg
> python Object_detection_image.py
执行成功后,程序会通过 opencv 打开识别成功的结果图
四、其它
1.VS安装
CUDA Installation Guide for Microsoft Windows:https://docs.nvidia.com/cuda/archive/10.0/cuda-installation-guide-microsoft-windows/index.html
- CUDA 10.0中的 Windows 编译器支持

-
当前文章 VS 版本:2017
-
安装时,勾选 使用 C++ 的桌面开发
2.CUDA安装
如果 CUDA 安装失败,请先安装 VS;VS版本选择如上一章节所述
如何删除已有版本:控制面板 – 程序 – 卸载程序 :删除 NVIDIA 开头的程序
(注意)以下程序为显卡驱动程序,可以不用删除
- NVIDIA HD 音频驱动程序
- NVIDIA RTX Desktop Manager
- NVIDIA 图形驱动程序
- 显卡支持的 CUDA 最高版本
- windows 桌面(右击)-- NVIDIA 控制面板 – 系统信息(左下角)
- NVCUDA64.DLL 对应的产品名称就是显卡支持的 CUDA 最高版本
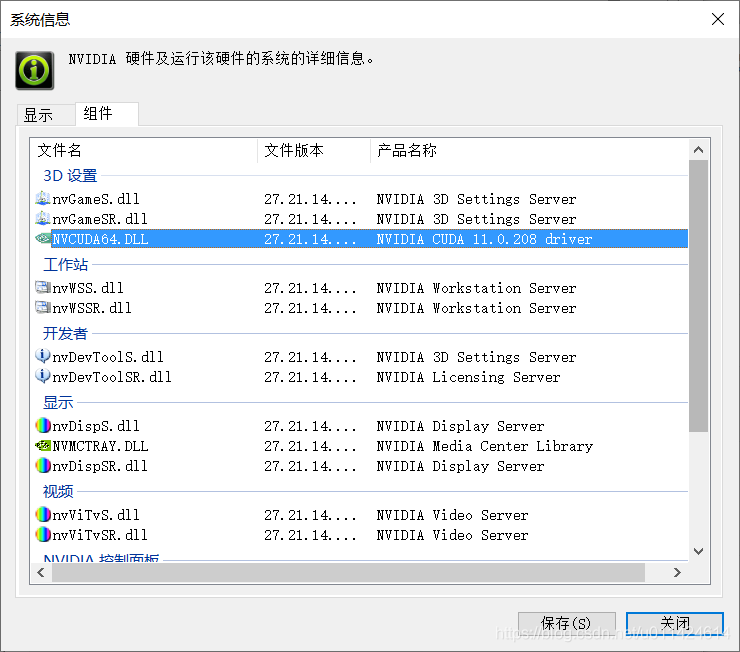
- 下载并安装 CUDA
Latest version(最新版本):https://developer.nvidia.com/cuda-downloads
CUDA Toolkit Archive(历史版本):https://developer.nvidia.com/cuda-toolkit-archive
-
当前文章 CUDA 版本:10.0
-
下载完成后,Windows 软件安装(复制下载按钮的链接,可使用迅雷下载)
注意:开始运行 exe 的目录为解压提取目录,非安装目录
3.cuDNN安装
需要先安装 CUDA
- 下载并安装 cuDNN
Latest version(最新版本):https://developer.nvidia.com/cudnn
cuDNN Archive(历史版本):https://developer.nvidia.com/rdp/cudnn-archive
-
需要先登陆 Nvidia 账户
-
当前文章 cuDNN 版本:7.6.5 (官网一般会说明 cuDNN 支持哪个版本的 CUDA)
-
将解压文件夹 cuda 下 的
bin、include和lib目录,拷贝到 CUDA 的文件夹中 -
例如:CUDA 的默认路径:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0