Python之如何使用pandas操作Excel表
目录
1、前言
2、读取Excel
3、对Excel进行操作
3.1、获取行号、列名
3.2、获取单元格的值,并循环输出
3.3、对空值进行处理,替换
3.4、增加一列,并对新增列的第一行进行赋值
3.5、将修改后数据保存到原文档
3.6、关于循环取数
4、错误处理
5、全部代码
1、前言
网上也有很多关于如何使用pandas对Excel表格进行操作的文章,本文纯当记录
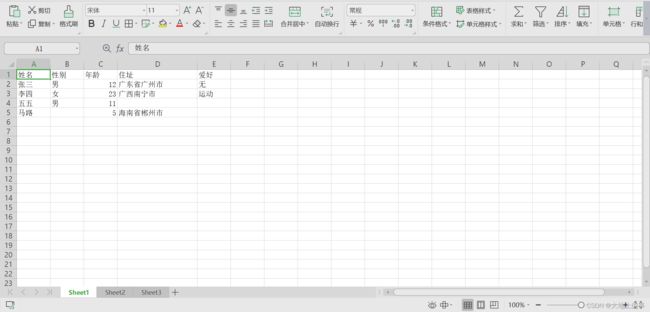
Excel原文件数据如下:
2、读取Excel
对Excel操作分两步:
1、首先要导入pandas库
2、设置Excel文件路径
注意:
pandas.read_excel(file, sheet_name=0, keep_default_na=False)
1、file为要读取的Excel文件
2、sheet_name表示要读取的sheet名,0表示第一个sheet,1表示第2个sheet,依次类推;也可以直接写sheet的名称,如sheet_name='Sheet1'
3、当Excel中有空值时,直接读取会显示nan,read_excel方法中加上keep_default_na=False后,
空值nan会变成:'' 空字符串,后续可用if cell_data=='' 进行判断
代码如下:
import pandas
file = r'D:\student.xlsx'
class opexcel():
def getdata(self, file):
data = pandas.read_excel(file, sheet_name=0, keep_default_na=False)
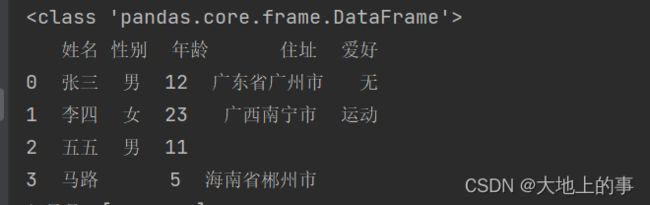
print(type(data)) # 输出数据类型(DataFrame)
print(data) # 输出数据
if __name__ == '__main__':
opexcel().getdata(file)
打印结果如下:
3、对Excel进行操作
3.1、获取行号、列名
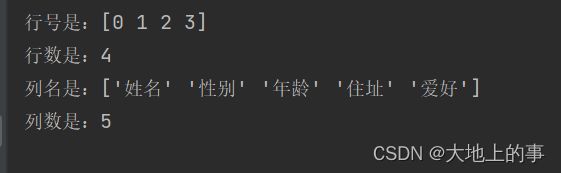
row_index = data.index.values # 行号: 数组形式
print('行号是:%s' % row_index)
row_num = len(data.index.values) # 行数
print('行数是:%s' % row_num)
col_index = data.columns.values # 列名: 数组形式
print('列名是:%s' % col_index)
col_num = len(data.columns.values) # 列数
print('列数是:%s' % col_num)
打印结果:
3.2、获取单元格的值,并循环输出
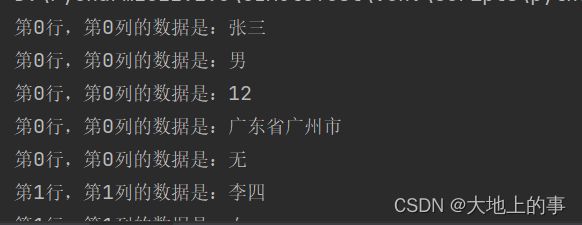
for i in range(row_num): # 循环行数
for j in range(col_num): # 循环列数
cell_data=data.iloc[i,j] # 获取单元格的值
print('第%s行,第%s列的数据是:%s ' %(i,i,cell_data))
打印结果如下:
3.3、对空值进行处理,替换
Excel文件中,某个单元格的值可能为空,直接读取会显示nan,且各个单元格的数据类型可能不一致,如date、str、int、float。这时如果直接读取,使用numpy.isnan()或者pandas.isnull()进行判断,都可能会报错,所以在开头读取Excel文件的方法pandas.read_excel(file, sheet_name=0, keep_default_na=False)中加上keep_default_na=False后,空值nan会变成:'' 空字符串。
现在我们想要将Excel中所有为空的单元格,替换为NULL字符串,操作如下
1、取出所有列名
2、循环列名,对空值替换(据实践,只有列名才有.replace()方法)
col_index = data.columns.values # 列名
for col in col_index :
data[col].replace('','NULL',inplace=True)
# 第一个参数是替换前的值,即Excel表指定列的值,如有多个相同的值,后续都会被替换
第二个参数是替换后的值,此处为字符串'NULL',也可填数字、或其他类型
第三个参数,是否替换,True为替换
print(data)
打印结果如下:
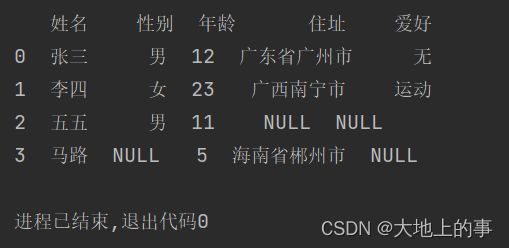
如要将上方结果中【爱好】这一列的【无】,替换为羽毛球,操作如下:
data['爱好'].replace('无','羽毛球',inplace=True)
结果如下:
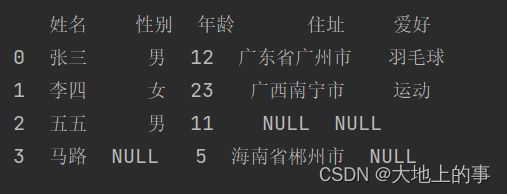
3.4、增加一列,并对新增列的第一行进行赋值
新增一列【成绩】,并赋值未None:
data['成绩']=None
打印结果如下:
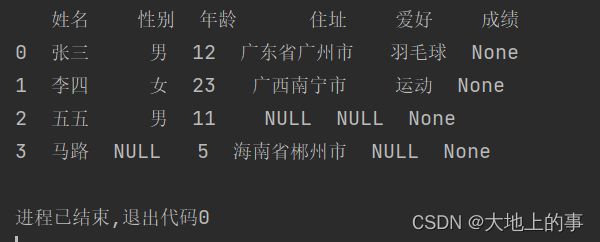
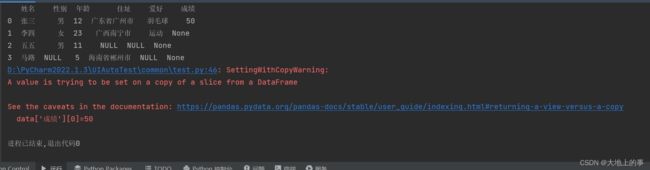
修改增列的第一行的值为50:
data['成绩'][0]=50
打印结果如下:
3.5、将修改后数据保存到原文档
注意:以上操作中将空值替换、新增列、修改单元格数据等编辑操作,只在控制台有效,实际文件的内容并不会被改变
file = r'D:\student.xlsx'
data.to_excel(file,sheet_name='Sheet1',index=False,header=True)
# 用DataFrame的to_excel方法可将编辑后的数据进行保存(前面第一节已知data为DataFrame类型)
1、第一个参数file,表示数据将要保存到这个文件。可以是原文件(r'D:\student.xlsx'),如果写另外的文件(r'D:/test/newstudent.xlsx'),则数据将保存到另一个文件中,原文件数据不变
2、第二个参数sheet_name,表示将数据保存到文件的哪一个sheet工作表。如工作表不存在则会报错。
3、第三个参数index,表示工作表自带的序号。如果设置index=True,则保存后的数据将多出一列
4、第四个参数header,表示列名。设置header=True,保存后的数据将带上列名;设置header=False,保存后的数据将没有列名
注意:
读取文件的时候,sheet_name可以写成 sheet_name=0或 sheet_name='Sheet1'
data = pandas.read_excel(file, sheet_name=0,keep_default_na=False)
写入文件的时候,只能填写工作表的名称sheet_name='Sheet1'
保存后的数据如下:
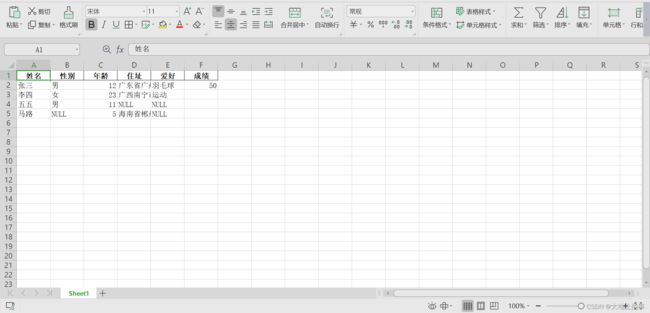
设置index=True,结果如下:
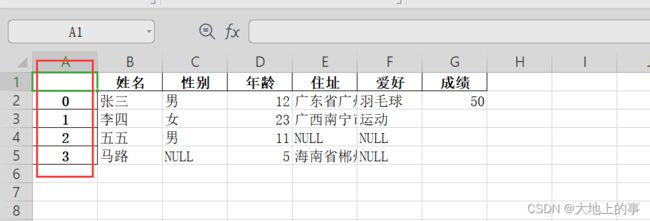
设置header=False,结果如下:
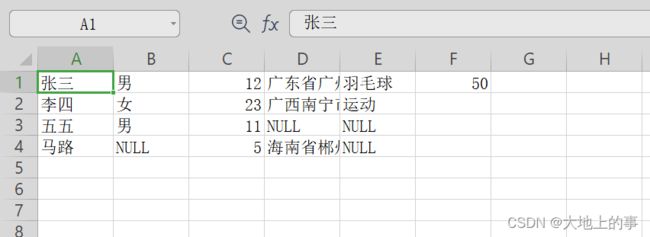
3.6、关于循环取数
col_index = data.columns.values # 列名 ['姓名' '性别' '年龄' '住址' '爱好' '成绩'] 数组,用in进行循环取值:for i in col_index: col_num = len(data.columns.values) # 列数 6 数值,用rang进行循环取数:for i in range(col_num :
3.7、字符串分割
url=data['URL'][0] # https://blog.csdn.net/m0_46400195/article/detailspy
print(url)
print(type(url))
str1=str(data['URL'][0]).split('/')
# 注意: 虽然显示URL为str类型,但是仍然要先将data['URL'][0]转为str,才能使用.split方法进行分割。str(data['URL'][0]).split('/'),也可以写成str(url).split('/')
print(str1) # 打印分割后的结果
newstr1=str1[0]+'//'+str1[2]+'/'+str1[3]+'/'+'druid' #根据分割后的信息进行拼接
newstr2 = str1[0] + '//' + str1[2] + '/' + str1[3]+'/' + 'druid/index.html'
print(newstr1) #打印拼接后的字符串
print(newstr2)
打印结果如下:

4、错误处理
1、PermissionError: [Errno 13] Permission denied
这个错误出现可能是文件未关闭,关闭后再操作即可。还有可能是文件损坏了,打开文件,确认文件内容是否正常
2、……
5、全部代码
import pandas
import requests
from pandas import DataFrame
import xlwt
'''
1、当Excel中有空值时,直接读取会显示nan,read_excel方法中加上keep_default_na=False后,
空值nan会变成:‘’ 空字符串,后续可用if cell_data=='' 进行判断
2、col_index = data.columns.values # 列名
数组col_index:['序号' '是否导出' '所属单位'],用in进行循环取值:for i in col_index:
row_num = len(data.index.values) # 行数
数值row_num:用rang进行循环取数:for i in range(row_num):
'''
file = r'D:\student.xlsx'
class opexcel():
def getdata(self, file):
data = pandas.read_excel(file, sheet_name=0,keep_default_na=False)
# 当Excel中有空值时,直接读取会显示nan,read_excel方法中加上keep_default_na=False后,
# 空值nan会变成:‘’ 空字符串,后续可用if cell_data=='' 进行判断
# print(type(data))
# print(data) # 输出数据
row_index = data.index.values # 行号: 数组形式 [0 1 2 3 4 5 6 7 8]
print('行号是:%s' % row_index)
row_num = len(data.index.values) # 行数
print('行数是:%s' % row_num)
col_index = data.columns.values # 列名: 数组形式['序号' '是否导出' '所属单位' '项目名称' '项目']
print('列名是:%s' % col_index)
col_num = len(data.columns.values) # 列数
print('列数是:%s' % col_num)
# data['result']=None
# data.to_excel(r'D:\userCase11.xls', sheet_name='Sheet1', index=False, header=True)
# for i in range(row_num): # 循环行数
# for j in range(col_num): # 循环列数
# cell_data=data.iloc[i,j] # 获取单元格的值
# print('第%s行,第%s列的数据是:%s ' %(i,i,cell_data))
#
# for col in col_index :
# data[col].replace('','NULL',inplace=True)
# print(data)
#
# data['爱好'].replace('无','羽毛球',inplace=True)
# print(data)
# data['成绩']=None
# print(data)
# data['成绩'][0]=50
# print(data)
# data.to_excel(file,sheet_name='Sheet1',index=False,header=False)
if __name__ == '__main__':
opexcel().getdata(file)