NLP (四): seq2seq (RNN, Attention), NTM (神经图灵机)
本文为《深度学习进阶: 自然语言处理》的读书笔记
目录
- seq2seq 模型
-
- Encoder-Decoder 模型
- seq2seq 的应用
- RNN based seq2seq
-
- seq2seq
-
- Encoder
- Decoder
- seq2seq (Encoder + Decoder)
- seq2seq 的实现
-
- Encoder 类
- Decoder 类
- Seq2seq 类
- seq2seq 的评价
- 时序数据转换的简单尝试 (toy problem)
-
- 可变长度的时序数据
- 加法数据集
- 在加法数据集上训练 seq2seq 模型
- seq2seq 的改进
-
- 反转输入数据 (Reverse)
- Peeky Decoder
- Attention based seq2seq
-
- RNN based seq2seq 存在的问题
- Encoder: 输出所有时刻的隐藏状态向量
- Decoder
-
- 对齐 (alignment)
- Attention
- 带 Attention 的 seq2seq 的实现
-
- AttentionEncoder
- AttentionDecoder
- AttentionSeq2seq
- Attention 的评价
-
- 日期格式转换问题
- 带 Attention 的 seq2seq 的学习
- Attention 的可视化
- seq2seq 的深层化和 skip connection
- 神经图灵机 (Neural Turing Machine, NTM)
-
- 基于外部存储装置的扩展
- 内存操作
- NTM 的整体框架
seq2seq 模型
- seq2seq 是 “(from) sequence to sequence” (从时序到时序) 的意思,即将一个时序数据转换为另一个时序数据
Encoder-Decoder 模型
- seq2seq 模型也称为 Encoder-Decoder 模型。顾名思义,这个模型有两个模块—— Encoder 和 Decoder。编码器对输入数据进行编码,解码器对被编码的数据进行解码

seq2seq 的应用
- (1) 机器翻译:将 “一种语言的文本” 转换为 “另一种语言的文本”
- (2) 自动摘要:将 “一个长文本” 转换为 “短摘要”
- (3) 问答系统:将 “问题” 转换为 “答案”
- (4) 邮件自动回复:将 “接收到的邮件文本” 转换为 “回复文本”
- (5) 聊天机器人: 将 “对方的发言” 转换为 “本方的发言”
- (6) 语音识别: 将“语音” 转换为 “文本”
- (7) 自动图像描述 (image captioning): 将图像转换为文本。只需将 CNN 作为 Encoder,利用 Affine 层输出隐藏状态给 Decoder,然后 Decoder 利用隐藏状态,使用 RNN 生成文本描述即可

RNN based seq2seq
seq2seq
Encoder

- 由上图可以看出,编码器利用 RNN 将时序数据转换为隐藏状态 h h h,其中编码了翻译输入文本所需的信息。总的来说,Encoder 就是将任意长度的文本转换为一个固定长度的向量
Decoder
- 如何由 Encoder 编码得到的隐藏状态 h h h 生成目标文本呢? – 可以参考语言模型的思路,利用 RNN 接受隐藏状态 h h h,然后逐个单词地生成目标文本 (生成时直接选择概率最大的单词即可)
 其中,
其中, _”(下划线)作为分隔符的例子)
seq2seq (Encoder + Decoder)

- 现在我们知道了 seq2seq 模型的推理过程,也就是对 Encoder 输入一串时序数据,得到隐藏状态 h h h,然后将 h h h 和特殊分隔符
- 那么如何训练这个 seq2seq 模型呢?从 seq2seq 模型的推理过程中我们知道,Decoder 在某一时刻的输出依赖于上一个时刻的输出,而训练时由于 Decoder 权重都是随机初始化的,本来就难以产生好的结果,这使得 Decoder 一开始就很可能产生错误的输出,之后又用错误的输出作为下一个时刻的输入,属于是错上加错,这样的训练效果肯定不好。因此,在训练 seq2seq 模型时,我们直接将标签时序数据作为 Decoder 的输入,再计算由此产生的文本与标签文本的对数损失并进行梯度下降
seq2seq 的实现
Encoder 类

class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
self.embed = TimeEmbedding(embed_W)
# 输入的是短时序数据,需要针对每个问题重设 LSTM 的隐藏状态,因此 stateful 设为 False
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :]
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
Decoder 类

- 由于解码器在学习时和在生成时处理 Softmax 层的方式是不一样的 (学习时需要用到 Softmax with Loss 层,而生成时只需要用到 Affine 层,即取经过全连接层后数值最大的单词作为生成单词即可)。因此,Softmax with Loss 层交给此后实现的 Seq2seq 类处理。Decoder 类仅承担 Time Softmax with Loss 层之前的部分
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, h):
# 在学习时使用
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh # 反向传播 LSTM 第一个时刻的隐藏状态梯度 dh
return dh
def generate(self, h, start_id, sample_size):
# 在生成时使用
sampled = []
sample_id = start_id
self.lstm.set_state(h) # 接受来自 Encoder 的隐藏状态
for _ in range(sample_size):
x = np.array(sample_id).reshape((1, 1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(int(sample_id))
return sampled
Seq2seq 类
class Seq2seq(BaseModel):
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Decoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
seq2seq 的评价
- seq2seq 针对每个 epoch 求解测试数据 (生成字符串),并计算正确率
时序数据转换的简单尝试 (toy problem)
- 下面我们解决一个简单的时序数据转换问题。我们可以将 “加法” 视为一个时序转换问题,输入加法式,输出式子结果。本次的问题处理的是 0 ~ 999 的两个数的加法:
 对于这个问题,我们将不以单词为单位,而是以字符为单位进行分割
对于这个问题,我们将不以单词为单位,而是以字符为单位进行分割
可变长度的时序数据
- 加法问题处理的是可变长度的时序数据,但在使用批数据进行学习时,需要保证一个批次内各个样本的数据形状是一致的
- 最简单的方法是使用填充 (padding),就是用无意义数据填入原始数据,从而使数据长度对齐。由于最多是三位数加法,输入的最大字符数是 7,输出的最大字符数是 4。又因为标签中还需要加上一个分隔符 (这里使用下划线作为分隔符) 来标识解码的开始,因此将输入数据填充为 7 个字符,输出数据填充为 5 个字符:

为了简单起见,这里我们不使用表示字符输出结束的分隔符,而是始终输出固定数量的字符
因为使用了填充,seq2seq 需要处理原本不存在的填充用字符,所以如果追求严谨,使用填充时需要向 seq2seq 添加一些填充专用的处理。比如,在解码器中输入填充时,不应计算其损失(这可以通过向 Softmax with Loss 层添加 mask 功能来解决)。再比如,在编码器中输入填充时,LSTM 层应按原样输出上一时刻的输入。这样一来,LSTM 层就可以像不存在填充一样对输入数据进行编码; 为了简单起见,下面也不考虑这些因素了
加法数据集
- 加法的学习数据预先存放在了
dataset/addition.txt中,含有 50 000 个加法样本。下面是加法数据集的一部分:
16+75 _91
52+607 _659
75+22 _97
63+22 _85
795+3 _798
706+796_1502
8+4 _12
84+317 _401
9+3 _12
6+2 _8
- 书中提供了该数据集的相关接口
load_data和get_vocab:
# coding: utf-8
import sys
sys.path.append('..')
from dataset import sequence
# load_data 读入指定的文本文件,并将文本转换为字符 ID,返回训练数据和测试数据
# 该方法内部设有随机数种子 seed 以打乱数据,分割训练数据和测试数据
(x_train, t_train), (x_test, t_test) = \
sequence.load_data('addition.txt', seed=1984)
# get_vocab() 方法返回字符与 ID 的映射字典
char_to_id, id_to_char = sequence.get_vocab()
print(x_train.shape, t_train.shape)
print(x_test.shape, t_test.shape)
# (45000, 7) (45000, 5)
# (5000, 7) (5000, 5)
print(x_train[0])
print(t_train[0])
# [ 3 0 2 0 0 11 5]
# [ 6 0 11 7 5]
print(''.join([id_to_char[c] for c in x_train[0]]))
print(''.join([id_to_char[c] for c in t_train[0]]))
# 71+118
# _189
在加法数据集上训练 seq2seq 模型
- Seq2seq 的学习和基础神经网络的学习具有相同的流程: (1) 从训练数据中选择一个 mini-batch; (2) 基于 mini-batch 计算梯度; (3) 使用梯度更新权重。因此训练时使用 Trainer 类进行上述操作
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from dataset import sequence
from common.optimizer import Adam
from common.trainer import Trainer
from common.util import eval_seq2seq
from seq2seq import Seq2seq
from peeky_seq2seq import PeekySeq2seq
# 读入数据集
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
char_to_id, id_to_char = sequence.get_vocab()
# Reverse input? =================================================
is_reverse = False # True
if is_reverse:
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
# ================================================================
# 设定超参数
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
# Normal or Peeky? ==============================================
model = Seq2seq(vocab_size, wordvec_size, hidden_size)
# model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size)
# ================================================================
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
# 针对每个 epoch 统计回答测试集中问题的正确率
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1,
batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
# eval_seq2seq 向模型输入问题,生成字符串,并判断它是否与答案相符。如果模型给出的答案正确,则返回 1;如果错误,则返回 0
# verbose 指定是否显示结果; is_reverse 指定是否反转输入语句
correct_num += eval_seq2seq(model, question, correct,
id_to_char, verbose, is_reverse)
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('val acc %.3f%%' % (acc * 100))
# 绘制每个epoch 的正确率
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(0, 1.0)
plt.show()

seq2seq 的改进
反转输入数据 (Reverse)
- paper: Sequence to Sequence Learning with Neural Networks
- 第一个改进方案是非常简单的技巧。如下图所示,反转输入数据的顺序
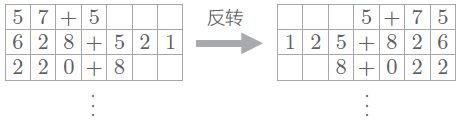 在许多情况下,使用这个技巧后,学习进展得更快,最终的精度也有提高
在许多情况下,使用这个技巧后,学习进展得更快,最终的精度也有提高 - 为什么反转数据后,学习进展变快,精度提高了呢? 虽然理论上不是很清楚,但是直观上可以认为,反转数据后梯度的传播可以更平滑
- 比如,考虑将 “吾輩 は 猫 で ある” 翻译成 “I am a cat” 这一问题,单词 “吾輩” 和单词 “I” 之间有转换关系。此时,从 “吾輩” 到 “I” 的路程必须经过 “は” “猫” “で” “ある” 这 4 个单词的 LSTM 层。因此,在反向传播时,梯度从 “I” 抵达 “吾輩”,也要受到这个距离的影响。而如果反转输入语句,“吾輩” 和 “I” 就变得彼此相邻,梯度可以直接传递。如此,因为通过反转,输入语句的开始部分和对应的转换后的单词之间的距离变近,所以梯度的传播变得更容易,学习效率也更高。不过,在反转输入数据后,单词之间的“平均”距离并不会发生改变
- 我们在读入数据集之后,追加下面的代码:
# 读入数据集
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
...
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
...
- 仅仅通过反转输入数据,正确率就大幅上升:

Peeky Decoder
- paper: Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
- 注意到,当前的 Decoder 只有最开始时刻的 LSTM 层利用了 Encoder 的编码信息 h h h。为了更充分地利用 h h h,可以将 h h h 分配给 Decoder 所有时刻的 Affine 层和 LSTM 层:
 其中, h h h 的输入是通过与原有输入进行 concat 来完成的
其中, h h h 的输入是通过与原有输入进行 concat 来完成的

class PeekyDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
# 与 Decoder 类相比,这里 lstm_Wx 和 affine_W 的形状改变了
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(H + D, 4 * H) / np.sqrt(H + D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H + H, V) / np.sqrt(H + H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
self.cache = None
def forward(self, xs, h):
N, T = xs.shape
N, H = h.shape
self.lstm.set_state(h)
out = self.embed.forward(xs)
hs = np.repeat(h, T, axis=0).reshape(N, T, H) # 根据时序大小复制相应份数的 h
out = np.concatenate((hs, out), axis=2) # 拼接 hs 和 Embedding 层的输出,然后输入 LSTM 层
out = self.lstm.forward(out)
out = np.concatenate((hs, out), axis=2)
score = self.affine.forward(out)
self.cache = H
return score
# backward 和 generate 方法与 Decoder 一样,这里省略
- 使用
PeekyDecoder后,正确率再次大幅提高:

Attention based seq2seq
RNN based seq2seq 存在的问题
- seq2seq 中使用编码器对时序数据进行编码,然后将编码信息传递给解码器。此时,编码器的输出是固定长度的向量,这意味着无论多长的文本,当前的编码器都会将其转换为固定长度的向量
- 下面就针对这个问题,依次对 Encoder 和 Decoder 进行改进
Encoder: 输出所有时刻的隐藏状态向量
- 编码器的输出长度应该根据输入文本的长度相应地改变。为此,与之前只使用最后时刻的隐藏状态不同,我们可以使用各个时刻的隐藏状态向量来获得和输入的单词数相同数量的向量
 各个时刻的隐藏状态中包含了大量当前时刻的输入单词的信息,因此编码器输出的 h s h_s hs 矩阵就可以视为各个单词对应的向量集合
各个时刻的隐藏状态中包含了大量当前时刻的输入单词的信息,因此编码器输出的 h s h_s hs 矩阵就可以视为各个单词对应的向量集合
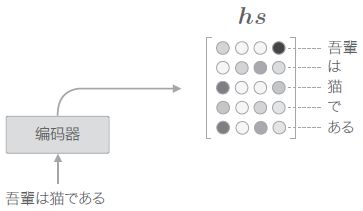
在许多深度学习框架中,在初始化 RNN / LSTM / GRU 层时,可以选择是返回 “全部时刻的隐藏状态向量”,还是返回 “最后时刻的隐藏状态向量”。比如,在 Keras 中,在初始化 RNN 层时,可以设置
return_sequences为 True 或者 False
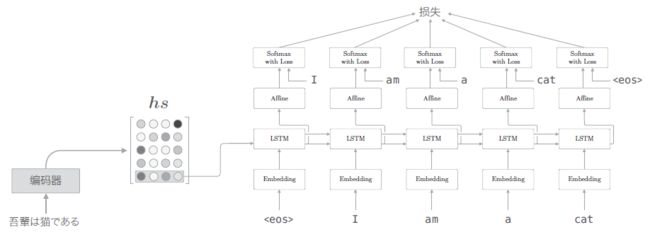
Decoder
- 我们改进解码器,以便能够充分利用编码信息 h s h_s hs (之前的 Decoder 只使用最后时刻的隐藏状态,相当于只利用了 h s h_s hs 的最后一行)
对齐 (alignment)
- 在机器翻译的历史中,很多研究都利用 “猫 = cat” 这样的单词对应关系的知识。这样的表示单词 / 词组对应关系的信息称为对齐。那么我们可以让模型自动学得对齐信息吗?也就是让 seq2seq 模型在输出某个单词时,学会重点关注输入的某个单词或单词集合。例如在翻译 “吾輩は猫である” 并输出第一个单词 “I” 时,我们希望 seq2seq 模型能重点关注单词 “吾輩”
- 从现在开始,我们的目标是找出与 “翻译目标词” 有对应关系的 “翻译源词” 的信息,然后利用这个信息进行翻译。也就是说,我们的目标是仅关注必要的信息,并根据该信息进行时序转换。这个机制称为 Attention
Attention

Weight Sum 层
- 如上图所示,我们在原有基础上新增一个用于提取单词对齐信息的层。具体来说,就是从 h s h_s hs 中选出与各个时刻解码器输出的单词有对应关系的单词向量。但从一个集合中选择若干个的操作是不可微的,为此,我们干脆用一个权重向量 a a a 来表示各个单词重要度,有了权重向量之后,对 h s h_s hs 中包含的 T T T 个时刻的隐藏状态进行加权求和即可得到上下文向量 c c c:

计算加权和最简单有效的方法是使用矩阵乘积。如果批大小为 1,只需要
np.dot(a, hs)就可以获得上下文向量。如果进行批处理,就需要用到 “张量积”,使用np.tensordot()和np.einsum()方法。下面代码中利用广播实现加权求和,对应的计算图如下:

class WeightSum:
def __init__(self):
# 这个层没有要学习的参数,self.params = []
self.params, self.grads = [], []
self.cache = None
def forward(self, hs, a):
N, T, H = hs.shape
ar = a.reshape(N, T, 1)#.repeat(T, axis=1)
t = hs * ar
c = np.sum(t, axis=1)
self.cache = (hs, ar)
return c # shape: N x H
def backward(self, dc):
hs, ar = self.cache
N, T, H = hs.shape
dt = dc.reshape(N, 1, H).repeat(T, axis=1) # Sum 节点的反向传播为 Repeat
dar = dt * hs
dhs = dt * ar
da = np.sum(dar, axis=2) # Repeat 节点的反向传播为 Sum
return dhs, da
Attention Weight 层
- 现在的问题是,权重向量 a a a 应该怎么计算得到呢? 如下图所示,我们用 h h h 表示解码器的 LSTM 层的隐藏状态向量。此时,我们的目标是用数值表示这个 h h h 在多大程度上和 h s h_s hs 的各个单词向量 “相似”。这里我们使用最简单的向量内积 (除了内积之外,还有使用小型的神经网络输出得分的做法。Effective Approaches to Attention-based Neural Machine Translation 中提出了几种输出得分的方法)
 对应的计算图如下:
对应的计算图如下:
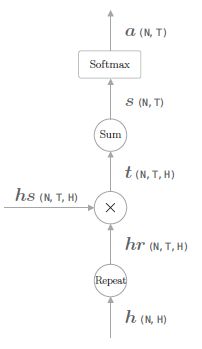
class AttentionWeight:
def __init__(self):
self.params, self.grads = [], []
self.softmax = Softmax()
self.cache = None
def forward(self, hs, h):
N, T, H = hs.shape
hr = h.reshape(N, 1, H)#.repeat(T, axis=1)
t = hs * hr
s = np.sum(t, axis=2)
a = self.softmax.forward(s)
self.cache = (hs, hr)
return a
def backward(self, da):
hs, hr = self.cache
N, T, H = hs.shape
ds = self.softmax.backward(da)
dt = ds.reshape(N, T, 1).repeat(H, axis=2)
dhs = dt * hr
dhr = dt * hs
dh = np.sum(dhr, axis=1)
return dhs, dh
Attention 层
- 下面我们将 Weight Sum 层和 Attention Weight 层组合起来形成 Attention 层,用于计算上下文向量:

class Attention:
def __init__(self):
self.params, self.grads = [], []
self.attention_weight_layer = AttentionWeight()
self.weight_sum_layer = WeightSum()
self.attention_weight = None
def forward(self, hs, h):
a = self.attention_weight_layer.forward(hs, h)
out = self.weight_sum_layer.forward(hs, a)
self.attention_weight = a # 保存权重向量,便于可视化
return out
def backward(self, dout):
dhs0, da = self.weight_sum_layer.backward(dout)
dhs1, dh = self.attention_weight_layer.backward(da)
dhs = dhs0 + dhs1
return dhs, dh
Decoder with Attention

- 注意到,这里 上下文向量和隐藏状态向量被拼接起来输入 Affine 层
实际上也可以将上下文向量用在 LSTM 层,由于 Attention 层的数据是从左往右流动的,因此这种方法实现起来要稍微复杂一些 (paper: Neural Machine Translation by Jointly Learning to Align and Translate):
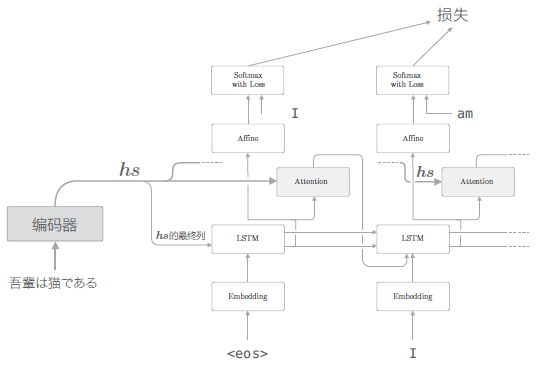
Time Attention 层
- 最后,我们将时序方向上扩展的多个 Attention 层整体实现为 Time Attention 层

class TimeAttention:
def __init__(self):
self.params, self.grads = [], []
self.layers = None
self.attention_weights = None
def forward(self, hs_enc, hs_dec):
N, T, H = hs_dec.shape
out = np.empty_like(hs_dec)
self.layers = []
self.attention_weights = []
for t in range(T):
layer = Attention()
out[:, t, :] = layer.forward(hs_enc, hs_dec[:,t,:])
self.layers.append(layer)
self.attention_weights.append(layer.attention_weight)
return out
def backward(self, dout):
N, T, H = dout.shape
dhs_enc = 0
dhs_dec = np.empty_like(dout)
for t in range(T):
layer = self.layers[t]
dhs, dh = layer.backward(dout[:, t, :])
dhs_enc += dhs
dhs_dec[:,t,:] = dh
return dhs_enc, dhs_dec
带 Attention 的 seq2seq 的实现
AttentionEncoder
- 这个类和 Encoder 类几乎一样,唯一的区别是,Encoder 类的
forward()方法仅返回 LSTM 层的最后的隐藏状态向量,而 AttentionEncoder 类则返回所有的隐藏状态向量
class AttentionEncoder(Encoder):
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
return hs
def backward(self, dhs):
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
AttentionDecoder

- 和 Decoder 类一样,Time Softmax with Loss 层之前的层都作为解码器。实现除使用了新的 Time Attention 层之外,和 Decoder 类没有什么太大的不同
class AttentionDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(2*H, V) / np.sqrt(2*H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
# 加上了 TimeAttention 层
self.attention = TimeAttention()
self.affine = TimeAffine(affine_W, affine_b)
layers = [self.embed, self.lstm, self.attention, self.affine]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, enc_hs):
h = enc_hs[:,-1]
self.lstm.set_state(h)
out = self.embed.forward(xs)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
# 拼接了上下文向量和隐藏状态向量
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
N, T, H2 = dout.shape
H = H2 // 2
dc, ddec_hs0 = dout[:,:,:H], dout[:,:,H:]
denc_hs, ddec_hs1 = self.attention.backward(dc)
ddec_hs = ddec_hs0 + ddec_hs1
dout = self.lstm.backward(ddec_hs)
dh = self.lstm.dh
denc_hs[:, -1] += dh
self.embed.backward(dout)
return denc_hs
def generate(self, enc_hs, start_id, sample_size):
sampled = []
sample_id = start_id
h = enc_hs[:, -1]
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array([sample_id]).reshape((1, 1))
out = self.embed.forward(x)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(sample_id)
return sampled
AttentionSeq2seq
- AttentionSeq2seq 类的实现也和上一章实现的 seq2seq 几乎一样,区别仅在于编码器使用 AttentionEncoder类,解码器使用 AttentionDecoder 类
class AttentionSeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
args = vocab_size, wordvec_size, hidden_size
self.encoder = AttentionEncoder(*args)
self.decoder = AttentionDecoder(*args)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
Attention 的评价
- WMT 是一个有名的翻译数据集。这个数据集中提供了英语和法语(或者英语和德语)的平行学习数据。WMT 数据集在许多研究中都被作为基准使用,经常用于评价 seq2seq 的性能,不过它的数据量很大(超过 20 GB),使用起来不是很方便
- 因此这里我们就不用翻译问题作评估,转而用日期格式转换问题作评估。该问题并不像看上去那么简单。因为输入的日期数据存在各种各样的版本,所以转换规则也相应地复杂。如果尝试将这些转换规则全部写出来,那将非常费力。其次,该问题的输入(问句)和输出(回答)存在明显的对应关系。具体而言,存在年月日的对应关系。因此,我们可以确认 Attention 有没有正确地关注各自的对应元素
日期格式转换问题
日期格式转换数据集
september 27, 1994 _1994-09-27
August 19, 2003 _2003-08-19
2/10/93 _1993-02-10
10/31/90 _1990-10-31
TUESDAY, SEPTEMBER 25, 1984 _1984-09-25
JUN 17, 2013 _2013-06-17
april 3, 1996 _1996-04-03
October 24, 1974 _1974-10-24
AUGUST 11, 1986 _1986-08-11
February 16, 2015 _2015-02-16
October 12, 1988 _1988-10-12
6/3/73 _1973-06-03
... (包含 50 000 个日期转换用的学习数据)
带 Attention 的 seq2seq 的学习
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
from dataset import sequence
from common.optimizer import Adam
from common.trainer import Trainer
from common.util import eval_seq2seq
from attention_seq2seq import AttentionSeq2seq
from ch07.seq2seq import Seq2seq
from ch07.peeky_seq2seq import PeekySeq2seq
# 读入数据
(x_train, t_train), (x_test, t_test) = sequence.load_data('date.txt')
char_to_id, id_to_char = sequence.get_vocab()
# 反转输入语句
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
# 设定超参数
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 256
batch_size = 128
max_epoch = 10
max_grad = 5.0
model = AttentionSeq2seq(vocab_size, wordvec_size, hidden_size)
# model = Seq2seq(vocab_size, wordvec_size, hidden_size)
# model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1,
batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
correct_num += eval_seq2seq(model, question, correct,
id_to_char, verbose, is_reverse=True)
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('val acc %.3f%%' % (acc * 100))
model.save_params()
# 绘制精度曲线
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(-0.05, 1.05)
plt.show()


Attention 的可视化
- 接下来,我们对 Attention 进行可视化。在进行时序转换时,实际观察Attention 在注意哪个元素。因为在 Attention 层中,各个时刻的 Attention 权重均保存到了 Time Attention 层中的成员变量
attention_weights中,所以我们可以轻松地进行可视化
- 下图是 seq2seq 进行时序转换时的 Attention 权重的可视化结果,可以看到,输出 (纵轴) 与输入 (横轴) 的年月日基本都是对应的。例如,我们可以看到,当 seq2seq 输出第 1 个 “1” 时,注意力集中在输入语句的 “1” 上。另外,输入语句的 “AUGUST” 对应于表示月份的 “08”,这一点也很令人惊讶。这表明 seq2seq 从数据中学习到了年月日的对应关系

seq2seq 的深层化和 skip connection
加深层
- 在诸如翻译这样的实际应用中,需要解决的问题更加复杂。在这种情况下,我们希望带 Attention 的 seq2seq 具有更强的表现力。此时,首先可以考虑到的是加深 RNN 层 (LSTM 层) (编码器和解码器中通常使用层数相同的 LSTM 层)
- 另外,Attention 层的使用方法有许多变体。这里将解码器 LSTM 层的隐藏状态输入 Attention层,然后将上下文向量(Attention 层的输出)传给解码器的多个层(LSTM 层和 Affine 层)
 (也可以使用多个 Attention 层,或者将 Attention 的输出输入给下一个时刻的 LSTM 层等)
(也可以使用多个 Attention 层,或者将 Attention 的输出输入给下一个时刻的 LSTM 层等)
防止过拟合
- 在加深层时,避免泛化性能的下降非常重要。此时,Dropout、权重共享等技术可以发挥作用
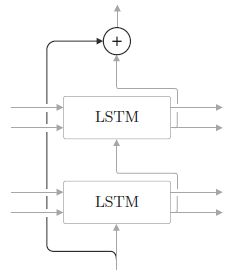
残差连接 (skip connection)
- 在加深层时使用到的另一个重要技巧是残差连接来缓解梯度消失或梯度爆炸
神经图灵机 (Neural Turing Machine, NTM)
paper
- Neural Turing Machines (NTM). 2014
- Hybrid computing using a neural network with dynamic external memory (Differentiable Neural Computers, DNC). 2016 Nature
基于外部存储装置的扩展
- RNN 和 LSTM 能够使用内部状态来存储时序数据,但是它们的内部状态长度固定,能塞入其中的信息量有限。因此,可以考虑在 RNN 的外部配置存储装置 (内存),适当地记录必要信息
内存操作
- 在带 Attention 的 seq2seq 中,编码器对输入语句进行编码。然后,解码器通过 Attention 使用被编码的信息。基于 Attention,编码器和解码器实现了计算机中的 “内存操作” (可以将所有时刻地隐藏状态向量组成的矩阵看作内存,Encoder 输出隐藏状态向量就相当于写内存,Decoder 通过 Attention 机制选择隐藏状态向量进行加权,也就是选择一些内存地址进行读操作)
- 可见计算机的内存操作可以通过神经网络复现。我们可以立刻想到一个方法:在 RNN 的外部配置一个存储信息的存储装置,并使用 Attention 向这个存储装置读写必要的信息。实际上,这样的研究有好几个,神经图灵机 (NTM) 就是其中比较有名的一个
NTM 的整体框架

- 现在我们看一下图 8-40。这里需要注意的是图中间的一个被称为 “控制器” 的模块。这是处理信息的模块,我们假定它使用神经网络。从图中可以看出,数据 “0” 和 “1” 一个接一个地流入这个控制器,控制器对其进行处理并输出新的数据。这里重要的是,在这个控制器的外侧有一张 “大纸”(内存)。基于这个内存,控制器获得了计算机(图灵机)的能力。具体来说,这个能力是指,在这张 “大纸” 上写入必要的信息、擦除不必要的信息,以及读取必要信息的能力。像这样,NTM 在读写外部存储装置的同时处理时序数据。NTM 的有趣之处在于使用 “可微分” 的计算构建了这些内存操作 (所谓可微分的内存操作其实就是利用 Attention 进行内存地址选择)。因此,它可以从数据中学习内存操作的顺序
计算机根据人编写的程序进行动作。与此相对,NTM从数据中学习程序。也就是说,这意味着它可以从“算法的输入和输出” 中学习 “算法自身”(逻辑)

- 图 8-41 是简化版的 NTM 的层结构。这里 LSTM 层是控制器,执行 NTM 的主要处理。Write Head 层接收 LSTM 层各个时刻的隐藏状态,将必要的信息写入内存。Read Head 层从内存中读取重要信息,并传递给下一个时刻的 LSTM 层。其中 Write Head 层和 Read Head 层都是利用 Attention 来进行内存操作
- 为了模仿计算机的内存操作,NTM 的内存操作使用了两个 Attention,分别是 “基于内容的 Attention” 和 “基于位置的 Attention”
- 基于内容的 Attention 和之前介绍的 Attention 一样,用于从内存中找到某个向量(查询向量)的相似向量
- 基于位置的 Attention 用于从上一个时刻关注的内存地址(内存的各个位置的权重)前后移动。这里我们省略对其技术细节的探讨,具体可以通过一维卷积运算实现。基于内存位置的移动功能,可以再现 “一边前进(一个内存地址)一边读取” 这种计算机特有的活动
NTM的内存操作比较复杂。除了上面说到的操作以外,还包括锐化 Attention 权重的处理、加上上一个时刻的 Attention 权重的处理等
- 通过自由地使用外部存储装置,NTM 获得了强大的能力。实际上,对于 seq2seq 无法解决的复杂问题,NTM 取得了惊人的成绩。具体而言, NTM 成功解决了长时序的记忆问题、排序问题(从大到小排列数字)等