全卷积网络用于手语识别
Fully Convolutional Networks for Continuous Sign Language Recognition
| 年份 | 识别类型 | 输入数据类型 | 手动特征 | 非手动特征 | Fullframe | 数据集 | 识别对象 | 关键词 | 讨论 | paper的总结 | paper的展望 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020 | 连续语句 | RGB | Shape(手形) | Head(头) | Bodyjoints(身体关节)、RGB | Phoenix14、Phoenix14-T、CSL | DGS(德语)、CSL(汉语) | Continuous sign language recognition;Fully convolutional network; Joint training; Online recognition | 在 FCN 的基础上,我们提出的网络只需连续地传入(足够多的)推断出的几个帧,就可以组合所有的中间输出以给出与真实值相匹配的最终识别结果。我们使用此技术来在 Concat All 场景中测试,在该场景中,所有测试样本被连接在一起作为一个大样本。可惜,基于 LSTM 的模型无法在 Concat All 场景进行测试,因为大样本内存容量太大,无法作为输入。表5的所有结果表明,提出的网络具有更强的泛化能力和更好的识别灵活性,适用于复杂的现实认知场景。FCN 结构使得所提出的网络能够显著减少识别所需的存储器使用量。同时,在 Split 和 Concat 场景中的实验结果表明,该方法不但能识别孤立词手语的意思,还能识别出手语短语和段落的含义。我们可以从 Split 场景中的结果进一步得出结论,在识别过程中不需要等待所有手语 gloss 的到来,因为只要对所提出的网络有足够的帧可用,就可以给出准确的中间(部分)识别结果。有了这一特性,我们的方法可以长时间的逐字提供中间结果,从人机交互的角度来看,这对 SLR 用户来说是非常友好的。这些特性使得所提出的网络在在线识别方面有很好的应用前景。补充演示视频中显示了可视化演示。 | 1、首次提出了一种端到端训练的全卷积网络,该网络无需预先训练即可用于连续手语识别。2、引入联合训练的 GFE 模型来增强特征的代表性。实验结果表明,(1)该网络在基于 RGB 方法的基准数据集上取得了最好的性能。(2)对于基于 LSTM 的网络在实际场景中的识别,该网络达到了一致的性能,并表现出许多极大的优势。(3)这些优势使我们提出的网络鲁棒性好,可以进行在线识别。 | 1、未来连续手语识别的一个可能的研究方向是利用一些光泽是字母组合的事实来加强监督;然而,这可能需要额外的标记预处理和手语专业知识。2、该网络具有更好的 gloss 识别精度,在手语翻译(SLT)中有很好的研究前景。3、我们希望所提出的网络能够启发未来序列识别任务的研究,以探索 FCN 结构作为基于 LSTM 的模型的替代方案,特别是对于那些训练数据有限的任务。 |
文章目录
- Abstract.
- 1 Introduction
- 2 Related Work
- 3 Method
-
- 3.1 Main stream design
-
- Frame feature encoder
- Two-level gloss feature encoder
- CTC decoder
- 3.2 Gloss feature enhancement
-
- Alignment proposal
- Joint training with weighted cross-entropy
- 4 Experiments
-
- 4.1 Experimental setup
-
- Dataset
- Evaluation metric
- Implementation details
- 4.2 Results
- 4.3 Ablation studies
-
- Temporal feature encoder
- GFE module
- 4.4 Online recognition
-
- Simulating experiments
- Discussion
- 5 Conclusions
- paper原文链接点击下载
- paper源码(一作、二作、三作都没有源码,建议参考其他 paper)
Abstract.
Continuous sign language recognition (SLR) is a challenging task that requires learning on both spatial and temporal dimensions of signing frame sequences. Most recent work accomplishes this by using CNN and RNN hybrid networks. However, training these networks is generally non-trivial, and most of them fail in learning unseen sequence patterns, causing an unsatisfactory performance for online recognition. In this paper, we propose a fully convolutional network (FCN) for online SLR to concurrently learn spatial and temporal features from weakly annotated video sequences with only sentence-level annotations given. A gloss feature enhancement (GFE) module is introduced in the proposed network to enforce better sequence alignment learning. The proposed network is end-to-end trainable without any pre-training. We conduct experiments on two large scale SLR datasets. Experiments show that our method for continuous SLR is effective and performs well in online recognition.
Keywords:Continuous sign language recognition; Fully convolutional network; Joint training; Online recognition
连续手语识别(SLR)是一项具有挑战性的任务,需要在手语帧序列的空间和时间维度上进行学习。最近的工作是通过使用CNN和RNN混合网络来实现的。但是,训练这些网络通常并非易事,并且大多数网络无法学习看不见的序列模式,从而导致在线识别的性能不尽人意。在本文中,我们提出了一种用于在线 SLR 的完全卷积网络(FCN),可以从仅带有句子级注释的弱注释视频序列中同时学习空间和时间特征。在提出的网络中引入了gloss feature 增强(GFE)模块,以加强更好的序列比对学习。提出的网络可以进行端到端的训练,而不需要任何预训练。我们对两个大型 SLR 数据集进行了实验。实验表明,我们的连续语句手语识别方法是有效的,并且在在线识别中表现良好。
**关键字:**连续语句手语识别;全卷积网络;联合训练;在线识别
| 研究对象 | 研究方法 | 数据集 | 研究成果 |
|---|---|---|---|
| 连续语句手语识别 | 在线全卷积网络端到端训练;gloss feature 增强(GFE)模块;不需要预训练 |
gloss:光泽作为物体的表面特性,取决于表面对光的镜面反射能力。(百度百科)
1 Introduction
Sign language is a common communication method for people with disabled hearing. It composes of a variety range of gestures, actions, and even facial emotions. In linguistic terms, a gloss is regarded as the unit of the sign language [27]. To sign a gloss, one may have to complete one or a series of gestures and actions. However, many glosses have very similar gestures and movements because of the richness of the vocabulary in a sign language. Also, because different people have different action speeds, a same signing gloss may have different lengths. Not to mention that different from spoken languages, sign language like ASL [22] usually does not have a standard structured grammar. These facts place additional difficulties in solving continuous SLR because it requires the model to be highly capable of learning spatial and temporal information in the signing sequences.
手语是听力障碍人士的常用交流方式。它由各种手势,动作甚至面部表情组成。用语言学术语来讲,一个 gloss 被视为手语的单位[27]。 对于手语 gloss 而言,必须识别一个或一系列的手势和动作。但是,由于手语中词汇的丰富性,许多 gloss 具有非常相似的手势和动作。同样,由于不同的人具有不同的动作速度,因此相同的手语 gloss 可能具有不同的长度。 更不用说与口语不同的是,像 ASL [22]这样的手语通常没有标准的结构化语法。这些事实为解决连续 SLR 带来了其他困难,因为它要求模型具有高度学习手语序列中的时空信息的能力。
| Good | 批判性吸收 | 参考文献 |
|---|---|---|
| 用语言学术语来说,一个 gloss 被视为手语的单位[27]。 | - | Ong, S., Ranganath, S.: Automatic sign language analysis: A survey and the future beyond lexical meaning. IEEE Transactions on Pattern Analysis and Machine Intelligence 27, 873–91 (2005) |
| 同样,由于不同的人具有不同的动作速度,因此相同的手语 gloss 可能具有不同的长度。 即每个人都有个人专属的手语风格,就像普通人说话一样有不同的习惯 | - | - |
| 手语通常没有标准的结构化语法 | - | - |
Early work on continuous SLR [6,18,34] utilizes hand-crafted features followed by Hidden Markov Models (HMMs) [43,48] or Dynamic Time Warping (DTW) [47] as common practices. More recent approaches achieve state-of-theart results using CNN and RNN hybrid models [4,14,44]. However, we observe that these hybrid models tend to focus on the sequential order of seen signing sequences in the training data but not the glosses, due to the existence of RNN. So, it is sometimes hard for these trained networks to recognize unseen signing sequences with different sequential patterns. Also, training of these models is generally non-trivial, as most of them require pre-training and incorporate iterative training strategy [4], which greatly lengthens the training process. Furthermore, the robustness of previous models is limited to sentence recognition only; most of the methods fail when the test cases are signing videos of a phrase (sentence fragment) or a paragraph (several sentences). Online recognition requires good recognition responses for partial sentences, but these models usually cannot give correction recognition until the signer finishes all the signing glosses in a sentence. Such limitation in robustness makes online recognition almost impossible for CNN and RNN hybrid models.
连续语句手语识别[6,18,34]的早期工作采用了手工制作特征,之后隐马尔可夫模型(HMM)[43,48]或动态时间规整(DTW)[47]作为常用方法。最近的方法是使用 CNN 和 RNN 混合模型获得了最新技术成果[4,14,44]。但是,由于 RNN 的存在,我们发现这些混合模型倾向于集中在训练数据中可见手语序列的顺序上,而不是光泽上。因此,有时这些训练好的网络很难识别具有不同顺序模式的未知的手语序列。同样,对这些模型的训练通常也不是一件容易的事,因为它们中的大多数都需要进行预训练并包含迭代训练策略[4],这极大地延长了训练过程。此外,先前模型的鲁棒性仅限于句子识别;当测试用例对短语(句子片段)或段落(几个句子)的手语视频时,大多数方法都会失败。在线识别要求对部分句子有良好的识别响应,但是在 signer 完成句子中的所有签名修饰之前,这些模型通常无法给出正确的识别。这些限制使得 CNN 和 RNN 混合模型几乎无法在线识别。
| 介绍其他方法:一句话带过早期和后面的工作,重点介绍最近的且是本工作重点比较的 |
|---|
| 时间(早期…之后…) | 论文 | 方法 | 缺点 | 优点 |
|---|---|---|---|---|
| 2015 | Evangelidis, G.D., Singh, G., Horaud, R.: Continuous gesture recognition from articulated poses. In: Proceedings of European Conference on Computer Vision. pp. 595–607 (2015) | 手工制作特征 | - | - |
| 2015 | Koller, O., Forster, J., Ney, H.: Continuous sign language recognition: Towards large vocabulary statistical recognition systems handling multiple signers. Computer Vision and Image Understanding 141, 108–125 (2015) | 手工制作特征 | - | - |
| 2013 | Sun, C., Zhang, T., Bao, B.K., Xu, C., Mei, T.: Discriminative exemplar coding for sign language recognition with kinect. IEEE Transactions on Cybernetics 43, 1418–1428 (2013) | 手工制作特征 | - | - |
| 2016 | Yang, W., Tao, J., Ye, Z.: Continuous sign language recognition using level building based on fast hidden markov model. Pattern Recognition Letters 78, 28–35 (2016) | 隐马尔可夫模型(HMM) | - | - |
| 2016 | Zhang, J., Zhou, W., Xie, C., Pu, J., Li, H.: Chinese sign language recognition with adaptive hmm. In: Proceedings of IEEE International Conference on Multimedia and Expo. pp. 1–6 (2016) | 隐马尔可夫模型(HMM) | ||
| 2014 | Zhang, J., Zhou, W., Li, H.: A threshold-based hmm-dtw approach for continuous sign language recognition. In: Proceedings of International Conference on Internet Multimedia Computing and Service. pp. 237–240 (2014) | 隐马尔可夫模型(HMM) | - | - |
| 时间(最近) | 论文 | 方法 | 缺点 | 优点 |
|---|---|---|---|---|
| 2017 | Cui, R., Liu, H., Zhang, C.: Recurrent convolutional neural networks for continuous sign language recognition by staged optimization. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. pp. 1610–1618 (2017) | CNN 和 RNN 混合模型 | 很难识别具有不同顺序模式的未知的手语序列;训练周期长;鲁棒性差 | - |
| 2018 | Huang, J., Zhou, W., Zhang, Q., Li, H., Li, W.: Video-based sign language recognition without temporal segmentation. In: Proceedings of AAAI Conference on Artificial Intelligence. pp. 2257–2264 (2018) | CNN 和 RNN 混合模型 | 很难识别具有不同顺序模式的未知的手语序列;训练周期长;鲁棒性差 | - |
| 2019 | Yang, Z., Shi, Z., Shen, X., Tai, Y.W.: Sf-net: Structured feature network for continuous sign language recognition. arXiv preprint arXiv:1908.01341 (2019) | CNN 和 RNN 混合模型 | 很难识别具有不同顺序模式的未知的手语序列;训练周期长;鲁棒性差 | - |
In this paper, we propose a fully convolutional network [24] for continuous SLR to address these challenges. The proposed network can be trained end-toend without any pre-training. On top of this, we introduce a GFE module to enhance the representativeness of features. The FCN design enables the proposed network to recognize new unseen signing sentences, or even unseen phrases and paragraphs. We conduct different sets of experiments on two public continuous SLR datasets. The major contribution of this work can be summarized:
-
- We are the first to propose a fully convolutional end-to-end trainable network for continuous SLR. The proposed FCN method models the semantic structure of sign language as glosses instead of sentences. Results show that the proposed network achieves state-of-the-art accuracy on both datasets, compared with other RGB-based methods.
-
- The proposed GFE module enforces additional rectified supervision and is jointly trained along with the main stream network. Compared with iterative training, joint training with the GFE module fastens the training process because joint training does not require additional fine-tuning stages.
-
- The FCN architecture achieves better adaptability in more complex realworld recognition scenarios, where previous LSTM based methods would almost fail. This attribute makes the proposed network able to do online recognition and is very suitable for real-world deployment applications.
在本文中,我们提出了一种用于识别连续语句手语的完卷积网络[24]来解决这些挑战。所提出的网络可以端到端地训练,而不需要任何预训练。在此基础上,我们引入了 GFE 模块来增强特征的代表性。FCN 的设计使提出的网络能够识别新的看不见的手语句子,甚至是看不见的短语和段落。我们在两个公开的连续单反数据集上进行了不同的实验。这项工作的主要贡献可以概括为
-
- 我们首次提出了一种用于连续语句手语识别的可端到端训练的全卷积网络。该方法将手语的语义结构建模为注释而不是句子。结果表明,与其他基于 RGB 的方法相比,提出的网络在两个数据集上都达到了最高的准确率。
-
- 提出的 GFE 模块执行额外的已微调后的监督,并与主流网络一起进行联合培训。与迭代训练相比,GFE 模块联合训练网络加快了训练过程,因为联合训练不需要额外的微调阶段。
-
- FCN 体系结构在更复杂的现实世界识别场景中实现了更好的适应性,而以前基于 LSTM 的方法几乎都失败了。这一特性使得所提出的网络能够进行在线识别,非常适合于实际部署应用。
2 Related Work
There are mainly two scenarios in SLR: isolated SLR and continuous SLR. Isolated SLR mainly focuses on the scenario where glosses have been well segmented temporally. Work in the field generally solves the task with methods such as Hidden Markov Models (HMMs) [10,12,13,29,35,42], Dynamic Time Warping (DTW) [36], and Conditional Random Field (CRF) [40,41]. As for continuous SLR, the task becomes more difficult as it aims to recognize glosses in the scenarios where no gloss segmentation is available but only sentence-level annotations as a whole. Learning separated individual glosses becomes more difficult in the weakly supervised setting. Many approaches propose to estimate the temporal boundary of different glosses first and then apply isolated SLR techniques and sequence to sequence methods [7,16] to construct the sentence.
手语识别主要有两种场景:孤立词手语和连续语句手语。孤立词手语识别主要关注光泽在时序上能被很好地分割的场景。在孤立词手语识别中一般采用隐马尔可夫模型(HMM)[10,12,13,29,35,42]、动态时间规整(DTW)[36]和条件随机场(CRF)[40,41]等方法来解决这一问题。对于连续语句来说,手语识别任务更加困难,因为它的目标是识别情景中的 gloss,因为在情景中,没有对 gloss 分段,只有句子级的手语作为一个整体。在弱监督的环境下,学习分开的个体 gloss 变得更加困难。许多方法建议先估计不同 gloss 的时序边界,然后将孤立词手语识别技术和序列方法应用于连续语句序列[7,16]来构造句子。
| 孤立词手语识别:主要关注 gloss 在时序上能被很好地分割的场景 |
|---|
| 时间 | 论文 | 方法 | 缺点 | 优点 |
|---|---|---|---|---|
| 2017 | Guo, D., Zhou, W., Li, H., Wang, M.: Online early-late fusion based on adaptive hmm for sign language recognition. ACM Transactions on Multimedia Computing, Communications, and Applications 14, 1–18 (2017) | 隐马尔可夫模型(HMM) | - | - |
| 2016 | Guo, D., Zhou, W., Wang, M., Li, H.: Sign language recognition based on adaptive hmms with data augmentation. In: Proceedings of IEEE International Conference on Image Processing. pp. 2876–2880 (2016) | 隐马尔可夫模型(HMM) | - | - |
| 2009 | Han, J., Awad, G., Sutherland, A.: Modelling and segmenting subunits for sign language recognition based on hand motion analysis. Pattern Recognition Letters 30, 623–633 (2009) | 隐马尔可夫模型(HMM) | - | - |
| 2011 | Pitsikalis, V., Theodorakis, S., Vogler, C., Maragos, P.: Advances in phoneticsbased sub-unit modeling for transcription alignment and sign language recognition. In: IEEE Conference on Computer Vision and Pattern Recognition Workshops. pp. 1–6 (2011) | 隐马尔可夫模型(HMM) | - | - |
| 2009 | Theodorakis, S., Katsamanis, A., Maragos, P.: Product-hmms for automatic sign language recognition. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 1601–1604 (2009) | 隐马尔可夫模型(HMM) | - | - |
| 2006 | Yang, R., Sarkar, S.: Gesture recognition using hidden markov models from fragmented observations. In: Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. pp. 766–773 (2006) | 隐马尔可夫模型(HMM) | - | - |
| 2014 | Vela, A.H., Bautista, M., Perez-Sala, X., Ponce-Lpez, V., Escalera, S., Bar, X., Pujol, O., Angulo, C.: Probability-based dynamic time warping and bag-of-visualand-depth-words for human gesture recognition in rgb-d. Pattern Recognition Letters 50, 112–121 (2014) | 动态时间规整(DTW) | - | - |
| 2010 | Yang, H.D., Lee, S.W.: Robust sign language recognition with hierarchical conditional random fields. In: Proceedings of IEEE International Conference on Pattern Recognition. pp. 2202–2205 (2010) | 条件随机场(CRF) | - | - |
| 2006 | Yang, R., Sarkar, S.: Detecting coarticulation in sign language using conditional random fields. In: Proceedings of IEEE International Conference on Pattern Recognition. pp. 108–112 (2006) | 条件随机场(CRF) | - | - |
| 连续语句手语识别:目标是识别情景中的 glosses,因为在情景中,没有对 gloss 分段,只有句子级的手语作为一个整体。 |
|---|
| 时间 | 论文 | 方法 | 缺点 | 优点 |
|---|---|---|---|---|
| 2002 | Fang, G., Gao, W.: A srn/hmm system for signer-independent continuous sign language recognition. In: Proceedings of IEEE International Conference on Automatic Face Gesture Recognition. pp. 312–317 (2002) | 将孤立词手语识别技术和序列方法应用于连续语句序列来构造句子 | - | - |
| 2009 | Kelly, D., McDonald, J., Markham, C.: Recognizing spatiotemporal gestures and movement epenthesis in sign language. In: Proceedings of IEEE International Conference on Image Processing and Machine Vision. pp. 145–150 (2009) | 将孤立词手语识别技术和序列方法应用于连续语句序列来构造句子 | - | - |
Concerning temporal boundary estimation, Cooper and Bowden [3] develop a method to extract similar video regions for inferring alignments in videos by using data mining and head and hand tracking. Farhadi and Forsyth [8] also come up with a method that utilizes HMMs to build a discriminative model for estimating the start and end frames of the glosses in video streams with a voting method. Yin et al. [46] make further improvements by introducing a weakly supervised metric learning framework to address the inter-signer variation problem in real applications of SLR.
关于时序边界估计,Cooper和Bowden [3]提出了一种方法,该方法通过使用数据挖掘和头部和手部跟踪来提取相似的视频区域以达到 inferring alignments。Farhadi和Forsyth[8]还提出了一种方法,该方法利用隐马尔可夫模型(HMM)建立判别模型,用投票法预测视频流中光泽的起始帧和结尾帧。Yen等人[46]在SLR的实际应用中,引入弱监督度量学习框架,解决 signer 之间的差异问题,从而进一步完善SLR。
inferring alignments :预测对齐 ???
| 时间 | 论文 | 方法 | 缺点 | 优点 |
|---|---|---|---|---|
| 2009 | Cooper, H., Bowden, R.: Learning signs from subtitles: A weakly supervised approach to sign language recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. pp. 2568–2574 (2009) | 通过使用数据挖掘和头部和手部跟踪来提取相似的视频区域以达到 inferring alignments | - | - |
| 2006 | Farhadi, A., Forsyth, D.: Aligning asl for statistical translation using a discriminative word model. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. pp. 1471–1476 (2006) | 利用隐马尔可夫模型(HMM)建立判别模型,用投票法预测视频流中光泽的起始帧和结尾帧 | - | - |
| 2015 | Yin, F., Chai, X., Zhou, Y., Chen, X.: Weakly supervised metric learning towards signer adaptation for sign language recognition. In: Proceedings of British Machine Vision Conference. pp. 35.1–35.12 (2015) | 引入弱监督度量学习框架,解决 signer 之间的差异问题 | - | - |
As for sequence to sequence methods, much work follows the framework used in the topic of speech recognition [25,33], handwriting recognition [23,32], and video captioning [39]. Specifically, an encoder module is responsible for extracting features in the input video frame sequences, and a CTC module acts as a cost function to learn the ground truth sequences. This framework also shows good performance on continuous SLR, and more recent work applies CNN and RNN hybrid models to infer gloss alignments implicitly [2,14,26,30]. However, RNNs are sometimes more sensitive to the sequential order than the spatial features. As a result, these models tend to learn much about the sequential signing patterns but little about the glosses (words), causing the failure of the recognition for unseen phrases and paragraphs.
至于序列到序列方法,许多工作遵循语音识别[25,33]、手写识别[23,32]和视频字幕[39]领域中使用的框架。具体地,编码器模块负责从输入视频帧序列中提取特征,而 CTC 模块充当学习真实标签序列的代价函数。这个框架在连续语句识别上表现出了良好的性能,最近的工作是应用 CNN 和 RNN 混合模型来隐式推断 gloss 对齐[2,14,26,30]。然而, RNN 神经网络有时对顺序比空间特征更敏感,因此,这些模型往往对顺序手势模式学习较多,而对注释(词)学习较少,从而导致对看不见的短语和段落的识别失败。
unseen:看不见的 ???还是未训练过的手语 ???
| 时间 | 论文 | 方法 | 缺点 | 优点 |
|---|---|---|---|---|
| 2015 | Miao, Y., Gowayyed, M., Metze, F.: Eesen: End-to-end speech recognition using deep rnn models and wfst-based decoding. In: IEEE Conference on Automatic Speech Recognition and Understanding Workshops. pp. 167–174 (2015) | 借鉴语音识别框架 | - | - |
| 2015 | Sak, H., Senior, A., Rao, K., rsoy, O., Graves, A., Beaufays, F., Schalkwyk, J.: Learning acoustic frame labeling for speech recognition with recurrent neural networks. In: Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 4280–4284 (2015) | 借鉴语音识别框架 | - | - |
| 2007 | Liwicki, M., Graves, A., Bunke, H., Schmidhuber, J.: A novel approach to on-line handwriting recognition based on bidirectional long short-term memory networks. In: Proceedings of International Conference on Document Analysis and Recognition. pp. 367–371 (2007) | 借鉴手写识别框架 | - | - |
| 2017 | Puigcerver, J.: Are multidimensional recurrent layers really necessary for handwritten text recognition? In: Proceedings of International Conference on Document Analysis and Recognition. pp. 67–72 (2017) | 借鉴手写识别框架 | - | - |
| 2018 | Wang, B., Ma, L., Zhang, W., Liu, W.: Reconstruction network for video captioning. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. pp. 7622–7631 (2018) | 借鉴视频字幕框架 | - | - |
| 2017 | Camgoz, N.C., Hadfield, S., Koller, O., Bowden, R.: Subunets: End-to-end hand shape and continuous sign language recognition. In: Proceedings of IEEE International Conference on Computer Vision. pp. 3075–3084 (2017) | 应用 CNN 和 RNN 混合模型来隐式推断 gloss 对齐 | 然而, RNN 神经网络有时对顺序比空间特征更敏感,因此,这些模型往往对顺序手势模式学习较多,而对注释(词)学习较少,从而导致对看不见的短语和段落的识别失败。 | - |
| 2018 | Huang, J., Zhou, W., Zhang, Q., Li, H., Li, W.: Video-based sign language recognition without temporal segmentation. In: Proceedings of AAAI Conference on Artificial Intelligence. pp. 2257–2264 (2018) | 应用 CNN 和 RNN 混合模型来隐式推断 gloss 对齐 | 然而, RNN 神经网络有时对顺序比空间特征更敏感,因此,这些模型往往对顺序手势模式学习较多,而对注释(词)学习较少,从而导致对看不见的短语和段落的识别失败。 | - |
| 2016 | Molchanov, P., Yang, X., Gupta, S., Kim, K., Tyree, S., Kautz, J.: Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural networks. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. pp. 4207–4215 (2016) | 应用 CNN 和 RNN 混合模型来隐式推断 gloss 对齐 | 然而, RNN 神经网络有时对顺序比空间特征更敏感,因此,这些模型往往对顺序手势模式学习较多,而对注释(词)学习较少,从而导致对看不见的短语和段落的识别失败。 | - |
| 2018 | Pu, J., Zhou, W., Li, H.: Dilated convolutional network with iterative optimization for continuous sign language recognition. In: Proceedings of International Joint Conference on Artificial Intelligence. pp. 885–891 (2018) | 应用 CNN 和 RNN 混合模型来隐式推断 gloss 对齐 | 然而, RNN 神经网络有时对顺序比空间特征更敏感,因此,这些模型往往对顺序手势模式学习较多,而对注释(词)学习较少,从而导致对看不见的短语和段落的识别失败。 | - |
| 借鉴语音识别的框架来处理手语识别和我的想法不谋而合,我也同样是想用隐马尔可夫(HHM)来预测连续语句手语。 |
|---|
3 Method
Formally, the proposed network aims to learn a mapping H : X ↦ Y H: \mathcal{X} \mapsto \mathcal{Y} H:X↦Y that can transform an input video frame sequence X \mathcal{X} X to a target sequence Y \mathcal{Y} Y . The feature extraction contains two main steps: a frame feature encoder and a two-level gloss feature encoder. On top of them, a gloss feature enhancement (GFE) module is introduced to enhance the feature learning. An overview of the proposed network is shown in Figure 1.
 Fig. 1. Overview of the proposed network. The network is fully convolutional and divides the feature encoding process into two main steps. A GFE module is introduced to enhance the feature learning
Fig. 1. Overview of the proposed network. The network is fully convolutional and divides the feature encoding process into two main steps. A GFE module is introduced to enhance the feature learning
形式上,提出的网络旨在学习一种映射 H : X ↦ Y H: \mathcal{X} \mapsto \mathcal{Y} H:X↦Y,该映射可以将输入视频帧序列 X \mathcal{X} X 转换为目标序列 Y \mathcal{Y} Y。特征提取包括两个主要步骤: frame feature 编码器和 two-level gloss feature 编码器。在此基础上,引入了==光泽特征增强(GFE)==模块来增强特征学习。提出的网络整体如图1所示。
Fig. 1. 提出的网络整体图。该网络是全卷积的网络结构,并将特征编码过程分为两个主要步骤。引入光泽特征增强(GFE)模块来增强特征学习。
3.1 Main stream design
Frame feature encoder
Frame feature encoder. The proposed network first encodes spatial features of the input RGB frames. The frame feature encoder S {S} S composes of a convolutional backbone S c n n S_{c n n} Scnn to extract features in the frames and a global average pooling layer S g a p S_{g a p} Sgap to compress the spatial features into feature vectors. Formally, each signing sequence is a tensor with shape ( t {t} t, c {c} c, h {h} h, w {w} w), where t {t} t denotes the length of the sequence, c {c} c denotes the number of channels, and h {h} h, w {w} w denotes the height and width of the frames. The process of encoder S {S} S can be described as:
{ s } t × f s = S ( { x } t × c × h × w ) = S g a p ( S c n n ( { x } t × c × h × w ) ) \{s\}^{t \times f_{s}}=S\left(\{x\}^{t \times c \times h \times w}\right)=S_{g a p}\left(S_{c n n}\left(\{x\}^{t \times c \times h \times w}\right)\right) {s}t×fs=S({x}t×c×h×w)=Sgap(Scnn({x}t×c×h×w)). (1)
The output is of shape { s } t × f s \{s\}^{t \times f_{s}} {s}t×fs . Note that frame feature encoder treats each frame independently for the frame (spatial) feature learning.
帧特征编码器. 该网络首先对输入的 RGB 帧的空间特征进行编码。帧特征编码器 S {S} S 由用于提取帧中特征的基础卷积网络 S c n n S_{c n n} Scnn 和用于将空间特征压缩为特征向量的全局平均池层 S g a p S_{g a p} Sgap 组成。形式上,每个手语序列是具有形状的张量( t {t} t, c {c} c, h {h} h, w {w} w),其中 t {t} t 表示序列的长度, c {c} c 表示通道数, h {h} h 表示帧的高度, w {w} w 表示帧的宽度。帧特征编码器 S {S} S 的操作可以描述为:
{ s } t × f s = S ( { x } t × c × h × w ) = S g a p ( S c n n ( { x } t × c × h × w ) ) \{s\}^{t \times f_{s}}=S\left(\{x\}^{t \times c \times h \times w}\right)=S_{g a p}\left(S_{c n n}\left(\{x\}^{t \times c \times h \times w}\right)\right) {s}t×fs=S({x}t×c×h×w)=Sgap(Scnn({x}t×c×h×w)). (1)
输出的 Shape 为 { s } t × f s \{s\}^{t \times f_{s}} {s}t×fs 。请注意,帧特征编码器 S {S} S 是单独处理每一帧(空间)的特征学习。
| 由公式(1)和这段可以得出:帧特征编码器 S {S} S 是对视频的每一帧都进行处理,先是由 CNN S c n n S_{c n n} Scnn 对每一帧提取特征,然后由全局平均池层 S g a p S_{g a p} Sgap 将空间特征压缩为特征向量。其中 t {t} t 表示序列的长度, c {c} c 表示通道数, h {h} h 表示帧的高度, w {w} w 表示帧的宽度 |
|---|
Two-level gloss feature encoder
Two-level gloss feature encoder. The two-level gloss feature encoder G {G} G follows S {S} S immediately and aims to encode gloss features. Instead of using LSTM layers, a common practice in temporal feature encoding, we achieve this by using 1D convolutional layers over time dimension. Precisely, the first level encoder G 1 {G}_1 G1 consists of 1D-CNNs with a relatively larger filter size. Pooling layers can be used between convolutional layers to increase the window size when needed. Differently, the filter size is relatively smaller for the 1D-CNNs in the second level encoder G 2 {G}_2 G2 , with no pooling layers used in G 2 {G}_2 G2. So, cdoes not change the temporal dimension but only reconsider the contextual information between glosses by taking into account the neighboring glosses.
两级光泽特征编码器. 在帧特征编码器 S {S} S 后面的是两级光泽特征编码器 G {G} G, G {G} G 的目标是对光泽特征进行编码。我们通过在时间维度上使用一维卷积层来实现这一点,而不是使用 LSTM 层,这是时序特征编码中的一种常见做法。准确地说,第一级编码器 G 1 {G}_1 G1 由具有较大卷积核(filter)的 1D-CNN 组成。当需要时,可以在卷积层之间使用池化层来增加窗口大小。
不同的是,在第二级编码器 G 2 {G}_2 G2 中,采用较卷积核的1D-CNN ,在 G 2 {G}_2 G2 中不用使用池化层。因此, G 2 {G}_2 G2 没有改变时序维度,而只是通过考虑相邻的光泽来重新考虑损失的上下文信息。
| 在帧特征编码器 S {S} S 后面连着用于提取 gloss 特征的两级光泽特征编码器 G {G} G, G {G} G 由第一级编码器 G 1 {G}_1 G1 和第二级编码器 G 2 {G}_2 G2 组成。 G 1 {G}_1 G1 由具有较大卷积核的 1D-CNN 组成,用于提取 gloss 特征,必要时可以通过在卷积层之间增加池化层来增大提取特征的窗口。 G 2 {G}_2 G2 采用具有较小卷积核的 1D-CNN,并且不采池化层,只通过相邻的 gloss 来预测上下文信息。 |
|---|
| 卷积的基本概念参考:深度学习笔记_基本概念_卷积网络中的通道channel、特征图feature map、过滤器filter和卷积核kernel |
The overall convolutional process of G {G} G can be interpreted as a sliding window on the frame feature vector { s } t × f s \{s\}^{t \times f_{s}} {s}t×fs along the time dimension. The sliding window size l {l} l and the stride δ {δ} δ are determined by the accumulated receptive field size and the accumulated stride of 1D-CNNs in G 1 {G_1} G1 . Let { g } k × f g \{g\}^{k\times f_{g}} {g}k×fg and { g ′ } k × f g ′ \{g^{\prime}\}^{k \times f_{g^{\prime}}} {g′}k×fg′ be the output tensor of gloss feature encoder G 1 {G_1} G1 and G 2 {G_2} G2 , respectively. The operation of the encoder G {G} G can be formulated as:
{ g ′ } k × f g ′ = G ( { s } t × f s ) = G 2 ( G 1 ( { s } t × f s ) ) = G 2 ( { g } k × f g ) \left\{g^{\prime}\right\}^{k \times f_{g^{\prime}}}=G\left(\{s\}^{t \times f_{s}}\right)=G_{2}\left(G_{1}\left(\{s\}^{t \times f_{s}}\right)\right)=G_{2}\left(\{g\}^{k \times f_{g}}\right) {g′}k×fg′=G({s}t×fs)=G2(G1({s}t×fs))=G2({g}k×fg), (2)
where k {k} k is the number of encoded gloss features and can be calculated with:
k = ⌊ t − l δ ⌋ + 1 k=\left\lfloor\frac{t-l}{\delta}\right\rfloor+1 k=⌊δt−l⌋+1 (3)
两级光泽特征编码器 G {G} G 的整体卷积过程可以解释为在帧特征向量 { s } t × f s \{s\}^{t \times f_{s}} {s}t×fs 的时间维度上进行滑动窗口操作。滑动窗口大小 l {l} l 、步长 δ {δ} δ 由 G 1 {G_1} G1 中累积的感受野大小和 1D-CNNs 累积的步长决定。设 { g } k × f g \{g\}^{k\times f_{g}} {g}k×fg 和 { g ′ } k × f g ′ \{g^{\prime}\}^{k \times f_{g^{\prime}}} {g′}k×fg′ 分别为光泽特征编码器 G 1 {G_1} G1 和 G 2 {G_2} G2 的输出张量。编码器G的操作可以表示为:
{ g ′ } k × f g ′ = G ( { s } t × f s ) = G 2 ( G 1 ( { s } t × f s ) ) = G 2 ( { g } k × f g ) \left\{g^{\prime}\right\}^{k \times f_{g^{\prime}}}=G\left(\{s\}^{t \times f_{s}}\right)=G_{2}\left(G_{1}\left(\{s\}^{t \times f_{s}}\right)\right)=G_{2}\left(\{g\}^{k \times f_{g}}\right) {g′}k×fg′=G({s}t×fs)=G2(G1({s}t×fs))=G2({g}k×fg), (2)
其中 k {k} k 是编码的光泽度特征的数量,可以用以下公式计算:
k = ⌊ t − l δ ⌋ + 1 k=\left\lfloor\frac{t-l}{\delta}\right\rfloor+1 k=⌊δt−l⌋+1 (3)
| 经帧特征编码器 S {S} S 的操作后的得到帧特征向量 { s } t × f s \{s\}^{t \times f_{s}} {s}t×fs,然后用于提取 gloss 特征的两级光泽特征编码器 G {G} G 对帧特征向量 { s } t × f s \{s\}^{t \times f_{s}} {s}t×fs 进行滑动窗口操作。由公式(2)和这段可以得出:两级光泽特征编码器 G {G} G 是对帧特征向量 { s } t × f s \{s\}^{t \times f_{s}} {s}t×fs 进行滑动窗口处理,先是由第一级编码器 G 1 {G}_1 G1 中具有较大卷积核的 1D-CNN 对 { s } t × f s \{s\}^{t \times f_{s}} {s}t×fs 进行滑动窗口操作来提取 gloss 特征,必要时可以通过在卷积层之间增加池化层来增大提取特征的窗口。然后由第二级编码器 G 2 {G}_2 G2 中较小卷积核的 1D-CNN 对由 G 1 {G_1} G1 提取的 gloss 特征 { g } k × f g \{g\}^{k\times f_{g}} {g}k×fg 再提取一次 gloss 特征得到 { g ′ } k × f g ′ \{g^{\prime}\}^{k \times f_{g^{\prime}}} {g′}k×fg′ 。其中 t {t} t 表示序列的长度, f s {f_s} fs 表示 ???, f g {f_g} fg 表示 ??? ,只知道 { s } t × f s \{s\}^{t \times f_{s}} {s}t×fs 是帧特征向量,那么 { g } k × f g \{g\}^{k\times f_{g}} {g}k×fg 也是帧特征向量? k {k} k 是编码的光泽度特征的数量,可以用公式 (3) 计算。 |
|---|
| 卷积中的滑动窗口概念参考:3.4 滑动窗口的卷积实现-深度学习第四课《卷积神经网络》-Stanford吴恩达教授 |
| 两级光泽特征编码器 G {G} G 是怎么编码的?目前只看出是进行两次滑动窗口操作,没看出编码,为什么叫编码器呢? |
The two-level gloss feature encoder takes into account only multiple frames at a time. The window size l {l} l should be designed to be around the average length of the signing glosses to ensure good performance during the gloss feature extraction. With a proper window size design, G 1 {G_1} G1 can better model the semantic information of a “gloss” in sign language. G 2 {G_2} G2 further considers the gloss neighborhood information to achieve better prediction.
两级光泽特征编码器一次对多个帧进行操作。窗口大小 l {l} l 应设为手语光泽的平均长度大小,以确保在提取光泽特征期间具有良好的性能。恰当的窗口大小, G 1 {G_1} G1 可以更好地模拟手语中“光泽”的语义信息。 G 2 {G_2} G2 进一步考虑了光泽的邻近信息,以实现更好的预测。
| 窗口大小 l {l} l 应设为手语光泽的平均长度大小 |
|---|
One benefit of our FCN design over previous LSTM design is that it greatly increases the adaptability of recognition, especially for online applications. Our proposed network can provide high-quality recognition on sequences with various length, which is essential in real-world recognition scenarios. We will further discuss the advantages of the FCN design in Section.
与以前的 LSTM 方法相比,我们的 FCN 网络的一个好处是它极大地提高了识别的适应性,特别是可在线识别。我们提出的网络可以对不同长度的序列提供高质量的识别,这在现实世界的识别场景中是必不可少的。我们将在 4.4 章节中进一步讨论 FCN 设计的优势。
CTC decoder
CTC decoder. The Connectionist Temporal Classification (CTC) [9] is used as the network decoder. The CTC decoder D aims to decode the encoded gloss feature { g ′ } k × f g ′ \{g^{\prime}\}^{k \times f_{g^{\prime}}} {g′}k×fg′. CTC is an objective function that considers all possible underlying alignments between the input and target sequence. An extra “blank” label is added in the prediction space to match the output sequence with the target sequence in temporal dimension. Specifically, we employ a fully connected layer D f c D_{f c} Dfc after G {G} G to cast the gloss feature dimension from ( k , f g ′ ) \left(k, f_{g^{\prime}}\right) (k,fg′) to ( k , u ) \left(k, u\right) (k,u) and a Softmax activation to finally transform the gloss feature to the prediction space { z } k × u \{z\}^{k \times u} {z}k×u :
{ z } k × u = D ( { g ′ } k × f g ′ ) = softmax ( D f c ( { g ′ } k × f g ′ ) ) \{z\}^{k \times u}=D\left(\left\{g^{\prime}\right\}^{k \times f_{g^{\prime}}}\right)=\operatorname{softmax}\left(D_{f c}\left(\left\{g^{\prime}\right\}^{k \times f_{g^{\prime}}}\right)\right) {z}k×u=D({g′}k×fg′)=softmax(Dfc({g′}k×fg′)), (4)
where v {v} v is the vocabulary size and u = v + 1 {u} = {v} + 1 u=v+1 is the size of each output with the extra “blank” added.
CTC 解码器 使用连接主义时态分类(CTC)作为网络解码器。CTC 解码器 D {D} D 旨在解码编码了的光泽特征 { g ′ } k × f g ′ \{g^{\prime}\}^{k \times f_{g^{\prime}}} {g′}k×fg′。CTC 是一个目标函数,它考虑输入序列和目标序列之间所有潜在配对的可能性。在预测空间中增加额外的“空白”标签,使得在时序维度上将输出序列与目标序列进行匹配。具体地说,我们在两级光泽特征编码器 G {G} G 操作后采用全连接层 D f c D_{f c} Dfc 来将光泽特征维度从 ( k , f g ′ ) \left(k, f_{g^{\prime}}\right) (k,fg′) 投射到 ( k , u ) \left(k, u\right) (k,u),并且使用 Softmax 激活来最终将光泽特征变换到预测空间 { z } k × u \{z\}^{k \times u} {z}k×u:
{ z } k × u = D ( { g ′ } k × f g ′ ) = softmax ( D f c ( { g ′ } k × f g ′ ) ) \{z\}^{k \times u}=D\left(\left\{g^{\prime}\right\}^{k \times f_{g^{\prime}}}\right)=\operatorname{softmax}\left(D_{f c}\left(\left\{g^{\prime}\right\}^{k \times f_{g^{\prime}}}\right)\right) {z}k×u=D({g′}k×fg′)=softmax(Dfc({g′}k×fg′)), (4)
其中 v {v} v 是词汇表大小, u = v + 1 {u} = {v} + 1 u=v+1 是每个输出的大小,加上额外的”空白“即这里的 1.
| 从公式(4)和这段可以知道,在经两级光泽特征编码器 G {G} G 操作后得到的特征向量 { g ′ } k × f g ′ \{g^{\prime}\}^{k \times f_{g^{\prime}}} {g′}k×fg′。在 CTC 解码中,先用一个全连接层 D f c D_{f c} Dfc 对特征向量 { g ′ } k × f g ′ \{g^{\prime}\}^{k \times f_{g^{\prime}}} {g′}k×fg′ 进行分类。然后,再接一个 Softmax 突出值得关注的类别和归一化特征向量。 |
|---|
| 全连接层的作用;分类。参考;神经网络学习笔记(一):全连接层的作用是什么? |
| Softmax 作用:对重要类别加强,将数值压缩到0–1;归一化,突出响应更高的地方,把值得关注的地方更突出出来。 |
| CTC在 Spatial-Temporal Multi-Cue Network for Continuous Sign Language Recognition 中是用来进行序列学习和推理的。这里是用来作为解码器。我记得 CTC 最先是用于语音识别的,说明手语和口语有相似之处,手语识别可以借鉴语言识别,文字翻译等口语中的方法。CTC参考:CTC(Connectionist Temporal Classification)介绍 \ CTC学习笔记(一)简介 \ 白话CTC(connectionist temporal classification)算法讲解 |
With normalized probabilities { z } k × u \{z\}^{k \times u} {z}k×u , the output alignment π {π} π can then be generated by taking the label with maximum likelihood at every decoding step. The final recognition result y {y} y is obtained by using the many-to-one function B {B} B introduced in CTC to remove repeated and blank predictions in π {π} π. The CTC objective function is defined as the negative log-likelihood of all possible alignments matched to the ground truth:
L c t c ( x , y ) = − log p ( y ∣ x ) . \mathcal{L}_{c t c}(\boldsymbol{x}, \boldsymbol{y})=-\log p(\boldsymbol{y} \mid \boldsymbol{x}) . Lctc(x,y)=−logp(y∣x)., (5)
With the additional l 2 {l_2} l2 regularizer L r e g \mathcal{L}_{reg} Lreg on the network parameters W {W} W , the objective function of the main stream of the network L m a i n \mathcal{L}_{main} Lmain is defined as:
L main = L ctc + λ 1 L reg = 1 ∣ S ∣ ∑ ( x , y ) ∈ S L c t c ( x , y ) + λ 1 ∥ W ∥ 2 \begin{aligned} \mathcal{L}_{\text {main }} &=\mathcal{L}_{\text {ctc }}+\lambda_{1} \mathcal{L}_{\text {reg }} \\ &=\frac{1}{|\mathcal{S}|} \sum_{(\boldsymbol{x}, \boldsymbol{y}) \in \mathcal{S}} \mathcal{L}_{c t c}(\boldsymbol{x}, \boldsymbol{y})+\lambda_{1}\|\boldsymbol{W}\|^{2} \end{aligned} Lmain =Lctc +λ1Lreg =∣S∣1(x,y)∈S∑Lctc(x,y)+λ1∥W∥2, (6)
where S {S} S is the sample space, and λ 1 {λ_1} λ1 is the weight factor of the regularizer.
在归一化概率 { z } k × u \{z\}^{k \times u} {z}k×u 的情况下,在每个解码步骤中通过取具有最大似然的标签来生成输出校对 π {π} π。通过在 CTC 引入多对一的函数 B {B} B 去除 π {π} π 中的重复预测和空白预测,得到最终的识别结果 y {y} y。CTC 目标函数定义为与真实值相匹配的所有可能的负对数似然函数:
L c t c ( x , y ) = − log p ( y ∣ x ) . \mathcal{L}_{c t c}(\boldsymbol{x}, \boldsymbol{y})=-\log p(\boldsymbol{y} \mid \boldsymbol{x}) . Lctc(x,y)=−logp(y∣x)., (5)
在网络参数 W {W} W 中加上 l 2 {l_2} l2 类型的正则化函数 L r e g \mathcal{L}_{reg} Lreg 后,整个主流网络的主要目标函数 L m a i n \mathcal{L}_{main} Lmain 定义为:
L main = L ctc + λ 1 L reg = 1 ∣ S ∣ ∑ ( x , y ) ∈ S L c t c ( x , y ) + λ 1 ∥ W ∥ 2 \begin{aligned} \mathcal{L}_{\text {main }} &=\mathcal{L}_{\text {ctc }}+\lambda_{1} \mathcal{L}_{\text {reg }} \\ &=\frac{1}{|\mathcal{S}|} \sum_{(\boldsymbol{x}, \boldsymbol{y}) \in \mathcal{S}} \mathcal{L}_{c t c}(\boldsymbol{x}, \boldsymbol{y})+\lambda_{1}\|\boldsymbol{W}\|^{2} \end{aligned} Lmain =Lctc +λ1Lreg =∣S∣1(x,y)∈S∑Lctc(x,y)+λ1∥W∥2, (6)
其中 S {S} S 是样本空间, λ 1 {λ_1} λ1 是正则化的权重因子。
| 从公式(5)、(6)和这段可以知道:CTC 编码的目标函数是 L c t c \mathcal{L}_{c t c} Lctc ,整个主流网络的目标函数是 L m a i n \mathcal{L}_{main} Lmain。而目标函数的作用:整个全卷积网络就是用各种优化方法使得目标函数最优(最大/最小),深度学习就是一个寻最优解的方法。而优化器我之前简单总结了一些可以参考:系统总结深度学习的主要的损失函数和优化器 |
|---|
| l 2 {l_2} l2 类型的正则化函数作用:L2正则化可以直观理解为它对于大数值的权重向量进行严厉惩罚,倾向于更加分散的权重向量。由于输入和权重之间的乘法操作,这样就有了一个优良的特性:使网络更倾向于使用所有输入特征,而不是严重依赖输入特征中某些小部分特征。 L2惩罚倾向于更小更分散的权重向量,这就会鼓励分类器最终将所有维度上的特征都用起来,而不是强烈依赖其中少数几个维度。。这样做可以提高模型的泛化能力,降低过拟合的风险。在实践中,如果不是特别关注某些明确的特征选择,一般说来L2正则化都会比L1正则化效果好。参考链接:ML/DL-复习笔记【二】- L1正则化和L2正则化 |
| 校对 π {π} π :这里的 π {π} π 第一次出现,它是什么意思呢?是3.1415926…吗?还是一个变量?答:不是3.1415926,也不是变量,是一种路径 π {\pi} π (CTC中的专业术语),参考:白话CTC(connectionist temporal classification)算法讲解 |
3.2 Gloss feature enhancement
The main stream of the network has mainly two tasks: (1) alignment inference and (2) gloss prediction. The performance highly depends on how well the network can generalize on glosses, as they are the unit of sign language. Therefore,it is essential to improve the quality of gloss features. Previous methods generally achieve this by incorporating iterative training strategies. They first break training into several stages and then gradually refine feature extraction as each stage processed. However, with this strategy, whenever the training is switched to another stage, the network needs to first gradually adapt to a different objective, which greatly lengthens the number of training epochs and reduces the training efficiency. Moreover, the supervision used in some methods is generally the output of the network, which may contain some false predictions that can further reduce learning efficiency and limit the effectiveness of the refinement.
主流网络主要有两个任务:(1)校准推理,(2)预测光泽。网络识别的准确度很大程度上取决于网络对光泽的泛化程度,因为 gloss 是手语的单位。所以,提高光泽特征的质量至关重要。以前的方法通常是通过结合迭代训练策略来实现这一点。他们首先将训练分成几个阶段,然后随着每个阶段的过程逐步提炼特征提取。然而,在这种策略下,每当训练切换到另一个阶段时,网络首先需要逐渐适应不同的目标,这大大延长了训练周期,降低了训练效率。此外,一些网络的输出一般采用监督的方法,这可能包含一些错误的预测,这会进一步降低学习效率,限制精化的有效性。
| 时间 | 论文 | 方法 | 缺点 | 优点 |
|---|---|---|---|---|
| 2017 | Cui, R., Liu, H., Zhang, C.: Recurrent convolutional neural networks for continuous sign language recognition by staged optimization. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. pp. 1610–1618 (2017) | 通过结合迭代训练策略来提高光泽特征的质量 | 周期长,效率低 | - |
| 2017 | Koller, O., Zargaran, S., Ney, H.: Re-sign: Re-aligned end-to-end sequence modelling with deep recurrent cnn-hmms. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 3416–3424 (2017) | 通过结合迭代训练策略来提高光泽特征的质量 | 周期长,效率低 | - |
| 2019 | Pu, J., Zhou, W., Li, H.: Iterative alignment network for continuous sign language recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. pp. 4165–4174 (2019) | 通过结合迭代训练策略来提高光泽特征的质量 | 周期长,效率低 | - |
| 2019 | Cui, R., Liu, H., Zhang, C.: A deep neural framework for continuous sign language recognition by iterative training. IEEE Transactions on Multimedia 21, 1880–1891 (2019) | 通过结合迭代训练策略来提高光泽特征的质量 | 周期长,效率低 | - |
To remedy these problems, we propose the GFE module. The GFE module uses rectified supervision and is jointly trained with the main stream of the network, so it can improve the the main stream network performance on the line. We illustrate the idea of the GFE module in Figure 2.
为了解决这些问题,我们提出了 GFE 模块。GFE 模块采用纠正的监督,并与主流网络联合训练,提高了主流网络的在线性能。我们在图2中说明了GFE模块的概念。
 Fig. 2. The GFE module. The red dots in the prediction map are network outputs, while the blue ones are alignment proposals. The proposal rectifies the false predictions in the output to match the ground truth
Fig. 2. The GFE module. The red dots in the prediction map are network outputs, while the blue ones are alignment proposals. The proposal rectifies the false predictions in the output to match the ground truth
图2. GFE模块。预测图中的红点是网络的输出,蓝点是调整建议。该建议纠正了输出中的错误预测,使之与基本事实相符。
Alignment proposal
Alignment proposal. High-quality supervision can significantly improve the effectiveness of feature enhancement. Similar to [5], we make use of the network prediction map to find a better alignment proposal as the supervision. Specifically, given an input sequence, the CTC decoder D {D} D generates a prediction map { z } k × u \{z\}^{k \times u} {z}k×u , which is the probability of emissions in each decoding step. Let π ∗ {π}^{*} π∗ denote the element in the alignment proposal. The alignment proposal ccused in the GFE module can then be generated by searching the alignment proposal with the highest probability that can be matched to the ground truth sequence:
π ∗ = arg max π ∈ B − 1 ( y ) p ( π ∣ x ) \boldsymbol{\pi}^{*}=\underset{\boldsymbol{\pi} \in \mathcal{B}^{-1}(\boldsymbol{y})}{\arg \max } p(\boldsymbol{\pi} \mid \boldsymbol{x}) π∗=π∈B−1(y)argmaxp(π∣x), (7)
where B − 1 {B}^{-1} B−1 is the inverse function of B {B} B. Hence, the alignment proposal is guaranteed to be a matched alignment of the ground truth sequence. Each π ∗ {π}^{*} π∗ in π ∗ \boldsymbol{\pi}^{*} π∗ can be paired with a first level gloss feature vector g {g} g at the corresponding time step in g \boldsymbol{g} g , which gives a pair of learning sample ( g , π ∗ ) ∈ V \left(g, \pi^{*}\right) \in \mathcal{V} (g,π∗)∈V.
校准方案 高质量的监督可以显著提高特征增强的效果。类似于[5],我们利用网络预测图来寻找更好的校对方案作为监督。具体地说,在给定输入序列的情况下,CTC 解码器 D {D} D 生成的预测图 { z } k × u \{z\}^{k \times u} {z}k×u 是每步解码中的发射(emissions)概率。用 π ∗ {π}^{*} π∗ 表示校对方案中的元素。然后,可以通过搜索具有与真值序列匹配的最高概率的校对方案来,在 GFE 模块中使用的校对方案 π ∗ = { π ∗ } k \boldsymbol{\pi}^{*}=\left\{\pi^{*}\right\}^{k} π∗={π∗}k 是搜索与真值序列相匹配的最高概率的校对方案:
π ∗ = arg max π ∈ B − 1 ( y ) p ( π ∣ x ) \boldsymbol{\pi}^{*}=\underset{\boldsymbol{\pi} \in \mathcal{B}^{-1}(\boldsymbol{y})}{\arg \max } p(\boldsymbol{\pi} \mid \boldsymbol{x}) π∗=π∈B−1(y)argmaxp(π∣x), (7)
其中 B − 1 {B}^{-1} B−1 是 B {B} B 的反函数。因此,该校对方案被认为是与真值序列相匹配的校对方案。在 π ∗ \boldsymbol{\pi}^{*} π∗ 中的每个 π ∗ {π}^{*} π∗ 都能与在相应时间步长 g \boldsymbol{g} g 中的第一级光泽特征向量 g {g} g 相配对,这给出了一对学习样本 ( g , π ∗ ) ∈ V \left(g, \pi^{*}\right) \in \mathcal{V} (g,π∗)∈V。
| 时间 | 论文 | 方法 | 缺点 | 优点 |
|---|---|---|---|---|
| 2019 | Cui, R., Liu, H., Zhang, C.: A deep neural framework for continuous sign language recognition by iterative training. IEEE Transactions on Multimedia 21, 1880–1891 (2019) | 高质量的监督可以显著提高特征增强的效果 | - | - |
| CTC 解码器 D {D} D 生成的预测图 { z } k × u \{z\}^{k \times u} {z}k×u 中的 k {k} k 和 u {u} u 是指什么? 在图二中路线方案中有一个 u × k u \times k u×k 的方阵,此方阵由“blank”标签和“Non-blank”标签组成 u × k u \times k u×k 的方阵,在其中找出最高的可能性大路径 π ∗ \boldsymbol{\pi}^{*} π∗ |
|---|
Joint training with weighted cross-entropy
Joint training with weighted cross-entropy. To use the learning pairs in V \mathcal{V} V as enhancement supervision, we add a fully connected layer F f c {F}_{fc} Ffc followed by a Softmax activation after G 1 {G}_1 G1 . When joint training with the GFE module, gradients along this addition branch only propagate back to F and G 1 {G}_1 G1 to enhance the frame and gloss feature learning. Formally, the GFE module contains a GFE decoder F, that takes g = { g } k × f g \boldsymbol{g}=\{g\}^{k \times f_{g}} g={g}k×fg, the output vector of G 1 {G}_1 G1, as inputs, and outputs the predicted gloss sequence in prediction space π ^ ∗ = { π ^ ∗ } k × u \hat{\boldsymbol{\pi}}^{*}=\left\{\hat{\pi}^{*}\right\}^{k \times u} π^∗={π^∗}k×u:
{ π ^ ∗ } k × u = F ( { g } k × f g ) = softmax ( F f c ( { g } k × f g ) ) \left\{\hat{\pi}^{*}\right\}^{k \times u}=F\left(\{g\}^{k \times f_{g}}\right)=\operatorname{softmax}\left(F_{f c}\left(\{g\}^{k \times f_{g}}\right)\right) {π^∗}k×u=F({g}k×fg)=softmax(Ffc({g}k×fg)), (8)
加权交叉熵联合训练. 为了使用在 V \mathcal{V} V 中学习对作为监督加强,我们在 G 1 {G}_1 G1后的 softmax 激活层后加了一个全连接层 F f c {F}_{fc} Ffc。当与 GFE 模块联合训练时,沿该加法分支的梯度仅传播回 F 和 G 1 {G}_1 G1 以增强帧和光泽特征的 学习。形式上,GFE模块包含 GFE 解码器 F,其以 G 1 {G}_1 G1 的输出向量 g = { g } k × f g \boldsymbol{g}=\{g\}^{k \times f_{g}} g={g}k×fg 作为输入,并在预测空间 π ^ ∗ = { π ^ ∗ } k × u \hat{\boldsymbol{\pi}}^{*}=\left\{\hat{\pi}^{*}\right\}^{k \times u} π^∗={π^∗}k×u 中输出预测光泽序列:
{ π ^ ∗ } k × u = F ( { g } k × f g ) = softmax ( F f c ( { g } k × f g ) ) \left\{\hat{\pi}^{*}\right\}^{k \times u}=F\left(\{g\}^{k \times f_{g}}\right)=\operatorname{softmax}\left(F_{f c}\left(\{g\}^{k \times f_{g}}\right)\right) {π^∗}k×u=F({g}k×fg)=softmax(Ffc({g}k×fg)), (8)
It is intuitive to train the gloss feature enhancement branch with crossentropy loss. However, it is common that most of the label π ∗ {π}^{*} π∗ in π ∗ \boldsymbol{\pi}^{*} π∗ is “blank” as k {k} k is generally much bigger than the number of glosses in the ground truth, causing the imbalance of samples in V {V} V. The sample imbalance may limit the effectiveness of training for the GFE module. Therefore, we introduce a balance ratio to decrease the loss from “blank” labels. The balance ratio is defined as the proportion of “non-blank” labels in the given proposal π ∗ \boldsymbol{\pi}^{*} π∗ :
b r = # non-blank # total b r=\frac{\# \text { non-blank }}{\# \text { total }} br=# total # non-blank , (9)
训练具有交叉熵损失的光泽特征增强分支是直观的。然而,通常情况下, π ∗ \boldsymbol{\pi}^{*} π∗ 中的大多数标签 π ∗ {π}^{*} π∗ 都是空白的,通常比真实值中的光泽度大得多,导致样本库存的不平衡。通常,由于k中的k通常比地面真实情况中的光泽数大得多,因此π中的大多数π标签都是“空白”的,这导致V中的样本不平衡。通常, π ∗ \boldsymbol{\pi}^{*} π∗ 中的大多数标记 π ∗ {π}^{*} π∗ 是“blank”的,因为 k {k} k 通常比真实中的光泽数大得多,从而导致 V {V} V 中的样本不平衡。样本不平衡可能会限制 GFE 模块的培训效果。因此,我们引入了一种平衡来减少“blank”标签造成的损失。定义如下平衡比为校对方案 π ∗ \boldsymbol{\pi}^{*} π∗ 中“non-blank”标签的比例:
b r = # non-blank # total b r=\frac{\# \text { non-blank }}{\# \text { total }} br=# total # non-blank , (9)
For every ( g , π ∗ ) ∈ V \left(g, \pi^{*}\right) \in \mathcal{V} (g,π∗)∈V, we use a weighted cross entropy loss to obtain the GFE loss, where there is a classification task to classify g g g as π ∗ {\pi}^{*} π∗ (out of u u u classes). Equation 10 needs to be re-written as the following: we suppose π ∗ {\pi}^{*} π∗ is class j j j,
where π i ∗ {\pi}_{i}^{*} πi∗ is a binary indicator (1 if label i i i is the true label, and vice versa) and π ^ i ∗ \hat{\pi}_{i}^{*} π^i∗ is the predicted probability of label i i i.
L g f e ( g , π ∗ ) = ∑ i = 1 u w i π i ∗ log π ^ i ∗ = − w j log π ^ j ∗ \mathcal{L}_{g f e}\left(g, \pi^{*}\right)=\sum_{i=1}^{u} w_{i} \pi_{i}^{*} \log \hat{\pi}_{i}^{*}=-w_{j} \log \hat{\pi}_{j}^{*} Lgfe(g,π∗)=∑i=1uwiπi∗logπ^i∗=−wjlogπ^j∗, (10)
With the GFE module, the overall objective of the proposed network L \mathcal{L} L becomes:
L = L main + λ 2 L g f e = 1 ∣ S ∣ ∑ ( x , y ) ∈ S L c t c ( x , y ) + λ 2 ∣ V ∣ ∑ ( g , π ∗ ) ∈ V L g f e ( g , π ∗ ) + λ 1 ∥ W ∥ 2 \begin{aligned} \mathcal{L}=& \mathcal{L}_{\text {main }}+\lambda_{2} \mathcal{L}_{g f e} \\=& \frac{1}{|\mathcal{S}|} \sum_{(\boldsymbol{x}, \boldsymbol{y}) \in \mathcal{S}} \mathcal{L}_{c t c}(\boldsymbol{x}, \boldsymbol{y})+\\ & \frac{\lambda_{2}}{|\mathcal{V}|} \sum_{\left(g, \pi^{*}\right) \in \mathcal{V}} \mathcal{L}_{g f e}\left(g, \pi^{*}\right)+\lambda_{1}\|\boldsymbol{W}\|^{2} \end{aligned} L==Lmain +λ2Lgfe∣S∣1(x,y)∈S∑Lctc(x,y)+∣V∣λ2(g,π∗)∈V∑Lgfe(g,π∗)+λ1∥W∥2, (11)
where λ 2 \lambda_{2} λ2 is the weight factor for the GFE module. Note that the network objective is unified with joint training, so the training process is more efficient.
对于每个 ( g , π ∗ ) ∈ V \left(g, \pi^{*}\right) \in \mathcal{V} (g,π∗)∈V,我们用一个加权交叉熵损失作为 GFE 损失,这里有一个分类任务:将 g g g分类为 π ∗ {\pi}^{*} π∗(在 u u u类中)。等式10需要重新编写为以下形式:我们假设 π ∗ {\pi}^{*} π∗是类 j j j,其中 π i ∗ {\pi}_{i}^{*} πi∗ 是二进制指示符(如果标签 i i i是真实标签,则为1,反之为0),并且 π ^ i ∗ \hat{\pi}_{i}^{*} π^i∗ 是标签 i i i的预测概率。(公式10 与原文不一致,一作说原文公式10 有误,还没有在 arxiv 上修改,可以参考这个)
L g f e ( g , π ∗ ) = ∑ i = 1 u w i π i ∗ log π ^ i ∗ = − w j log π ^ j ∗ \mathcal{L}_{g f e}\left(g, \pi^{*}\right)=\sum_{i=1}^{u} w_{i} \pi_{i}^{*} \log \hat{\pi}_{i}^{*}=-w_{j} \log \hat{\pi}_{j}^{*} Lgfe(g,π∗)=∑i=1uwiπi∗logπ^i∗=−wjlogπ^j∗, (10)
使用GFE模块,提出的网络的总体目标函数 L \mathcal{L} L 为:
L = L main + λ 2 L g f e = 1 ∣ S ∣ ∑ ( x , y ) ∈ S L c t c ( x , y ) + λ 2 ∣ V ∣ ∑ ( g , π ∗ ) ∈ V L g f e ( g , π ∗ ) + λ 1 ∥ W ∥ 2 \begin{aligned} \mathcal{L}=& \mathcal{L}_{\text {main }}+\lambda_{2} \mathcal{L}_{g f e} \\=& \frac{1}{|\mathcal{S}|} \sum_{(\boldsymbol{x}, \boldsymbol{y}) \in \mathcal{S}} \mathcal{L}_{c t c}(\boldsymbol{x}, \boldsymbol{y})+\\ & \frac{\lambda_{2}}{|\mathcal{V}|} \sum_{\left(g, \pi^{*}\right) \in \mathcal{V}} \mathcal{L}_{g f e}\left(g, \pi^{*}\right)+\lambda_{1}\|\boldsymbol{W}\|^{2} \end{aligned} L==Lmain +λ2Lgfe∣S∣1(x,y)∈S∑Lctc(x,y)+∣V∣λ2(g,π∗)∈V∑Lgfe(g,π∗)+λ1∥W∥2, (11)
其中, λ 2 {\lambda_2} λ2 是 GFE 模块的重量系数。需要注意的是,网络目标函数是与联合训练相结合的,因此训练过程更加高效。
4 Experiments
We conduct experiments on the Chinese Sign Language (CSL) dataset [14] and the RWTH-PHOENIX-Weather-2014 (RWTH) dataset [18].We detail the exper-imental setup, results, ablation studies, and online recognition in this section.
我们在中国手语(CSL)数据集[14]和RWTH-Phoenix-Weather-2014(RWTH-Phoenix-Weather-2014)数据集[18]上进行了实验。
在这章中,我们将详细介绍实验的设置、结果、消融研究和在线识别。
4.1 Experimental setup
Dataset
Dataset. The RWTH-PHOENIX-Weather-2014 (RWTH) dataset is recorded from a public weather broadcast television station in Germany. All signers wear dark clothes and perform sign languages in front of a clean background. There are 6, 841 different sentences signed by 9 different signers (around 80, 000 glosses with a vocabulary of size 1, 232). All videos are pre-processed to a resolution of 210 × 260 and 25 frames per second (FPS). The dataset is officially split with 5, 672 training samples, 540 validation samples, and 629 testing samples.
数据集. RWTH-Phoenix-Weather-2014(RWTH)数据集由德&国一家公共天气广播电视台录制。所有 signer 都穿着深色衣服,在干净的背景前表演手语。有9个不同的 signer 比划了6841个不同的句子(大约8万个词条,词汇量为1232个)。所有视频都经过预处理,分辨率为210×260,帧/秒(FPS)为25帧。数据集正式划分为5672个训练样本、540个验证样本和629个测试样本。
The Chinese Sign Language (CSL) dataset contains 100 sentences, each being signed for 5 times by 50 signers (in total 25, 000 videos). Videos are shoot using a Microsoft Kinect camera with a resolution of 1280 × 720 and a frame rate of 30 FPS. The vocabulary size is relatively small (178); however, the dataset is richer in performance diversity, since signers wear different clothes and sign with different speeds and action ranges. With no official split given, we divide the dataset into a training set of 20, 000 samples and a testing set of 5, 000 samples and ensure that the sentences in the training and testing sets are the same, but the signers are different.
中国手语(CSL)数据集包含 100 个句子,每个句子由 50 个 signer 比划 5 次(总共25000个视频)。视频是使用 Microsoft Kinect 摄像头拍摄的,分辨率为 1280×720,FPS 为30。词汇量相对较小(178);然而,由于 signer 穿着不同的衣服,以不同的速度和动作范围进行手势,因此数据集在性能多样性方面更加丰富。在没有给出正式分割的情况下,我们将数据集分为 20000 个样本的训练集和 5000 个样本的测试集,并确保训练集中和测试集中的句子相同,但 signer 不同。
| CSL | RWTH-Phoenix-Weather-2014(RWTH) |
|---|---|
| Huang, J., Zhou, W., Zhang, Q., Li, H., Li, W.: Video-based sign language recognition without temporal segmentation. In: Proceedings of AAAI Conference on Artificial Intelligence. pp. 2257–2264 (2018) | Koller, O., Forster, J., Ney, H.: Continuous sign language recognition: Towards large vocabulary statistical recognition systems handling multiple signers. Computer Vision and Image Understanding 141, 108–125 (2015) |
Evaluation metric
Evaluation metric. We use word error rate (WER), which is the metric commonly used in continuous SLR, to evaluate the performance of recognition:
W E R ( H ( x ) , y ) ) = # i n s + # d e l + # sub # labels in y . WER(H(\boldsymbol{x}), \boldsymbol{y}))=\frac{\# i n s+\# d e l+\# \text { sub }}{\# \text { labels in } \boldsymbol{y}} . WER(H(x),y))=# labels in y#ins+#del+# sub . (12)
We treat a Chinese character as a word during evaluation for the CSL dataset.
评价指标. 我们使用连续手语识别中常用的误词率(WER)来评估识别性能:
W E R ( H ( x ) , y ) ) = # i n s + # d e l + # sub # labels in y . WER(H(\boldsymbol{x}), \boldsymbol{y}))=\frac{\# i n s+\# d e l+\# \text { sub }}{\# \text { labels in } \boldsymbol{y}} . WER(H(x),y))=# labels in y#ins+#del+# sub . (12)
在对CSL数据集进行评估的过程中,我们将一个汉字视为一个词。
Implementation details
Implementation details. The main stream network setting used in our experiments is shown in Figure 3. For S c n n {S}_{cnn} Scnn , the channel number gradually increases in this pattern: 3-32-64-64-128-128-256-256-512-512. F3-S1-P1 is used in each layer, and an additional M2 is added if the channel number increases. S g a p {S}_{gap} Sgap does global average pooling on each channel, so each frame is encoded as an array with a length of 512. For encoder G 1 {G}_1 G1 , two F5-S1-P2-M2 layers are used, and the channel number remains unchanged as 512. For encoder G 2 {G}_2 G2 , one F3-S1-P1 layer is used, and the channel number increases to 1024. Both fully connected layers D f c {D}_fc Dfc and F f c {F}_fc Ffc in the main stream and the GFE module cast the input channel number to u {u} u, the number of vocabulary size plus one blank label.
 Fig. 3. The setting of the proposed main stream network. F, M refer to the filter size of convolution and max-pooling, respectively. S, P refer to the stride and padding size of convolution, respectively. Numbers aside are their actual size
Fig. 3. The setting of the proposed main stream network. F, M refer to the filter size of convolution and max-pooling, respectively. S, P refer to the stride and padding size of convolution, respectively. Numbers aside are their actual size
实现细节. 我们的实验中使用的主流网络设置如图3所示。对于 S c n n {S}_{cnn} Scnn,通道数依次递增:3-32-64-64-128-128-256-256-512-512。每一层使用 F3-S1-P1,如果通道数增加,则增加M2。 S g a p {S}_{gap} Sgap 在每个通道上进行全局平均池操作,因此每个帧都编码为一个长度为 512 数组。对于编码器 G 1 {G}_1 G1,使用两个 F5-S1-P2-M2 层,并且保持通道数为 512 不变。对于编码器 G 2 {G}_2 G2,使用一个 F3-S1-P1 层,并且通道数增加到1024。主流网络中的 D f c {D}_fc Dfc 和 F f c {F}_fc Ffc 层与 GFE 模块中 D f c {D}_fc Dfc 和 F f c {F}_fc Ffc 层都将输入通道数设为 u u u,词汇量大小加 1(一个空白标签)。
Batch normalization [15] is added after every convolutional layer to accelerate training. The input resolution of the network is 224 × 224. The window size in the first level gloss feature encoder is set to be 16 (about 0.5-0.6 seconds), which is the average time needed for completing a gloss, and the stride of the window is set to be 4. The second level gloss feature encoder further considers 3 adjacent gloss features for better prediction.
在每个卷积层之后添加批归一化[15]以加速训练。该网络的输入分辨率为 224×224。一级光泽特征编码器中的窗口大小设置为 16(约0.5-0.6秒),这是完成一次光泽所需的平均时间,窗口步长设置为 4。为了更好地预测,第二级光泽特征编码器进一步考虑了 3 个邻近光泽的特征。
We use Adam [17] optimizer for training. We set the initial learning rate to be 10 − 4 {10}^{-4} 10−4. The weight factor λ 1 \lambda_1 λ1 and λ 2 \lambda_2 λ2 are empirically set to be 10 − 4 {10}^{-4} 10−4 and 0.05, respectively. For the RWTH dataset, we train the proposed network for 80 epochs and halve learning rate at epoch 40 and 60. For the CSL dataset, the network is trained for 60 epochs, with the learning rate reduced by half at epoch 30 and 45. For data augmentation, all frames are first resized to 256 × 256 and then randomly cropped to fit the input shape. We also do temporal augmentation by first scaling up the sequence by +20% and then by −20%. Joint training with the GFE module is activated after epoch 15 for RWTH and epoch 10 for CSL, which are chosen through experiments to avoid unreliable alignment proposal at the initial optimization stage. The alignment proposals in the GFE module are updated every 10 epochs. When updating the proposal, temporal augmentation is disabled.
我们使用Adam[17]优化器进训练。我们将初始学习率设置为 10 − 4 {10}^{-4} 10−4。根据经验,权重因子 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 分别被设置为 10 − 4 {10}^{-4} 10−4 和 0.05。对于 RWTH 数据集,我们对所提出的网络进行了 80轮训练,并在第 40 轮和第 60 轮时将学习率减半。对于CSL数据集,对网络进行了 60 轮训练,在第 30 轮和第 45 轮的时候,学习率降低了一半。对于数据增强,首先将所有帧的大小调整为 256×256,然后随机裁剪以适合输入形状。我们还进行了时序扩展,首先将序列放大 +20%,然后缩小 -20%。与 GFE 模块的联合训练是在 RWTH 的第 15 轮和 CSL 的第10轮之后启动的,这两个周期是通过实验选择的,以避免在初始优化阶段提出不可靠的对准方案。GFE模块中的校对方案每 10 轮更新一次。当更新方案时,不允许进行时序扩展。

图3. 主流网络的参数设置。F 和 M 分别表示卷积核和最大池化的大小。S、P分别表示卷积的步长和填充的大小。撇开数字不谈,它们的实际大小
| 步长和填充:参考(pytorch-深度学习系列)卷积神经网络中的填充(padding)和步幅(stride) |
|---|
4.2 Results
We give a thorough comparison between the proposed network and previous RGB-based methods on both datasets. The results of previous methods are collected from their original papers. Please note that we mainly focus on online recognition in SLR, where the inputs are usually RGB video frames. Hence, we only compare our results with previous methods that use solely RGB modality.
在这两个数据集上,我们对所提出的网络和以前基于RGB的方法进行了深入的比较。以前方法的结果都是从它们的原始文献中收集而来的。请注意,我们主要关注手语识别的在线识别,其输入通常是 RGB 视频帧。因此,我们只将我们的结果与以前仅使用 RGB 作为输入的方法进行比较。
Results on the CSL dataset and the RWTH dataset are shown in Table 1 and Table 2, respectively. We see that the proposed network achieves state-ofthe-art performance on both datasets for RGB-based methods. The best result achieves 3.0% for the CSL dataset. For the RWTH dataset, our model reports 23.7% for the development set and 23.9% for the testing set. We also test the performance on the recognition partition (without translation) of the RWTHPHOENIX Weather 2014 T dataset [1]. Our WER on the development set and testing set are 23.3% and 25.1%, respectively. These results illustrate the effectiveness of the proposed network.
CSL 数据集和 RWTH 数据集的结果分别显示在表1和表2中。我们看到,对于基于RGB的方法,所提出的网络在两个数据集上都达到了最好的性能。对于CSL数据集,最好的结果达到了3.0%的误字率。对于RWTH数据集,我们的模型在验证集中达到23.7% 和在测试集中达到23.9%的误字率。我们还在RWTH-Phoenix Weather 2014T 数据集的识别分区(不加翻译)上测试了该算法的性能[1]。我们在验证集和测试集上的 WER 分别为 23.3% 和 25.1%。这些结果说明了所提出网络的有效性。

To further demonstrate the effectiveness of our methods, we show some sample outputs in Figure 4 to compare the recognition quality of different network settings. We observe that in the LSTM setting, models recognize the identical glosses (such as “OST” in sample 1 and “HIER” in sample 3) in a sentence as different words, and that errors usually occur adjacently in the sentences.In contrast, the proposed network produces consistent results for the identical glosses in a sentence, and errors are usually isolated. The observations infer that the LSTM based methods tend to learn robust sequential information, while the proposed network focuses on learning strong gloss features. So, we claim that the proposed network has a better generalization capability, because identical glosses are consistently classified, and errors do not have significant effects on neighboring glosses. On top of that, the GFE module further improves the performance by rectifying wrong recognition (such as “IN-KOMMEND” in sample 3), finding missing recognition (such as “AUCH” in sample 2), and adjusting alignments. More qualitative comparison can be found in the supplementary material.
为了进一步证明该方法的有效性,我们在图4中给出了一些样本输出,以比较在不同网络设置下的识别质量。我们观察到,在LSTM环境下,模型将句子中同一 gloss (如样本1中的“OST”和样本3中的“Hier”)识别为不同的单词,这种错误通常发生在连续语句的识别中。相反,所提出的网络对句子中同一个 gloss 识别出一致的结果,并且错误通常是对孤立词识别错误。观察结果表明,基于 LSTM 的方法倾向于学习稳健的序列信息,而所提出的网络侧重于学习强光泽特征。因此,我们认为所提出的网络具有更好的泛化能力,因为相同的 gloss 能与真实值保持一致的分类,并且识别错误对邻近的 gloss 没有显著的影响。最重要的是,GFE 模块通过纠正错误识别(如样本3中的“IN-KOMMEND”)、查找丢失的识别(如样本2中的“Auch”)和调整校对来进一步提高性能。在补充材料中可以找到更多的定性比较。
4.3 Ablation studies
In this section, we present further ablation studies to demonstrate the effectiveness of our method.
在这章中,我们提出进一步的消融研究,以证明我们的方法的有效性。
| Ablation studies:参考简单解释Ablation Study 简单的来说,可以理解为对比实验,或者控制变量法。 |
|---|
Temporal feature encoder
Temporal feature encoder. We first conduct a set of experiments to compare network performance with different temporal feature encoder designs. We test 6 different design combinations for the temporal feature encoder. For notation, None means no architecture; LSTM or BiLSTM means 1 LSTM or BiLSTM layer with 512 hidden states, respectively; 1D-CNN means two F5-S1-P2-M2 1DConvs for the 1 s t {1}^{st} 1st level or one F3-S1-P1 1DConv for the 2 n d {2}^{nd} 2nd level. We show results on the testing set of the RWTH and CSL datasets in Table 3. Note that in this set of experiments, the GFE module is not activated.

时间特征编码器. 我们首先进行了一组实验,比较了不同的时间特征编码器设计的网络性能。我们测试了 6 种不同的时态特征编码器设计组合。如下, 没有方法没有体系结构;LSTM 和 BiLSTM 分别表示具有 512 个隐藏态的 1 个 LSTM 或 BiLSTM 层;1D-CNN 表示用于第一级的两个 F5-S1-P2-M21DConv 或用于第二级的一个 F3-S1-P1 1DConv。我们在表 3 中显示了 RWTH 和 CSL 数据集的测试结果。请注意,在这组实验中,GFE 模块未激活。

We see that both levels of gloss feature encoder are essential for recognition as WER raises significantly when either of them is absent. CNN-based designs consistently outperform their LSTM counterparts for the RWTH dataset, but networks with BiLSTM give the best results for the CSL dataset. We should be reminded of the differences between the two datasets. The CSL dataset has richer diversity in the spatial dimension (such as different cloth colors) than in the temporal term. In other words, it is easier for the network to learn the temporal features than the spatial features in the CSL dataset. Also, different from that all the testing sentences are unseen in the RWTH training set, all the testing sentences in the CSL dataset are already seen in the training set, but just signed by different people. The working nature of 1D-CNN and LSTM is also different. The LSTM based method has direct access to sentence-level information, since LSTM layers have access to all the frame information. While the FCN method has less sentence-level supervision (only indirect access through the CTC decoding function), as the FCN model uses only a fixed number of frames to predict a gloss at each time step with 1D-CNNs.
我们看到,这两个级别的光泽特征编码器对于识别都是必不可少的,因为当它们中的任何一个缺失时,WER 都会显着提高。对于 RWTH 数据集,基于 CNN 的设计始终优于其对应的 LSTM,但对于 CSL 数据集,采用 BiLSTM 的网络提供了最好的结果。应该注意这两个数据集之间的差异。CSL 数据集在空间维度(如不同的布料颜色)上比在时序上具有更丰富的多样性。换言之,对于网络来说,学习CSL数据集中的时序特征比空间特征更容易。而且,与 RWTH 训练集中 unseen 所有测试句子不同的是,CSL 数据集中的所有测试句子都已经在训练集中看到了,只是由不同的人签名而已。1D-CNN和LSTM的工作性质也不同。由于 LSTM 层可以直接访问所有帧信息,因此基于 LSTM 的方法可以直接访问语句级信息。因为 FCN 模型只使用固定数量的帧来预测具有 1D-CNN 的每个时间步长的 gloss,所以 FCN 方法具有较少的语句级监控(仅通过 CTC 解码功能间接访问)。
Therefore, we claim that LSTM based methods tend to “remember” all the signing sequences in the training set instead of trying to learn the glosses independently. When testing the sentences in the CSL dataset, whose sequential sentences are the same as the training samples, the strong sequential information learned by LSTM based methods is significant and helpful, causing a relatively low reported WER. While for our FCN method, it is hard to fully extract the spatial and temporal features with weak supervision without substantial sentence-level information. Thus, it is essential to have a GFE module for feature enhancement, and the full version of our proposed network outperforms all the LSTM based methods for both datasets.
因此,我们认为基于 LSTM 的方法倾向于“记住”训练集中的所有手语序列,而不是试图独立地学习 gloss。当测试 CSL 数据集中的句子时,其序列语句与训练样本相同,基于 LSTM 的方法学习到的强序列信息是有意义的,也是有帮助的,导致报告的 WER 相对较低。而对于 FCN 方法,如果没有丰富的句子级信息,在监督能力较弱的情况下,很难完整地提取出时空特征。因此,有一个用于特征增强的 GFE 模块是必不可少的,并且我们提出的网络的完整版本在这两个数据集上都优于所有基于 LSTM 的方法。
GFE module
GFE module. We conduct a set of experiments to investigate the effectiveness of the GFE module. We test different settings on both the RWTH and CSL datasets, including learning without the GFE module, with the GFE module but without balance ratio, and with the GFE module and balance ratio. Results on the testing sets are shown in Table 4.

我们进行了一系列实验来研究GFE模块的有效性。我们在 RWTH 和 CSL 数据集上测试了不同的设置,包括在没有 GFE 模块的情况下学习,使用 GFE 模块学习,在没有平衡比的情况下学习,以及在 GFE 模块和平衡比的情况下学习。结果测试集如表4所示。

We see that when the balance ratio is used, the GFE module can significantly fine-tune the features and improve the performances accordingly for both datasets. The GFE module with balance ratio improves the testing WER for the RWTH dataset by 2.1%; the improvement is more prominent for the CSL dataset by 5.2%. The difference of improvement is because the CSL dataset has much richer diversity in the spatial dimension than the RWTH dataset, making the spatial features in the CSL dataset more difficult to be learned without the GFE module.
我们看到,当使用平衡比时,GFE 模块可以显著地微调两个数据集的特征,并相应地提高性能。带平衡比的 GFE 模块将 RWTH 数据集的测试 WER 提高了 2.1%;CSL 数据集的改进更为显著,提高了 5.2%。提升效果的不同之处在于 CSL 数据集在空间维度上的多样性比 RWTH 数据集丰富得多,使得 CSL 数据集中的空间特征在没有 GFE 模块的情况下更难学习。
4.4 Online recognition
We mention in Section 4.3 that the proposed network has weaker supervision on sentence information. The FCN method focuses more on glosses rather than sentences, which directs us for some interesting experiments with different setups.
我们在第4.3节中提到,提出的网络对句子信息的监督较弱。FCN 方法更多地关注光泽而不是句子,这指导我们在不同的设置下进行一些有趣的实验。
Simulating experiments
Simulating experiments. For recognition in the real world, it is natural to consider the following three scenarios: (1) Signers sign several sentences at a time. (2) Signers sign only a phrase at a time. (3) Signers may pause for some while (stutters of actions) in the middle of signing. Accordingly, as shown in Figure 5, we design three types of experiments which are conducted on the RWTH dataset to simulate online recognition: (1) concatenate multiple samples for a new sample (numbers after Concat indicate the number of samples being concatenated); (2) evenly split a sample into multiple samples (numbers after Split indicate the number of equal segments); (3) randomly select 5 frames in each sample and replace them with 12 replications in place (Rand Repli means random replication).
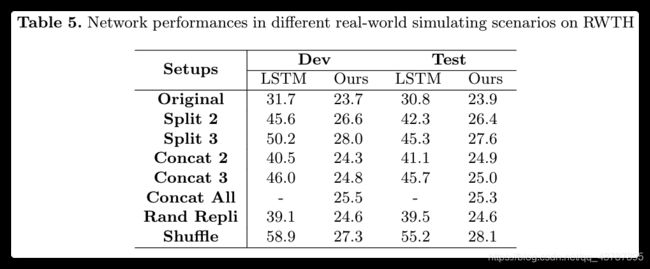
模拟实验. 对于在现实世界中的识别,应考虑以下三种情况:(1) signer 一次比划几句话。(2) signer 一次只笔划一句话。(3) signer 可能会在笔划过程中暂停一段时间(动作断断续续)。因此,如图5所示,我们设计了三种类型的实验,这些实验在 RWTH 数据集上进行,以模拟在线识别:(1)为一个新样本连接多个样本(Concat后的数字表示连接的样本数量);(2)将一个样本均匀分割成多个样本(Split后的数字表示相等片段的数量);(3)在每个样本中随机选择 5 个帧,并在适当位置用12个副本替换它们(Rand Repli 表示随机复制)。

The LSTM based method may have too strong supervision of the sequential order, making it sensitive to gloss order. But one advantage of the proposed network is that the FCN model learns the glosses independently, so it is more robust to order-independent representations. To show this advantage, we may experimentally by shuffling the glosses in the testing samples. However, given no isolated annotations for individual glosses, we cannot manually construct “new” sentences with different signing orders by random shuffling. To mimic the shuffling idea, our fourth experiment is an imperfect but reasonable gloss shuffling experiment, as shown as Shuffle in Figure 5. We first temporally segment the input into two equal parts and insert one into another.
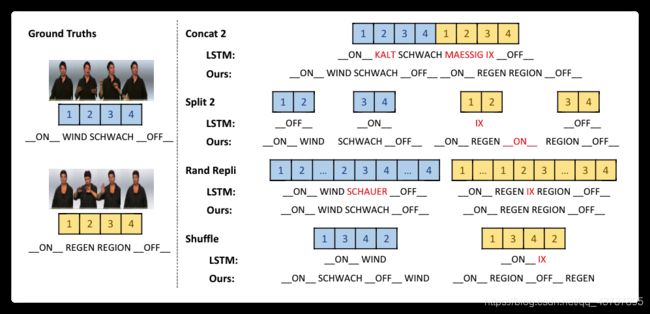 Fig. 5. Two samples are chosen for illustrating four different simulating scenarios for real-world recognition. Given that both the LSTM based method and the proposed network can recognize the original samples correctly, in all the simulating scenarios, the LSTM based method provides many false predictions while ours can preserve its accuracy. Errors are marked in red
Fig. 5. Two samples are chosen for illustrating four different simulating scenarios for real-world recognition. Given that both the LSTM based method and the proposed network can recognize the original samples correctly, in all the simulating scenarios, the LSTM based method provides many false predictions while ours can preserve its accuracy. Errors are marked in red
基于 LSTM 的方法可能对顺序序列是强监管,使其对顺序 gloss 非常敏感。但该网络的一个优点是 FCN 模型是独立学习光泽的,因此更难得到与顺序无关的表示。为了显示这一优势,我们可以在实验中通过重排测试样品中的 gloss 来实现。然而,由于没有对单个 gloss 进行孤立的注释,我们不能通过随机重排来手动构建具有不同手语顺序的“新”句子。为了模仿洗牌的想法,我们的第四个实验是一个不完美但合理的光泽重排实验,如图5所示。我们首先在时间上将输入分割成两个相等的部分,并将一个插入到另一个部分中。

图5. 选取两个样本来说明四种不同的真实世界识别模拟场景。考虑到基于 LSTM 的方法和所提出的网络都能正确识别原始样本,在所有的仿真场景中,基于 LSTM 的方法出现了许多错误预测,而我们的方法可以保持其准确性。错误用红色标记
The results of the four experiments are shown in Table 5. It is observed that the performance of the LSTM based network degrades dramatically in all these four types of simulating scenarios. On the contrary, the proposed network shows consistent overall performance across different scenarios. We only observe additional minor errors in the output steps where samples are combined or split due to the action inconsistencies introduced in boundary places.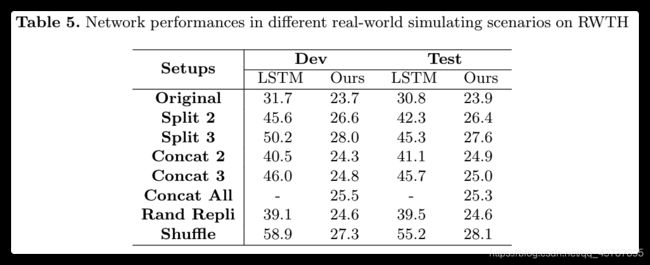
表5显示了四个实验的结果。实验结果表明,在这四种仿真场景中,基于 LSTM 的网络性能都有很大的下降。相反,我们提出的网络在不同场景中显示出一致的整体性能。我们只观察到由于边界处引入的动作不一致而导致样本合并或分离的输出步骤中的附加小错误。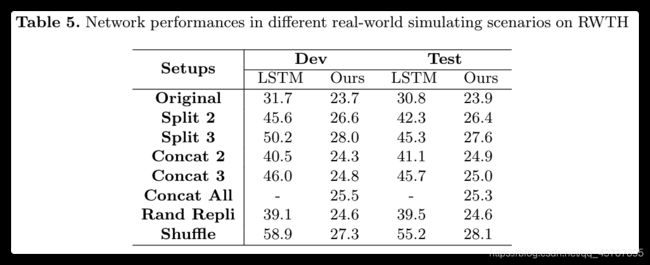
Discussion
Discussion. Considering the nature of the FCN design, the results further inspire us that even the proposed network is continuously being fed only a few frames that are needed (adequate) to infer the output, it can still combine all the intermediate outputs to give the same final recognition result. We use this technique to test for the Concat All scenario, where all testing samples are concatenated together as one large sample. Unfortunately, the LSTM based model fails to provide any result for the Concat All scenario, as the memory capacity limits the network to take such a large sample as an input.
讨论. 在 FCN 的基础上,我们提出的网络只需连续地传入(足够多的)推断出的几个帧,就可以组合所有的中间输出以给出与真实值相匹配的最终识别结果。我们使用此技术来在 Concat All 场景中测试,在该场景中,所有测试样本被连接在一起作为一个大样本。可惜,基于 LSTM 的模型无法在 Concat All 场景进行测试,因为大样本内存容量太大,无法作为输入。
All the results Table 5 indicate that the proposed network has more generalization capability and better flexibility for recognition in complex real-world recognition scenarios. The FCN design enables the proposed network to significantly reduce the memory usage for recognition. Meanwhile, indicated by the results in the Split and Concat scenarios, besides recognizing signing sentences, our method gives accurate recognition results for signing phrases and paragraphs. We can further conclude from the results in the Split scenarios that there is no need to wait for the arrival of all the signing glosses during the recognition process, as accurate intermediate (partial) recognition results can be given whenever adequate frames are available to the proposed network. With this great property, our method can provide intermediate results word by word along time, which is very friendly from a human-computer interaction perspective for SLR users. These properties make the proposed network have a promising application prospect for online recognition. A visual demonstration is shown in the supplementary demo video.
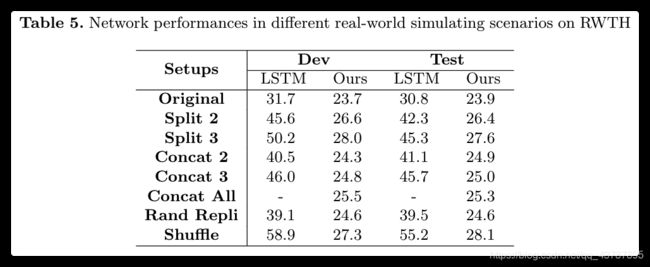
表5的所有结果表明,提出的网络具有更强的泛化能力和更好的识别灵活性,适用于复杂的现实认知场景。FCN 结构使得所提出的网络能够显著减少识别所需的存储器使用量。同时,在 Split 和 Concat 场景中的实验结果表明,该方法不但能识别孤立词手语的意思,还能识别出手语短语和段落的含义。我们可以从 Split 场景中的结果进一步得出结论,在识别过程中不需要等待所有手语 gloss 的到来,因为只要对所提出的网络有足够的帧可用,就可以给出准确的中间(部分)识别结果。有了这一特性,我们的方法可以长时间的逐字提供中间结果,从人机交互的角度来看,这对 SLR 用户来说是非常友好的。这些特性使得所提出的网络在在线识别方面有很好的应用前景。补充演示视频中显示了可视化演示。

5 Conclusions
In this paper, we are the first to propose a fully convolutional network that can be trained end-to-end without pre-training for continuous SLR. A jointly trained GFE module is introduced to enhance the representativeness of features. Experimental results show that the proposed network achieves state-of-the-art performance on benchmark datasets with RGB-based methods. For recognition in real-world scenarios where the LSTM based network mostly fails, the proposed network reaches consistent performance and shows many great advantageous properties. These advantages make our proposed network robust enough to do online recognition.
在本文中,我们首次提出了一种端到端训练的全卷积网络,该网络无需预训练就可用于连续手语识别。引入联合训练的 GFE 模型来增强特征的代表性。实验结果表明,该网络在基于 RGB 方法的基准数据集上取得了最好的性能。对于基于 LSTM 的网络在实际场景中的识别,该网络达到了一致的性能,并表现出许多极大的优势。这些优势使我们提出的网络鲁棒性好,可以进行在线识别。
One possible future research direction for continuous SLR is to strengthen the supervision by using the fact that some glosses are combinations of letter signs; however, this may require additional labeling pre-processing and professional knowledge in sign language. Also, the better gloss recognition accuracy obtained by the proposed network may have a good research prospect in sign language translation (SLT). Furthermore, we hope the proposed network can inspire future studies on sequence recognition tasks to investigate FCN architecture as an alternative to LSTM based models, especially for those tasks with limited data for training.
未来连续手语识别的一个可能的研究方向是利用一些 gloss 是由字母组合的事实来加强监督;然而,这可能需要额外的标记预处理和手语专业知识。此外,该网络具有更好的 gloss 识别精度,在手语翻译(SLT)中有很好的研究前景。此外,我们希望所提出的网络能够启发未来序列识别任务的研究,以探索 FCN 结构作为基于 LSTM 的模型的替代方案,特别是对于那些训练数据有限的任务。
paper原文链接点击下载
paper源码(一作、二作、三作都没有源码,建议参考其他 paper)
一作分享了他们在 rebuttal 时的一段话供参考:
The alignment proposal algorithm is very similar to the one proposed in the original paper of CTC - “Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks.” The author defines a forward variable, alpha(t)(s), to be the total probability of all possible paths corresponding to the given labeling sequence of length s at time t. The recursive algorithm for calculating the forward variable is also available. For a given sequence s at time t, instead of finding the total probability of all the possible paths, we find the maximum probability among them. All the other calculations are the same. The alignment proposal can then be obtained by backward tracing of the final forward variable. We do not include the algorithm for the alignment proposal, because the deviation is lengthy, and the focus of our paper is that the FCN method has better generalization capability and flexibility for SLR in real-world scenarios than the LSTM method.
一作也建议参考 A Deep Neural Framework for Continuous Sign Language Recognition by Iterative Training中关于 modified algorithm of CTC 的 implementation 写的还挺详细的,之前有读者复现了一下,应该挺快的因为它本质就是一个DP。