PyTorch学习笔记——入门(Tensor、Autograd、NN、图像分类器实验、数据并行处理)
PyTorch学习笔记
- 1 60min入门学习
-
- 1.1 张量
-
- 1.1.1 构造
- 1.1.2 Tensor操作
-
- 查看信息
- 改变形状
- 索引操作
- Tensor类型
- 逐元素操作
- 归并操作
- 比较
- 线性代数
- Tensor和Numpy
- 内部结构
- 其他
- 1.2 自动微分
-
- 1.2.1 required_grad
- 1.2.2 计算图
- 1.2.3 t.no_grad()与tensor.data()||tensor.detach()
- 1.2.4 查看非叶子节点的导数 autograd与hook
- 1.3 神经网络
-
- 1.3.1 定义网络(LeNet为例)
- 1.3.2 损失函数
- 1.3.3 优化器
- 1.4 实践操作(图像分类器)
-
- 1.4.1 前话
- 1.4.2 加载数据集
- 1.4.3 定义网络
- 1.4.4 构造loss和optimizer
- 1.4.5 训练网络
- 1.4.6 检测模型
- 1.4.7 在GPU训练
- 1.5 数据并行处理
-
- 1.5.1 包引用和数据声明
- 1.5.2 实验数据的加载
- 1.5.3 模型实现
- 1.5.4 数据并行处理
参考:PyTorch官方教程中文版、《深度学习框架PyTorch:入门与实践》
1 60min入门学习
1.1 张量
1.1.1 构造
from __future__ import print_function
import torch
import numpy as np
#构造方法,是可以指定dtype和device(cpu/gpu)
x = torch.empth(5, 3)#构造5x3矩阵,不初始化
x = torch.rand(5, 3)#随机初始化,[0,1)均匀分布
x = torch.randn(5, 3)#标准分布,均值为0,方差为1
x = torch.randperm(m)#0 ~ m-1 的随机排列
x = torch.normal(mean, std)#正态分布
x = torch.uniform(from, to)#均匀分布
x = torch.zeros(5, 3, dtype=torch.long)#构造全零矩阵,数据类型是long
x = torch.ones(5, 3)#全1
x = torch.eye(5, 3, dtype=torch.int)#对角线为1,其余为0,可以不是方阵
x = torch.arange(start, end, step)
x = torch.linspace(start,end,steps)#从s到e,均匀切分成steps份
#tensor与Tensor
#torch.Tensor(*sizes)创建tensor时,系统不会马上分配空间,只是会计算剩余的内存是否足够使用,使用到tensor时才会分配,而其它操作都是在创建完tensor之后马上进行空间分配。
x = torch.Tensor()#Tensor(),由tensor和empty组成可以新建空的张量,tensor不可以
x = torch.Tensor(2,3)#size构造,数值取决于内存空间的状态,print时候可能overflow
x = torch.Tensor([[1],[2]])#list构造
x = torch.tensor([5.5, 3])#直接构造张量,中间需要数据,torch.tensor([]).shape=torchSize([0])
#创建一个tensor基于已经存在的tensor
x = x.new_ones(5, 3, dtype=torch.double)
x = torch.randn_like(x, dtype=torch.float)
#tensor.new_*(new_shape) 新建一个不同形状的tensor。
#torch.*_like(tensora) 可以生成和tensora拥有同样属性(类型,形状,cpu/gpu)的新tensor。
1.1.2 Tensor操作
查看信息
x.tolist()#Tensor -> list
print(x.size())#同x.shape,查看shape,返回的torch.Size对象是一个tuple的子类
print(x.numel())#同x.nelement(),查看x中的元素个数5*3
改变形状
#view不会修改自身的数据,返回的新tensor与源tensor共享内存,也即更改其中的一个,另外一个也会跟着改变。
x = torch.randn(4,4)
y = x.view(16)
z = x.view(-1, 8)
#x.size([4, 4]) y.size([16]) z.size([2, 8])
#增添或减少某一维度
a = a.squeeze()#所有维度为1的压缩
a = a.squeeze(0)#压缩第0维的1,如[1,5,3] -> [5,3]
a = a.unsqueeze(1)#在第1维上增加1,如[5,3] -> [5,1,3]
#resize是另一种可用来调整size的方法,但与view不同,它可以修改tensor的大小。如果新大小超过了原大小,会自动分配新的内存空间,而如果新大小小于原大小,则之前的数据依旧会被保存。
索引操作
注意!对tensor的任何索引操作仍是一个tensor,想要获取标准的python对象数值,需要调用tensor.item(), 这个方法只对包含一个元素的tensor适用。
#如无特殊说明,索引出来的结果与原tensor共享内存,也即修改一个,另一个会跟着修改。
a = torch.randn(3, 4)
a[:2, 0:2] # 前两行,第0,1列
a[Node],shape # 为a新增一个轴,同a.view(1, a.shape[0], a.shape[1])
a > 1 # 返回一个ByteTensor
a[a>1] # 同a.masked_select(a>1),结果与源tensor不共享内存
a[torch.LongTensor([0,1])] # 第0行和第1行
a.index_select(self, dim, index) # 在指定维度dim上选取
a.mask_select(self, mask) # a.masked_select(a>1)
a.non_zero(self) # 非零元素的下标
gather(self, dim, index) # 根据index在dim上选取数据,输出的size与index一样
#Index tensor must have the same number of dimensions as input tensor
'''
out[i][j] = input[index[i][j]][j] # dim=0
out[i][j] = input[i][index[i][j]] # dim=1
'''
a = t.arange(0,16).view(4,4)
#选取对角线元素
index = t.LongTensor([[0,1,2,3]])
print(a.gather(0,index))#对每一列,取0、1、2、3行元素
'''
tensor([[ 0, 5, 10, 15]])
'''
#取反对角线上的元素
index = t.LongTensor([[3,2,1,0]]).t()
print(a.gather(1,index))
'''
tensor([[ 3],
[ 6],
[ 9],
[12]])
'''
#去反对角线上的元素
index = t.LongTensor([[3,2,1,0]])
print(a.gather(1,index))
'''
tensor([[12, 9, 6, 3]])
'''
#取两个对角线上的元素
index = t.LongTensor([[0,1,2,3],[3,2,1,0]]).t()
print(a.gather(1,index))
'''
tensor([[ 0, 3],
[ 5, 6],
[10, 9],
[15, 12]])
'''
'''
out = input.gather(dim, index)
-->近似逆操作
out = Tensor()
out.scatter_(dim, index)
'''
b = t.tensor([[ 0, 3], [ 5, 6], [10, 9], [15, 12]])
c = t.zeros(4,4)
c.scatter_(1, index, b.float())
print(c)
'''
tensor([[ 0., 0., 0., 3.],
[ 0., 5., 6., 0.],
[ 0., 9., 10., 0.],
[12., 0., 0., 15.]])
'''
高级索引可以看成是普通索引操作的扩展,但是高级索引操作的结果一般不和原始的Tensor共享内存。
x = t.arange(0,27).view(3,3,3)
print(x[[1,2,0], [0], [1]]) # x[2,0,1],x[1,0,1],x[0,0,1]
print(x[[0, 2], ...]) # x[0] x[2]
Tensor类型
| Data type | dtype | CPU tensor | GPU tensor |
|---|---|---|---|
| 32-bit floating point | torch.float32 or torch.float |
torch.FloatTensor |
torch.cuda.FloatTensor |
| 64-bit floating point | torch.float64 or torch.double |
torch.DoubleTensor |
torch.cuda.DoubleTensor |
| 16-bit floating point | torch.float16 or torch.half |
torch.HalfTensor |
torch.cuda.HalfTensor |
| 8-bit integer (unsigned) | torch.uint8 |
torch.ByteTensor |
torch.cuda.ByteTensor |
| 8-bit integer (signed) | torch.int8 |
torch.CharTensor |
torch.cuda.CharTensor |
| 16-bit integer (signed) | torch.int16 or torch.short |
torch.ShortTensor |
torch.cuda.ShortTensor |
| 32-bit integer (signed) | torch.int32 or torch.int |
torch.IntTensor |
torch.cuda.IntTensor |
| 64-bit integer (signed) | torch.int64 or torch.long |
torch.LongTensor |
torch.cuda.LongTensor |
#设置默认tensor
t.set_default_tensor_type('torch.DoubleTensor')#默认为FloatTensor
a = t.Tensor(2,3)#a.dtype=float64
#将a转化成FloatTensor
b = a.float()
b = a.type(t.FloatTensor)
a.new(2,3) # 等价于torch.DoubleTensor(2,3),建议使用a.new_tensor
逐元素操作
| 函数 | 功能 |
|---|---|
| abs/sqrt/div/exp/fmod/log/pow… | 绝对值/平方根/除法/指数/求余/求幂… |
| cos/sin/asin/atan2/cosh… | 相关三角函数 |
| ceil/round/floor/trunc | 上取整/四舍五入/下取整/只保留整数部分 |
| clamp(input, min, max) | 超过min和max部分截断 |
| sigmod/tanh… | 激活函数 |
对于很多操作,例如div、mul、pow、fmod等,PyTorch都实现了运算符重载,所以可以直接使用运算符。如a ** 2 等价于torch.pow(a,2), a * 2等价于torch.mul(a,2)。
归并操作
此类操作会使输出形状小于输入形状,并可以沿着某一维度进行指定操作。
常用归并操作
| 函数 | 功能 |
|---|---|
| mean/sum/median/mode | 均值/和/中位数/众数 |
| norm/dist | 范数/距离 |
| std/var | 标准差/方差 |
| cumsum/cumprod | 累加/累乘 |
以上大多数函数都有一个参数**dim**,用来指定这些操作是在哪个维度上执行的。keepdim参数决定size中是否有"1",keepdim=True会保留维度1。注意,以上只是经验总结,并非所有函数都符合这种形状变化方式,如cumsum。
假设输入的形状是(m, n, k)
- 如果指定dim=0,输出的形状就是(1, n, k)或者(n, k)
- 如果指定dim=1,输出的形状就是(m, 1, k)或者(m, k)
- 如果指定dim=2,输出的形状就是(m, n, 1)或者(m, n)
x = torch.rand(4,2,3)
y = torch.mean(x, dim=1, keepdim=True)#y.shape=[4,1,3],keepdim决定保留维度1
y = torch.mean(x, dim=0)#y.shape=[2,3]
比较
| 函数 | 功能 |
|---|---|
| gt/lt/ge/le/eq/ne | 大于/小于/大于等于/小于等于/等于/不等 |
| topk | 最大的k个数 |
| sort | 排序 |
| max/min | 比较两个tensor最大最小值 |
表中第一行的比较操作已经实现了运算符重载,因此可以使用a>=b、a>b、a!=b、a==b,其返回结果是一个ByteTensor,可用来选取元素。
a = t.rand(2,3)
b = t.rand(2,3)
print(a>b)
print(a[a>b])#a中大于b的元素
print(a.max)#返回a中最大元素
print(a, dim=1)#维数为1,返回tensor和下标
print(a,b)#两个tensor相比较大的元素
#比较a和10中较大的元素
t.clamp(a, min=10)
线性代数
| 函数 | 功能 |
|---|---|
| trace | 对角线元素之和(矩阵的迹) |
| diag | 对角线元素 |
| triu/tril | 矩阵的上三角/下三角,可指定偏移量 |
| mm/bmm | 矩阵乘法,batch的矩阵乘法 |
| addmm/addbmm/addmv/addr/badbmm… | 矩阵运算 |
| t | 转置 |
| dot/cross | 内积/外积 |
| inverse | 求逆矩阵 |
| svd | 奇异值分解 |
需要注意的是,矩阵的转置会导致存储空间不连续,需调用它的.contiguous方法将其转为连续。
b = a.t() # 转置
print(b.is_contiguous()) # False
b = b.contiguous()
Tensor和Numpy
a = tensor.ones(5)
b = a.numpy()#Tensor -> Numpy
a = np.ones(5)
b = tensor.from_numpy(a)#Numpy -> Tensor
#b = tensor.Tensor(a)
#!!!Tensor和numpy对象共享内存,所以他们之间的转换很快,而且几乎不会消耗什么资源。但这也意味着,如果其中一个变了,另外一个也会随之改变。
注意:
- 当numpy的数据类型和Tensor的类型不一样的时候,数据会被复制,不会共享内存。
- 不论输入的类型是什么,t.tensor都会进行数据拷贝,不会共享内存
广播法则
- 让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分通过在前面加1补齐
- 两个数组要么在某一个维度的长度一致,要么其中一个为1,否则不能计算
- 当输入数组的某个维度的长度为1时,计算时沿此维度复制扩充成一样的形状
a = t.ones(3, 2)
b = t.zeros(2, 3,1)
print(a+b)
# 自动广播法则
# 第一步:a是2维,b是3维,所以先在较小的a前面补1 ,
# 即:a.unsqueeze(0),a的形状变成(1,3,2),b的形状是(2,3,1),
# 第二步: a和b在第一维和第三维形状不一样,其中一个为1 ,
# 可以利用广播法则扩展,两个形状都变成了(2,3,2)
# 手动广播法则,expand不会额外占用空间
# 或者 a.view(1,3,2).expand(2,3,2)+b.expand(2,3,2)
a[None].expand(2, 3, 2) + b.expand(2,3,2)
内部结构
tensor分为头信息区(Tensor)和存储区(Storage),信息区主要保存着tensor的形状(size)、步长(stride)、数据类型(type)等信息,而真正的数据则保存成连续数组。由于数据动辄成千上万,因此信息区元素占用内存较少,主要内存占用则取决于tensor中元素的数目,也即存储区的大小。
绝大多数操作并不修改tensor的数据,而只是修改了tensor的头信息。这种做法更节省内存,同时提升了处理速度。在使用中需要注意。 此外有些操作会导致tensor不连续,这时需调用tensor.contiguous方法将它们变成连续的数据,该方法会使数据复制一份,不再与原来的数据共享storage。
上面说的普通索引共享内存是因为普通索引可以通过只修改tensor的offset,stride和size,而不修改storage来实现。
其他
y.add_(x)#inplace方式,adds x to y,y自身改变
y.add(x)#y自身不会改变
#!!使用张量会发生变化的操作有前缀'_',如a.add(b)加法返回一个新的tensor
#torch.tensor
ten = torch.tensor([5, 3])
scalar = torch.tensor(3)#scalar(3)
ten_1 = ten.clone()#与ten不共享内存
ten_1 = ten.detach()#与ten共享内存
#Tensor可通过.cuda 方法转为GPU的Tensor。
device = t.device("cuda:0" if t.cuda.is_available() else "cpu")
x = x.to(device)
y = y.to(x.device)
z = x+y
1.2 自动微分
计算图(Computation Graph)是现代深度学习框架如PyTorch和TensorFlow等的核心,其为高效自动求导算法——反向传播(Back Propogation)提供了理论支持,了解计算图在实际写程序过程中会有极大的帮助。
PyTorch在autograd模块中实现了计算图的相关功能,autograd中的核心数据结构是Variable。从v0.4版本起,Variable和Tensor合并。我们可以认为需要求导(requires_grad)的tensor即Variable. autograd记录对tensor的操作记录用来构建计算图。
Variable提供了大部分tensor支持的函数,但其不支持部分inplace函数,因这些函数会修改tensor自身,而在反向传播中,variable需要缓存原来的tensor来计算反向传播梯度。如果想要计算各个Variable的梯度,只需调用根节点variable的backward方法,autograd会自动沿着计算图反向传播,计算每一个叶子节点的梯度。
backward:variable.backward(gradient=None, retain_graph=None, create_graph=None)
- 对张量rensor设置属性
tensor.requires_grad = True,会开始跟踪针对 tensor 的所有操作。 - 完成计算后,可以调用
tensor.backward()来自动计算所有梯度。该张量的梯度将累积到tensor.grad属性中。 - 调用
rensor.detach(),停止 tensor 历史记录的跟踪,来将其与计算历史记录分离,并防止将来的计算被跟踪。 - 要停止跟踪历史记录(和使用内存),您还可以将代码块使用
with torch.no_grad():包装起来。
1.2.1 required_grad
from __future__ import print_function
import torch as t
import torchvision
import numpy as np
#设置requires_grad=True,pytorch 会自动调用autograd 记录操作
a = t.randn(3, 4, requires_grad=True)
a = t.randn(3,4).requires_grad_()
a = t.randn(3,4)
a.requires_grad = True
y = x.sum() # y依赖于x,required_grad自动设置为True
print(y, y.grad_fn)
'''
out -> tensor(4., grad_fn=)
每个张量都有一个 .grad_fn 属性保存着创建了张量的 Function 的引用,即在计算图中的位置,
如果用户自己创建张量,则g rad_fn 是 None 。
'''
#由用户创建的variable属于叶子节点
print(a.is_leaf,b.is_leaf)#True False
# c.grad是None, 因c不是叶子节点,它的梯度是用来计算a的梯度
# 所以虽然c.requires_grad = True,但其梯度计算完之后即被释放
对比autograd的计算结果与手动求导的误差
def f(x):#计算y
y = x**2 * t.exp(x)
return y
def gradf(x):#手动求导
dx = 2*x*t.exp(x) + x**2*t.exp(x)
return dx
x = t.randn(3,4, requires_grad=True)
y = f(x)
y.backward(t.ones(y.size()))#当y不只一个元素时,需要指定gradient的形状与y一致
print(x.grad)
print(gradf(x))#两者一致
1.2.2 计算图
x = t.ones(1)
b = t.rand(1, requires_grad=True)
w = t.rand(1, requires_grad=True)
y = w * x
z = y + b
print(x.requires_grad, b.requires_grad, w.requires_grad, y.requires_grad)
#False True True True
print(x.is_leaf, b.is_leaf, w.is_leaf, y.is_leaf, z.is_leaf)
#True True True False False
print(z.grad_fn)#z为add函数的输出
# , 0), (, 0))
#第一个是y,是函数mul的输出,第二个是b是用户创建的叶子节点,为None
print(z.grad_fn.next_functions[0][0] == y.grad_fn)
#True
print(y.grad_fn.next_functions)
#((, 0), (None, 0))
#第一个是w叶子节点需要求导,梯度是累加的,,第二个是x不需要求导,为None
print(w.grad_fn, b.grad_fn)
#None None叶子节点的grad_fn为None
'''
计算w的梯度的时候,需要用到x的数值,这些数值在前向过程中会保存成buffer,
在计算完梯度之后会自动清空。为了能够多次反向传播需要指定retain_graph来保留这些buffer。
'''
z.backward(retain_graph=True)
print(w.grad)#tensor([1.])
# 多次反向传播,梯度累加,这也就是w中AccumulateGrad标识的含义
z.backward()
print(w.grad)#tensor([2.])
'''
PyTorch使用的是动态图,它的计算图在每次前向传播时都是从头开始构建,
所以它能够使用Python控制语句(如for、if等)根据需求创建计算图。
'''
def abs(x):
if x.data[0]>0: return x
else: return -x
x = t.ones(1, requires_grad=True)
y = abs(x)
y.backward()
print(x.grad) # tensor([1.])
'''
x = -1*t.ones(1)
x.requires_grad_() # 在声明x时,不可以直接设置
输出的是tensor([-1.])
'''
1.2.3 t.no_grad()与tensor.data()||tensor.detach()
有些时候我们可能不希望autograd对tensor求导。认为求导需要缓存许多中间结构,增加额外的内存/显存开销,那么我们可以关闭自动求导。对于不需要反向传播的情景(如inference,即测试推理时),关闭自动求导可实现一定程度的速度提升,并节省约一半显存,因其不需要分配空间计算梯度。
1、可以使用with t.no_grad():
2、使用t.set_grad_enabled(False)和t.set_grad_enabled(True)
如果想要修改tensor的值,又不希望被autograd记录,可以对tensor.data进行修改
a = t.ones(3,4,requires_grad=True)
print(a.data.requires_grad)#False
a.data.sigmoid_()
#a.sigmoid_() # tensor不可以直接使用inplace运行时报错
print(a)#其中a的值已经发生改变
#我们希望对tensor,但是又不希望被记录, 可以使用tensor.data 或者tensor.detach()
b = t.ones(3,4,requires_grad=True)
c = a * b
tensor = a.detach()#同tensor=a.data,但是tensor如果修稿,backward可能会报错
print(tensor.requires_grad) # False
mean = tensor.mean()#统计tensor的指标,但是不希望被记录
tensor.sigmoid_()#inplace操作
#c.backward()
'''这里报错是因为c必须是一个scalar'''
c.sum().backward()
'''这里报错了,因为 c=a*b, b的梯度取决于a,现在修改了tensor,其实也就是修改了a,梯度不再准确。
只有对variable的操作才能使用autograd,如果对variable的data直接进行操作,将无法使用反向传播。除了对参数初始化,一般我们不会修改variable.data的值。'''
1.2.4 查看非叶子节点的导数 autograd与hook
在反向传播过程中非叶子节点的导数计算完之后即被清空。若想查看这些变量的梯度,有两种方法:使用autograd.grad函数 或者 使用hook
1、grad查看z对y的梯度:t.autograd.grad(z, y)
2、hook
# hook是一个函数,输入是梯度,不应该有返回值
def variable_hook(grad):
print('y的梯度:',grad)
x = t.ones(3, requires_grad=True)
w = t.rand(3, requires_grad=True)
y = x * w
# 注册hook
hook_handle = y.register_hook(variable_hook)
z = y.sum()
z.backward()
# 除非你每次都要用hook,否则用完之后记得移除hook
hook_handle.remove()
注意!!
-
如果 Tensor 是标量(即它包含一个元素数据),则不需要指定任何参数backward(),但是如果它有更多元素,则需要指定一个gradient 参数来指定张量的形状。
v = t.tensor([0.1, 1.0, 0.0001], dtype=t.float) y.backward(v) -
grad在反向传播过程中是累加的,反向传播之前需把梯度清零
x.grad.data.zero_() y.backward()#反向传播计算梯度 print(x.grad)#这里每个值的梯度为1 -> tensor([[1., 1.], [1., 1.]])
1.3 神经网络
神经网络可以通过 torch.nn 包来构建。
1.3.1 定义网络(LeNet为例)
import torch.nn as nn
import torch.nn.functional as F
'''
定义网络时,需要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数__init__中。
如果某一层(如ReLU)中没有需要更新的参数,则既可以放在构造函数中,也可以不放,但建议不放在其中,而在forward中使用nn.functional代替
'''
class Net(nn.Module):
def __init__(self):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(Net, self).__init__()
#卷积层
self.conv1 = nn.Conv2d(1, 6, 5)#输入通道、输出通道、卷积核大小
self.conv2 = nn.Conv2d(6, 16, 5)
#全连接层,y = Wx + b
self.fc1 = nn.Linear(16*5*5, 120)#输入维度、输出维度
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
#只要在nn.Module的子类中定义了forward函数,backward函数就会自动被实现(利用autograd)。
def forward(self, x):
#卷积-》激活-》池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2,2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
#reshape
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] #除了batch数量之外的所有维度
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
'''
Net(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
'''
input = t.randn(1,1,32,32)
out = net(input)
net.zero_grad()#参数的梯度清零
out.backward(t.ones(1,10))#反向传播
-
网络的可学习参数通过
net.parameters()返回,for name,parameters in net.named_parameters():可查看学习的参数及名称。for name,para in net.named_parameters(): print(name, para) -
forward函数的输入和输出都是Tensor。
-
torch.nn只支持mini-batches,不支持一次只输入一个样本。但如果只想输入一个样本,则用
input.unsqueeze(0)将batch_size设为1。
1.3.2 损失函数
一个损失函数需要一对输入:模型输出和目标,然后计算loss。nn实现了神经网络中大多数的损失函数,例如nn.MSELoss用来计算均方误差,nn.CrossEntropyLoss用来计算交叉熵损失。
output = net(input)
target = t.arange(0,10).view(1,10).float()#维数与模型输出相同
criterion = nn.MSELoss()
loss = criterion(output, target)#损失函数有两个输入:模型输出和目标,即y_hat与y
print(loss)
net.zero_grad()#清空梯度
print('1',net.conv1.bias.grad)
loss.backward()
print('2',net.conv1.bias.grad)
1.3.3 优化器
更新参数:weight = weight - learning_rate * gradient
可以使用python实现:
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)#data为获取内部tensor,不能省略
、、、
import torch.optim as optim
#新建一个优化器,指定要调整的参数和学习率
optimizer = optim.SGD(net.parameters(), lr = 0.01)
# 在训练过程中
# 先梯度清零(与net.zero_grad()效果一样)
optimizer.zero_grad()
# 计算损失
output = net(input)
loss = criterion(output, target)
#反向传播
loss.backward()
#更新参数
optimizer.step()
1.4 实践操作(图像分类器)
torchvision实现了常用的图像数据加载功能,例如Imagenet、CIFAR10、MNIST等,以及常用的数据转换操作,这极大地方便了数据加载,并且代码具有可重用性。
1.4.1 前话
参考:PyTorch图像分类
实验用到了CIFAR10图片数据集,包含十个类别:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’,尺寸为3x32x32。
使用torchvision加载并且归一化CIFAR10的训练和测试数据集
定义一个卷积神经网络
定义一个损失函数
在训练样本数据上训练网络
在测试样本数据上测试网络
1.4.2 加载数据集
import torch as t
import torchvision as tv
import torchvision.transforms as transforms
#定义对数据的预处理操作
transfrom = transforms.Compose([
transforms.ToTensor(),#转化为Tensor
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))#归一化操作,RGB每层用到的均值和方差
])
#训练集
#Dataset对象是一个(data,label)数据集
trainset = tv.datasets.CIFAR10(
root='./data2-1/',
train=True,
transform=transfrom,
download=True,
)
#Dataloader是可迭代对象,将dataset返回的每一条数据拼接成一个batch
trainloader = t.utils.data.DataLoader(
trainset,
batch_size=4,
shuffle=True,
num_workers=0#我是win10系统,不知道为什么设置成别的数值会报错……
)
#测试集
testset = tv.datasets.CIFAR10(
root='./data2-1/',
train=False,
download=True,
transform=transfrom
)
testloader = t.utils.data.DataLoader(
testset,
batch_size=4,
shuffle=False,
num_workers=0
)
classes = ('plane,', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
使用torchvision下载CIFAR10数据集真的太慢了QAQ,后来从别的地方下载了数据集之后,想从本地直接导入,但是发现单单设置root参数和download=False总是报错。
下面是从本地导入数据集的方法
数据集下载:链接: https://pan.baidu.com/s/1VTCioXE91vwZW8vd9aLmMg 提取码: sdbz
1、将数据集保存到本地,在浏览器中打开文件所在路径

2、打开cifar.py文件(在PyCharm中输入tv.datasets.cifar(),Ctrl+左键即可打开),修改url(改为上一步浏览器的路径+文件名就行了)
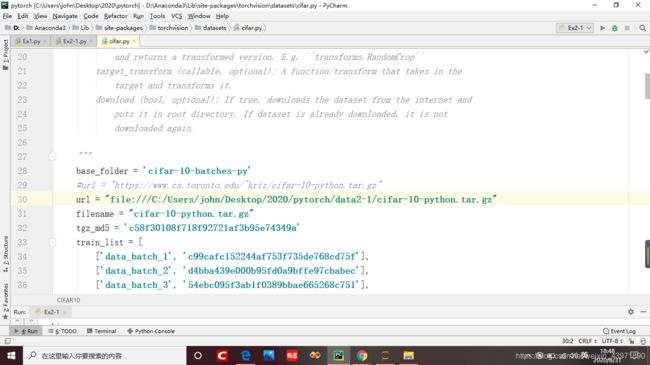
然后再运行之前的代码,就可以直接从本地加载数据集啦~
- 展示单个图片
import matplotlib.pyplot as plt
import numpy as np
def imshow(image):
img = image / 2 + 0.5#还原归一化的数据
npimg = img.numpy()#Tensor->numpy
plt.imshow(np.transpose(npimg, (1,2,0)))#转置为(y,z,x)
plt.show()
(data, label) = trainset[100]
print(classes[label])
print(data)
- 展示一组图片
dataiter = iter(trainloader)#定义迭代器
image, label = dataiter.next()#返回一个batch中的data和label
print(' '.join('%10s'%classes[label[j]] for j in range(4)))
imshow(tv.utils.make_grid(image))#将图片排列成网状结构,宽度nrow=8
1.4.3 定义网络
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
class Net(nn.Module):
def __init__(self):#注意不要写成int(说多了都是泪QAQ)
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)#RGB模式的输入通道数为3
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2,2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
'''
Net(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
'''
1.4.4 构造loss和optimizer
注意:nn.CrossEntropyLoss() 包括了将output进行Softmax操作的,所以直接输入output即可。其中还包括将label转正one-hot编码,所以直接输入label。该函数限制了target的类型为torch.LongTensor。label_tgt = make_variable(torch.ones(feat_tgt.size(0)).long())可在后边直接.long()。其output,label的shape可以不一致。
criterion = nn.CrossEntropyLoss()#交叉熵损失函数
optomizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
1.4.5 训练网络
t.set_num_threads(8)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):#enumerate(iterable[, start]) -> iterator for index, value of iterable
#输入数据
inputs, labels = data#每一个batch中有4个样本
#梯度清零
optimizer.zero_grad()
#forward+backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
#更新参数
optimizer.step()
#打印loss信息,其中loss是一个scalar,使用.item()获取信息
running_loss += loss.item()
if i%2000 == 1999:#每2000个batch打印一次训练状态
print('[%d %5d] loss: %.3f'%(epoch+1, i+1, running_loss / 2000))#[迭代次数 batch编号]
running_loss = 0.0
print('finished')
t.save(net,"model")#保存模型
'''
[1 2000] loss: 2.235
[1 4000] loss: 1.909
[1 6000] loss: 1.697
[1 8000] loss: 1.588
[1 10000] loss: 1.512
[1 12000] loss: 1.512
[2 2000] loss: 1.418
[2 4000] loss: 1.365
[2 6000] loss: 1.362
[2 8000] loss: 1.330
[2 10000] loss: 1.325
[2 12000] loss: 1.303
finished
'''
保存与加载模型的方法
1.4.6 检测模型
- 取一个batch进行测试
net = t.load("model")#加载模型
dataiter = iter(testloader)
images, labels = dataiter.next()
print("实际的label:"," ".join("%08s"%classes[labels[j]] for j in range(4)))
#imshow(tv.utils.make_grid(images))
'''
输出的outputs是torch.autograd.Variable格式,得到输出后采用torch.max获得样本的类别信息。
torch.max(input, dim, keepdim=False, out=None) -> (Tensor, LongTensor)
第一个输入是tensor格式,所以用outputs.data而不是outputs作为输入;
第二个dim=1是取每一行的最大值,返回的是最大元素在这一行的列索引;
'''
outputs = net(images)
_, predicted = t.max(outputs.data, 1)
print("预测结果:"," ".join('%5s'%classes[predicted[j]] for j in range(4)))
'''
实际的label: cat ship ship plane,
预测结果: cat ship ship ship
'''
- 整体测试集测试
net = t.load("model")
correct = 0#正确测试的个数
total = 0#测试的图片数
#测试时不需要求导,可以先关闭autograd,提速
with t.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = t.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print("准确率:%d %%"%(100 * correct // total))
'''
准确率:54 %
'''
- 模型在每个类别准确率的评估
class_correct = list(0. for i in range(10))#十个0.0
class_total = list(0. for i in range(10))
with t.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = t.max(outputs, 1)
#c = (predicted == labels).squeeze()
c = (predicted == labels)
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] // class_total[i]))
'''
Accuracy of plane, : 52 %
Accuracy of car : 62 %
Accuracy of bird : 24 %
Accuracy of cat : 44 %
Accuracy of deer : 51 %
Accuracy of dog : 36 %
Accuracy of frog : 75 %
Accuracy of horse : 58 %
Accuracy of ship : 80 %
Accuracy of truck : 55 %
'''
1.4.7 在GPU训练
device = t.device("cuda:0" if t.cuda.is_available() else "cpu")
net.to(device)
images, labels = images.to(device), labels.to(device)
output = net(images)
loss= criterion(output,labels)
print(loss)
'''
tensor(0.9488, device='cuda:0', grad_fn=)
'''
1.5 数据并行处理
1.5.1 包引用和数据声明
import torch as t
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
input_size = 5
output_size = 2
batch_size = 30
data_size = 100#数据量
#声明设备
device = t.device("cuda:0" if t.cuda.is_available() else "cpu")
1.5.2 实验数据的加载
'''
继承Datasets必须继承__init_()和__getitim__()
__init__()方法中得到图像的路径,然后将图像路径组成一个数组,这样在__getitim__()中就可以直接读取.
'''
class RandomDataset(Dataset):
def __init__(self, size, length):
#size为输入维度,length为数据量
self.len = length
self.data = t.randn(length, size)#[data_size, n_x]
def __getitem__(self, index):
#这个方法是必须要有的,用于按照索引读取每个元素的具体内容
'''
1、从文件中读取一个data
2、预处理数据
3、返回数据对(例如图像和标签)。
这里需要注意的是,第一步:read one data,是一个data
'''
return self.data[index]
def __len__(self):
#这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size), batch_size=batch_size, shuffle=True)
1.5.3 模型实现
'''
我们放置了一个输出声明在模型中来检测输出和输入张量的大小。请注意在 batch rank 0 中的输出。
'''
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
model = Model(input_size, output_size)
1.5.4 数据并行处理
if t.cuda.device_count() > 1:#是否有多个GPU
print("Let's use", t.cuda.device_count(), "GPUs!")
#在3GPUs中设置dim=0,[30,xxx] -> [10,xxx],[10,xxx],[10,xxx
model = nn.DataParallel(model)#如果我们有多个GPU,可以用 nn.DataParallel模型
model.to(device)
#运行模型,查看输入和输出张量的大小。
for data in rand_loader:
input = data.to(device)
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())
'''
我没有 GPU ,模型获得 30 个输入和 30 个输出。
3个GPU的输出是这样的:
Let's use 3 GPUs!
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2])
Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2])
In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2])
Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
'''