《深度学习进阶 自然语言处理》第七章:seq2seq介绍
文章目录
-
-
- 7.1 seq2seq模型介绍
-
- 7.1.1 seq2seq的原理
- 7.1.2 时序数据转换简单举例
- 7.2 seq2seq模型实现
- 7.3 seq2seq模型改进
-
- 7.3.1 反转输入数据(Reverse)
- 7.3.2 偷窥(Peeky)
- 7.4 seq2seq模型的应用
- 7.5 总结
-
之前文章链接:
开篇介绍:《深度学习进阶 自然语言处理》书籍介绍
第一章:《深度学习进阶 自然语言处理》第一章:神经网络的复习
第二章:《深度学习进阶 自然语言处理》第二章:自然语言和单词的分布式表示
第三章:《深度学习进阶 自然语言处理》第三章:word2vec
第四章:《深度学习进阶 自然语言处理》第四章:Embedding层和负采样介绍
第五章:《深度学习进阶 自然语言处理》第五章:RNN通俗介绍
第六章:《深度学习进阶 自然语言处理》第六章:LSTM介绍
这个世界充满了时序数据。文本数据、音频数据和视频数据都是时序数据。另外,还存在许多需要将一种时序数据转换为另一种时序数据的任务, 比如机器翻译、语音识别等。其他的还有进行对话的聊天机器人应用、将源代码转为机器语言的编译器等。
像这样,世界上存在许多输入输出均为时序数据的任务。这一章我们会讨论将时序数据转换为其他时序数据的模型,即 seq2seq 。
seq2seq 是 “(from) sequence to sequence”(从时序到时序)的意思,即将一个时序数据转换为另一个时序数据。本章我们将看到,通过组合两个 RNN,可以轻松实现 seq2seq。seq2seq 可以应用于多个方向,比如机器翻译、聊天机器人和邮件自动回复等。
7.1 seq2seq模型介绍
7.1.1 seq2seq的原理
seq2seq 模型也称为 Encoder-Decoder 模型。顾名思义,这个模型有两个模块——Encoder(编码器)和 Decoder(解码器)。编码器对输入数据进行编码,解码器对被编码的数据进行解码。
现在,我们举一个具体的例子来说明 seq2seq 的机制。这里考虑将日语翻译为英语,如下图:

以上就是 seq2seq 的全貌图。编码器和解码器协作,将一个时序数据转换为另一个时序数据。另外,在这些编码器和解码器内部可以使用 RNN。
下面我们来看一下细节。首先来看编码器,它的层结构如下图:

由上图可以看出,编码器利用 RNN 将时序数据转换为隐藏状态 h。这里的RNN使用的是LSTM,不过也可以使用“简单RNN“或者 GRU等。另外,这里考虑的是将日语句子分割为单词进行输入的情况。
上图的编码器输出的向量h是 LSTM 层的最后一个隐藏状态,其中编码了翻译输入文本所需的信息。这里的重点是,LSTM 的隐藏状态 h是一个固定长度的向量。说到底,编码就是将任意长度的文本转换为一个固定长度的向量。
编码器将文本转换为固定长度的向量。那么,解码器是如何“处理〞这个编码好的向量,从而生成目标文本的呢?
解码器的结构如下图所示,LSTM层会接收向量h,然后预测输出内容。

整体把编码器层和解码器层连接到一起,最终结果如下图所示:

上图中,seq2seq 由两个 LSTM层构成,即编码器的 LSTM 和解码器的 LSTM。此时,LSTM层的隐藏状态是编码器和解码器的“桥梁”。在正向传播时,编码器的编码信息通过LSTM 层的隐藏状态传递给解码器;在反向传播时,解码器的梯度通过这个“桥梁”传递给编码器。
7.1.2 时序数据转换简单举例
接下来我们通过一个简单案例进一步理解seq2seq工作的过程。
首先说明一下案例中要处理的问题。我们将“加法”视为一个时序转换问题。具体来说,在 seq2seq 学习后,如果输人字符串 “57+ 5”,seq2seq 要能正确回答“62”。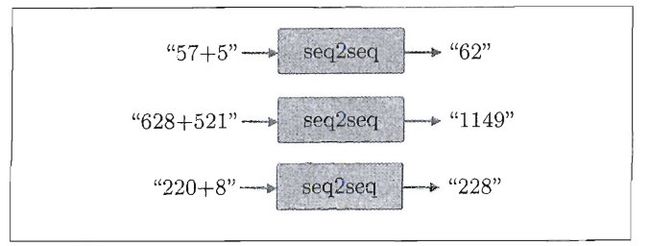
7.2 seq2seq模型实现
seq2seq 是组合了两个 RNN 的神经网络。在模型实现中我们首先将这两个 RNN 实现为 Encoder 类和 Decoder 类,然后将这两个类组合起来,实现为 seq2seq 类。该部分代码将不在此处展示,感兴趣的读者可以去书中P291中查看。
Seq2seq 的学习(训俩)和基础神经网络的学习(训练)具有相同的流程。基础神经网络的学习流程如下:
1、从训练数据中选择一个 mini-batch
2、基于 min-batch 计算梯度
3、使用梯度更新权重
此处最终评价指标为:正确率(正确回答了多少问题)。具体来说,就是针对每个 epoch 对正确回答了测试数据中的多少问题进行统计。
对每个epoch进行统计,随着学习的积累,正确率稳步提高。本次的实验只进行了25次,最后的正确率约为 10%。从下图中的变化趋势可知,如果继续学习,正确率应该还会进一步上升。
 不过,为了能更好地学习相同的问题(加法问题),这里我们暂停本次学习,在下一节中将会对 seq2seq 进行一些改进。
不过,为了能更好地学习相同的问题(加法问题),这里我们暂停本次学习,在下一节中将会对 seq2seq 进行一些改进。
7.3 seq2seq模型改进
本节我们对上一节的 seq2seq 进行改进,以改进学习的进展。为了达成该目标,可以使用一些比较有前景的技术。本节我们展示其中的兩个方案, 并基于实验确认它们的效果。
7.3.1 反转输入数据(Reverse)
第一个改进方案是非常简单的技巧。反转输人数据的顺序,如下图所示:

记录每个epoch训练结果,仅仅通过反转输入数据,学习的进展就得到了改善!在25个 epoch 时,正确率为 50% 左右。再次重复一遍,这里和上一次(图中的 baseline)的差异只是将数据反转了一下。仅仅这样,就产生了这么大的差异。当然,虽然反转数据的效果因任务而异,但是通常都会有好的结果。

为什么反转数据后,学习进展变快,精度提高了呢?虽然理论上不是很清楚,但是直观上可以认为,反转数据后梯度的传播可以更平滑。
7.3.2 偷窥(Peeky)
接下来是 seq2seq 的第二个改进。在进入正题之前,我们再看一下编码器的作用。如前所述,编码器将输入语句转换为固定长度的向量h,这个h 集中了解码器所需的全部信息。也就是说,它是解码器唯一的值息源。但是,如下图所示,当前的 seq2seq 只有最开始时刻的 LSTM层利用了 h。我们能更加充分地利用这个h吗?

为了达成该目标,seq2seq 的第二个改进方案就应运而生了。具体来说, 就是将这个集中了重要信息的编码器的输出h分配给解码器的其他层。我们的解码器可以考虑下图中的网络结构。

加上了 Peeky 的 seq2seq 的结果大幅变好。刚过10个 epoch 时,正确率已经超过90%,最终的正确率接近 100%,实验结果如下图所示:

7.4 seq2seq模型的应用
seq2seq 将某个时序数据转换为另一个时序数据,这个转换时序数据的框架可以应用在各种各样的任务中,比如以下几个例子:
-
机器翻译:将“一种语言的文本”转换为“另一种语言的文本”
-
自动摘要:“一个长文本”转换为“短摘要”
-
问答系统:将“问题“转换为“答案”
-
聊天机器人:将 “对方的发言” 转换为“本方的发言”的过程
-
邮件自动回复:将“接收到的邮件文本〞转换为“回复文本”
-
图像文本生成:把图像转换为文本的自动图像描述
像这样,seq2seq 可以用于处理成对的时序数据的问题。除了自然语言之外,也可以用于语音、视频等数据。有些乍一看不属于 seq2seq 的问题, 通过对输入输出数据进行预处理,也可以应用 seq2seq。
7.5 总结
本节中我们主要介绍了seq2seq模型,其是有编码器和解码器组成。同时还介绍了改进seq2seq的两个方案——Reverse和Peeky.