Python数据挖掘 数据预处理案例(以航空公司数据为例)
Python数据预处理
一、内容:
1、数据清洗
2、数据集成
3、数据可视化
二、实验数据
根据航空公司系统内的客户基本信息、乘机信息以及积分信息等详细数据,依据末次飞行日期( LAST_FLIGHT_DATE),以2014年3月31日为结束时间,选取宽度为两年的时间段作为分析观测窗口,抽取观测窗口2012年4月1日至2014年3月31日内有乘机记录的所有客户的详细数据形成历史数据,分为air_data01.xlsx、air_data02.xlsx总共62988条记录。其中包含了会员卡号、入会时间、性别、年龄、会员卡级别、工作地城市、工作地所在省份、工作地所在国家、观测窗口结束时间、观测窗口乘机积分、飞行公里数、飞行次数、飞行时间、乘机时间间隔、平均折扣率等44个属性,如下表2-1所示。

三、设计方案
1、数据清洗:
a.首先将数据进行统计性分析,查找每列属性观测值中的空值个数最大值、最小值。得到的分析结果表如下表3-1所示。通过对原始数据观察发现数据中存在票价为空值的记录,同时存在票价最小值为0、折扣率最小值为0但总飞行公里数大于0的记录。票价为空值的数据可能是客户不存在乘机记录造成的。其他的数据可能是客户乘坐0折机票或者积分兑换造成的。

b.紧接着是分别对air_data01、air_data02两个数据集进行读取,并进行重复数据筛选与删除,对绘制箱型图年龄和票价为空的记录等异常值进行发现与删除,保留清洗后的数据。
2.数据集成
这一步是将数据清洗后的air_data01、air_data02两个数据集合并存放在一个数据存储中(cleanedfile_finish.csv),目的是为了便于后续的数据挖掘工作。
3.数据可视化
使用数据集成后的新产生的多维数据集cleanedfile_finish.csv对数据进行可视化操作,并对表格中的统计数据完成直方图、饼图、条形图、箱型图、热力图的绘制。
四、实验结论
1、程序源代码
1)数据清洗
a、准备工作:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
b、数据统计性分析:
datafile= 'air_data01.xlsx' # 航空原始数据,第一行为属性标签
resultfile = 'explore.csv' # 数据统计性分析结果表
data = pd.read_excel(datafile)
datafile2= 'air_data02.xlsx'
resultfile2 = 'explore2.csv'
data2 = pd.read_excel(datafile2)
explore = data.describe(percentiles = [], include = 'all').T # T是转置
explore['null'] = len(data)-explore['count']
explore = explore[['null', 'max', 'min']]
explore.columns = ['空值数', '最大值', '最小值'] # 表头重命名
explore.to_csv('resultfile.csv') # 导出结果
explore2 = data2.describe(percentiles = [], include = 'all').T # T是转置
explore2['null'] = len(data)-explore2['count']
explore2 = explore2[['null', 'max', 'min']]
explore2.columns = ['空值数', '最大值', '最小值']
explore2.to_csv('resultfile2.csv')
datatemp = pd.concat([explore,explore2],axis=0)
datatemp.to_csv('data_Statistical analysis.csv') # 导出最终结果
通过对原始数据观察发现数据中存在票价为空值的记录,同时存在票价最小值为0、折扣率最小值为0但总飞行公里数大于0的记录。票价为空值的数据可能是客户不存在乘机记录造成的。其他的数据可能是客户乘坐0折机票或者积分兑换造成的。所以后面我们将对这一部分数据进行清除操作。
c、对数据集进行读取:
df1 = pd.read_excel('air_data01.xlsx')
df2 = pd.read_excel('air_data02.xlsx')
对重复数据进行删除:
def df_drop(df): #删除重复数据
print("yunxingle")
df_1 = df.duplicated() #进行重复判断
print("重复判断\n:",df_1)
df_2 = df[df.duplicated()]#显示重复数据sss
print("\n\n\n重复数据\n",df_2)
df_new = df.drop_duplicates() #删除重复数据
return df_new
df_drop(df1)
df_drop(df2)
d、对缺失行进行删除:
def df_kong(df):
df_1 = df.apply(lambda col:sum(col.isnull())/col.size)
print('\n判断缺失情况:\n\n',df_1)
df_2 = df.dropna(how='any')#删除所有含有缺失值的行
print(df_2.head(10))
return df_2
df_kong(df1)
df_kong(df2)
e、合并数据并保存:
data_new1 = df_kong(df_drop(df1))
data_new2 = df_kong(df_drop(df2))
data_integrated = pd.concat([data_new1,data_new2],axis=1)
data_integrated.to_csv('data_integrated.csv') # 保存清洗后的数据
f、异常值清除:
data = pd.read_csv('data_integrated.csv')
# data = data_new1
age = data['AGE'].dropna()
age = age.astype('int64')
# 绘制会员年龄分布箱型图
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
fig = plt.figure(figsize = (5 ,10))
plt.boxplot(age, patch_artist=True,
labels = ['会员年龄'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('会员年龄分布箱线图')
# 显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
plt.close()
# 箱型图显示年龄数据存在有大于100的异常值,下面予以修正
print('原始数据的形状为:',data.shape)
index = data['AGE'] > 100 # 去除年龄大于100的记录
data2 = data[~index]
print('数据清洗后数据的形状为:',data2.shape)
data2.to_csv('cleanedfile_01.csv') # 保存清洗后的数据
age = data2['AGE'].dropna()
age = age.astype('int64')
# 绘制会员年龄分布箱型图
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
fig2 = plt.figure(figsize = (5 ,10))
plt.boxplot(age, patch_artist=True,
labels = ['会员年龄'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('会员年龄分布箱线图')
# 显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
plt.close()
data3 = pd.read_csv('cleanedfile_01.csv',encoding = 'utf-8')
print('原始数据的形状为:',data3.shape)
# 去除票价为空的记录
data3_notnull = data3.loc[data3['SUM_YR_1'].notnull() &
data3['SUM_YR_2'].notnull(),:]
print('删除缺失记录后数据的形状为:',data3_notnull.shape)
# data3_notnull.to_csv('data3_notnull.csv') # 保存清洗后的数据
# 只保留票价非零的,或者平均折扣率不为0且总飞行公里数大于0的记录。
index1 = data3_notnull['SUM_YR_1'] != 0
index2 = data3_notnull['SUM_YR_2'] != 0
index3 = (data3_notnull['SEG_KM_SUM']> 0) & (data3_notnull['avg_discount'] != 0)
cleanedfile_02 = data3_notnull[(index1 | index2) & index3]
print('数据清洗后数据的形状为:',cleanedfile_02.shape)
cleanedfile_02.to_csv('cleanedfile_finish1.csv') # 保存清洗后的数据
2)数据集成
data_new1 = df_kong(df_drop(df1))
data_new2 = df_kong(df_drop(df2))
data_integrated = pd.concat([data_new1,data_new2],axis=1)#数据集成
data_integrated.to_csv('data_integrated.csv') # 保存清洗后的数据
3)数据可视化
a、准备工作:
import pandas as pd
import matplotlib.pyplot as plt
datafile= 'cleanedfile_finish.csv'
b、各年份会员入会人数直方图绘制:
from datetime import datetime
ffp = data['FFP_DATE'].apply(lambda x:datetime.strptime(x,'%Y-%m-%d'))
ffp_year = ffp.map(lambda x : x.year)
# 绘制各年份会员入会人数直方图
fig = plt.figure(figsize = (8 ,5))
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
plt.hist(ffp_year, bins='auto', color='#0504aa')
plt.xlabel('年份')
plt.ylabel('入会人数')
plt.title('各年份会员入会人数')
plt.show()
plt.close
c、会员性别比例饼饼图绘制:
male = pd.value_counts(data['GENDER'])['男']
female = pd.value_counts(data['GENDER'])['女']
# 绘制会员性别比例饼图
fig = plt.figure(figsize = (7 ,4)) # 设置画布大小
plt.pie([ male, female], labels=['男','女'], colors=['lightskyblue', 'lightcoral'],
autopct='%1.1f%%')
plt.title('会员性别比例')
plt.show()
plt.close
d、会员各级别人数条形图绘制:
lv_four = pd.value_counts(data['FFP_TIER'])[4]
lv_five = pd.value_counts(data['FFP_TIER'])[5]
lv_six = pd.value_counts(data['FFP_TIER'])[6]
# 绘制会员各级别人数条形图
fig = plt.figure(figsize = (8 ,5)) # 设置画布大小
plt.bar(x=range(3), height=[lv_four,lv_five,lv_six], width=0.4, alpha=0.8, color='skyblue')
plt.xticks([index for index in range(3)], ['4','5','6'])
plt.xlabel('会员等级')
plt.ylabel('会员人数')
plt.title('会员各级别人数')
plt.show()
plt.close()
e、会员年龄分布箱型图绘制:
age = data['AGE'].dropna()
age = age.astype('int64')
# 绘制会员年龄分布箱型图
fig = plt.figure(figsize = (5 ,10))
plt.boxplot(age,
patch_artist=True,
labels = ['会员年龄'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'})
plt.title('会员年龄分布箱线图')
plt.grid(axis='y')
plt.show()
plt.close
f、最后乘机至结束时长箱型图绘制:
fig = plt.figure(figsize = (5 ,8))
plt.boxplot(lte,最后乘机至结束时长箱线图
patch_artist=True,
labels = ['时长'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'})
plt.title('会员最后乘机至结束时长分布箱线图')
plt.grid(axis='y')
plt.show()
plt.close
g、客户飞行次数箱型图绘制:
fig = plt.figure(figsize = (5 ,8))
plt.boxplot(fc,
patch_artist=True,
labels = ['飞行次数'],
boxprops = {'facecolor':'lightblue'})
plt.title('会员飞行次数分布箱线图')
# 显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
plt.close
h、客户总飞行公里数箱型图绘制:
fig = plt.figure(figsize = (5 ,10))
plt.boxplot(sks,
patch_artist=True,
labels = ['总飞行公里数'],
boxprops = {'facecolor':'lightblue'})
plt.title('客户总飞行公里数箱线图')
# 显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
plt.close
i、会员兑换积分次数直方图绘制:
ec = data['EXCHANGE_COUNT']
fig = plt.figure(figsize = (8 ,5))
plt.hist(ec, bins=5, color='#0504aa')
plt.xlabel('兑换次数')
plt.ylabel('会员人数')
plt.title('会员兑换积分次数分布直方图')
plt.show()
plt.close
j、计算相关矩阵并绘制热力图:
data_corr = data[['FFP_TIER','FLIGHT_COUNT','LAST_TO_END',
'SEG_KM_SUM','EXCHANGE_COUNT','Points_Sum']]
age1 = data['AGE'].fillna(0)
data_corr['AGE'] = age1.astype('int64')
data_corr['ffp_year'] = ffp_year
dt_corr = data_corr.corr(method = 'pearson')
print('相关性矩阵为:\n',dt_corr)
import seaborn as sns
plt.subplots(figsize=(10, 10))
sns.heatmap(dt_corr, annot=True, vmax=1, square=True, cmap='Blues')
plt.show()
plt.close
2、程序相关结果展示
1)数据清洗
a、数据统计性分析:
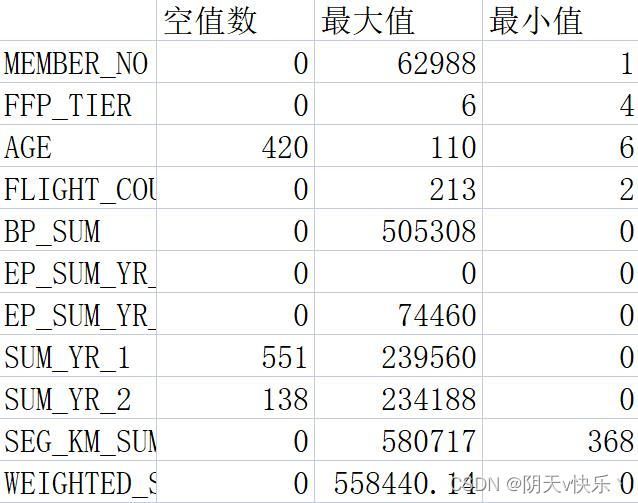
通过对原始数据观察发现数据中存在票价为空值的记录,同时存在票价最小值为0、折扣率最小值为0但总飞行公里数大于0的记录。票价为空值的数据可能是客户不存在乘机记录造成的。其他的数据可能是客户乘坐0折机票或者积分兑换造成的。所以后面我们将对这一部分数据进行清除操作。
c、重复值分析:
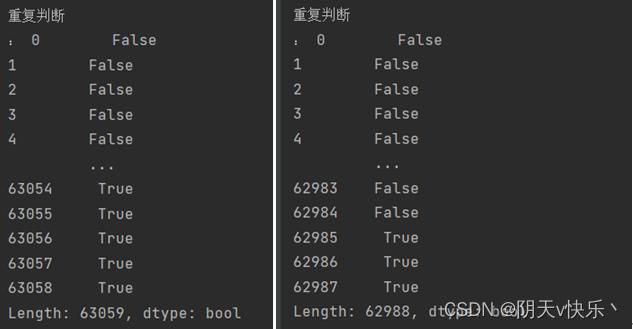
如图示,显示有重复数据,下面我们将重复数据进行展示。可以看出air_data01有71行重复数据。air_data02有1738行重复数据。
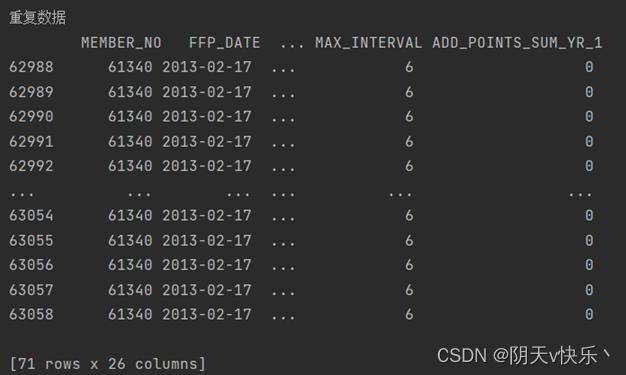
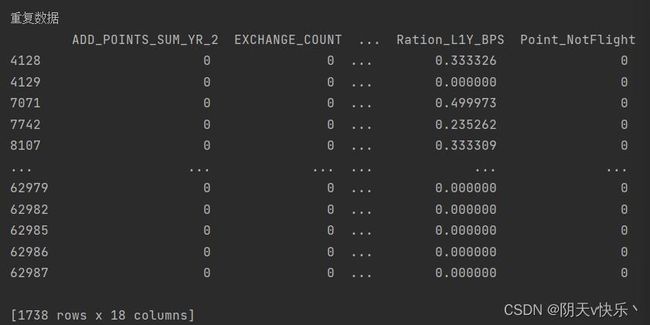
我们对重复数据执行删除操作。
d、缺失行进行分析:
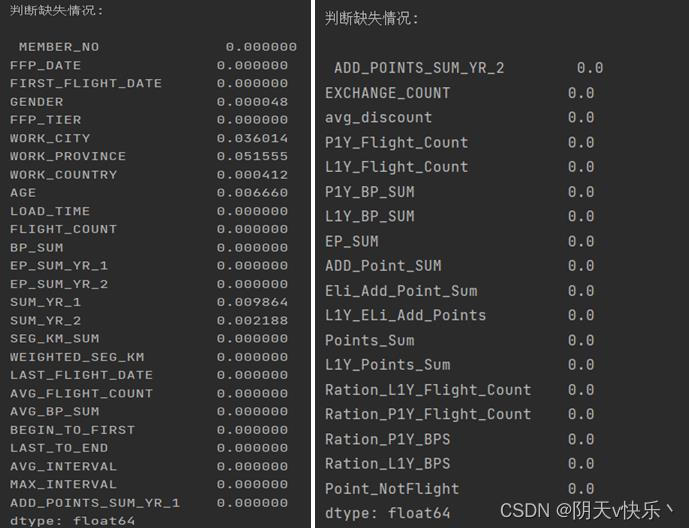
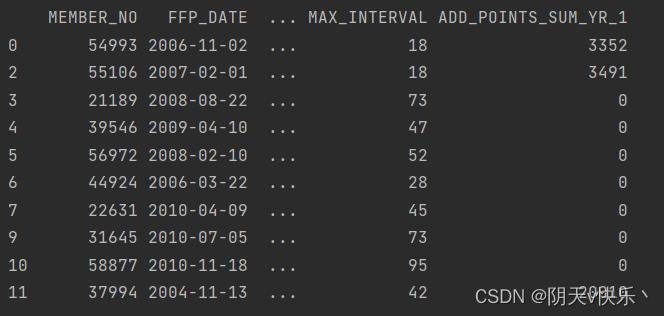
根据观察,表格air_data01存在部分数据缺失,因为数据量较为庞大,所以我们对所有缺失的数据执行行删除操作。
e、重复数据与缺失数据删除前后数据对比:
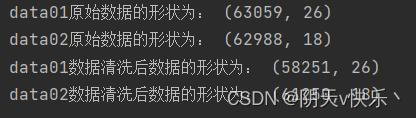
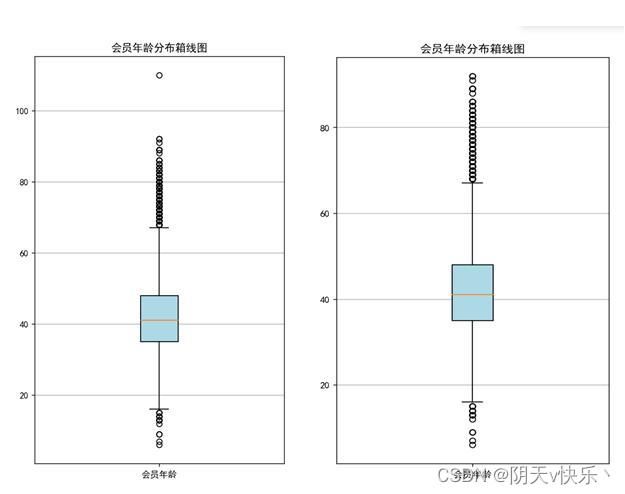
f、异常值清除:
根据会员年龄分布箱型图,可以看出大部分会员年龄集中在30~50岁之间,极少量的会员年龄小于20岁或高于60岁,且存在一个超过100岁的异常数据。我们对该AGE数据中大于100的进行删除,所得结果如下图所示。
2)数据集成
保存数据到‘cleanedfile_finish1.csv’用于后续数据可视化。

3)数据可视化
a、各年份会员入会人数直方图绘制:
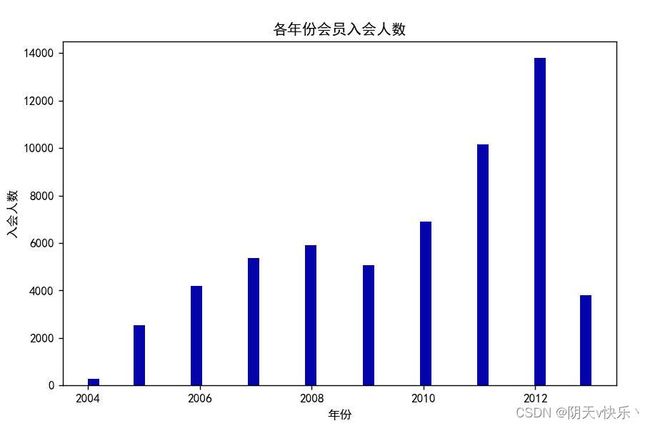
可以发现入会人数大致是随着年份的增加而增加,在2012年达到顶峰。2009年与2013年与趋势不符,有可能是采样的问题,有可能是其他类似政策的问题
b、会员性别比例饼饼图绘制: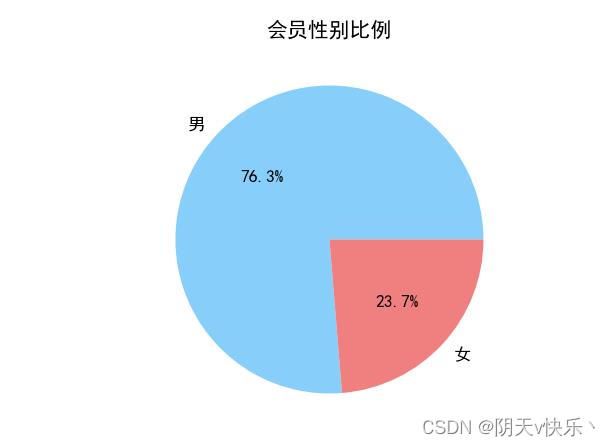
可以发现入会男性比例远远高于女性。
c、会员各级别人数条形图绘制:
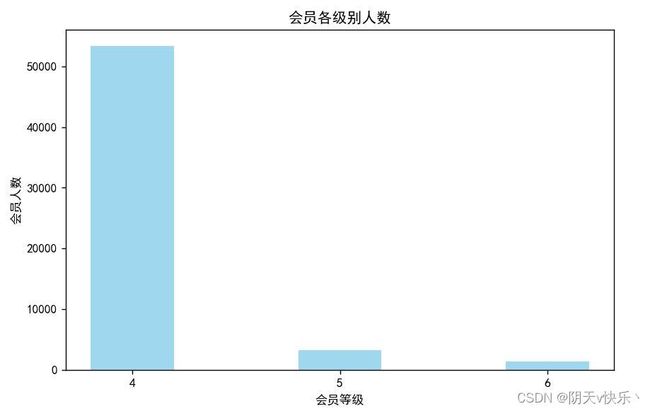
可以看出绝大多数会员为4级会员,仅有少数5级或者6级会员
d、箱型图绘制

由会员年龄分布箱线图可以看出绝大多数年龄位于30~50岁之间
最后一次乘机时间至观测窗口时长越短,表示客户对航空公司越满意。时间间隔越短同时也表示该客户可能是高价值客户。并且还可以从这个属性中看到公司的发展问题,如果时间间隔短的客户越来越少,说明该公司的运营出现了问题,需要及时调整营销策略。
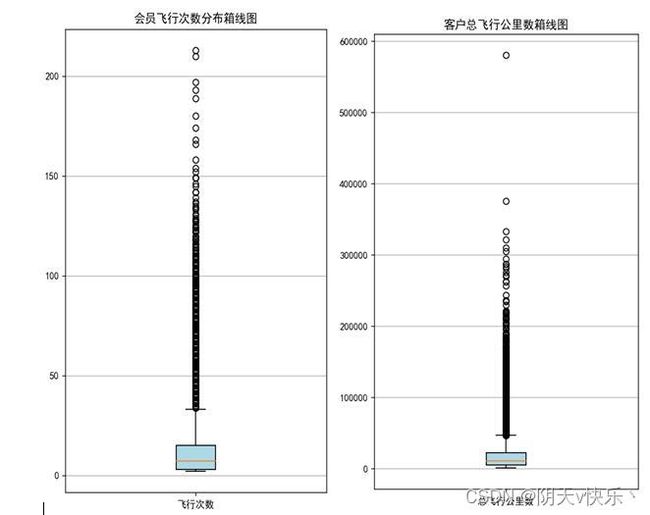
通过图像可以很清晰的发现:客户的飞行次数与总飞行里程数明显分为两个群体,大部分客户集中在箱型图中的箱体中,少数客户位于箱体上方,这部分客户很可能就是高价值客户。
h、会员兑换积分次数直方图绘制:
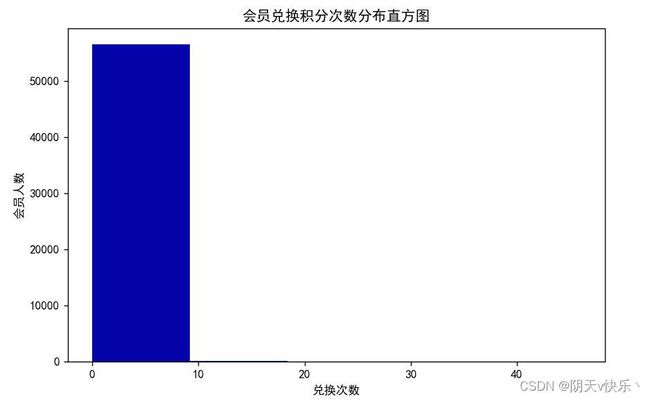
通过图形可以看出:绝大多数兑换次数位于0~10次之间,这表明大部分客户很少进行积分兑换。
i、计算相关矩阵并绘制热力图:

通过热力图可以看出:部分属性之间存在强相关性,比如总飞行公里数与票价收入,总累计积分,飞行次数。可以通过这些关联性强的属性进一步对数据进行挖掘分析。
五、寄语
如您需要实验代码和数据,请点赞关注并私信我,本人无偿提供,仅供学习交流哦~