论文阅读笔记Coordinate Attention for Efficient Mobile Network Design(CVPR2021)
来源:投稿 作者:kenny_vincent 编辑:学姐
论文阅读笔记
Coordinate Attention for Efficient Mobile Network Design(CVPR2021)
动机&解决的问题
开始读论文的时候⼀定明确所读的论文要解决的是⼀个什么问题,这样才能在读论文的时候保持思路清晰,也为自己以后写论文打下良好的思维习惯。
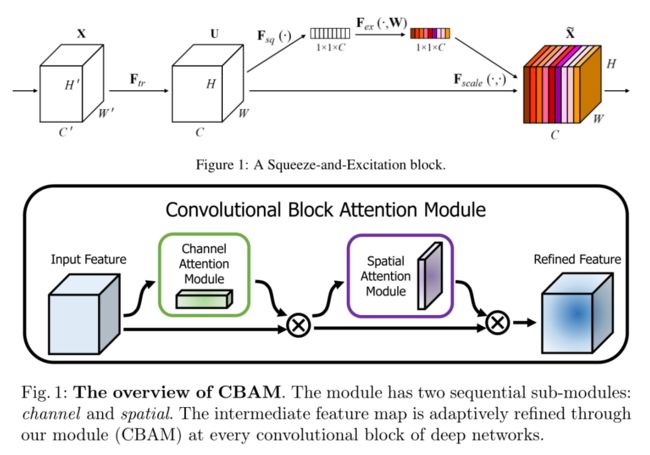
该篇论文主要针对的是注意⼒机制中“通道注意⼒”的问题。作者认为之前优秀的注意力模块如SE(Squeeze-and-Excitation attention)和CBAM(Convolutional block attention module)在对通道间关系进行建模时虽然取得了不错的效果,但是却丢失了空间上的位置信息。而其他没有这个问题的注意力模块虽然效果也不错,但是参数量又太大了,不适合应用于移动端设备的网络。所以作者希望能有⼀个注意⼒模块既能在构建通道注意⼒时捕捉到准确的位置,⼜能像SE和CBAM⼀样轻型⾼效,也就提出这个“坐标注意⼒”。
整体框架
该论文方法主要对标的就是上面所提到的SE和CBAM,同时这三者⼜非常相似,所以作者直接放出了这三个注意⼒的框架图进⾏比较。
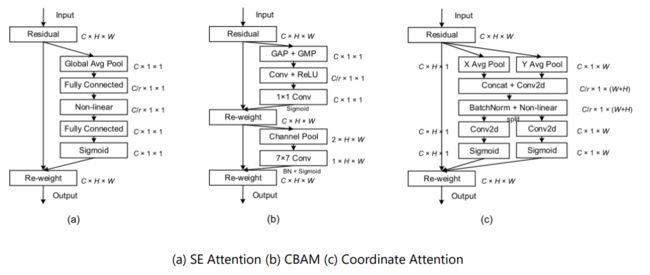
可以看到这三个注意力在整体架构很相近,都采用分支网络计算注意权重。
但是呢,SE是直接进行了⼀个全局平均池化获得了⼀个Cx1x1维的向量,然后在这个向量上计算通道注意力权重,这就相当于在直接把空间信息压缩成1维的了,也就像这篇论文所说的那样直接丢失了位置信息。
CBAM(上半部分计算通道注意⼒,下半部分计算空间注意力)尽管比SE好⼀些,刚开始的时候分成两部分——分别进行了全局最⼤池化和全局平均池化,但是在后面是将这两者加起来然后⽤⼀层卷积来计算注意力权重(后面的1x1卷积是用来升维的),这就导致了它只能够学习到局部关系,但难以学习到⻓距离的依赖关系(long-range dependencies), 然而这个长距离的依赖关系却对其他下游的视觉任务很重要。
ong-range dependencies: 简单来说,就是图像中两个相距较远的像素之间的相关性。
如果忘记了SE和CBAM具体长啥样,可以看看下图,但是建议还是回顾⼀下原论文。
论文:Coordinate Attention for Efficient Mobile Network Design(CVPR2021) 官⽅代码:https://github.com/Andrew-Qibin/CoordAttention
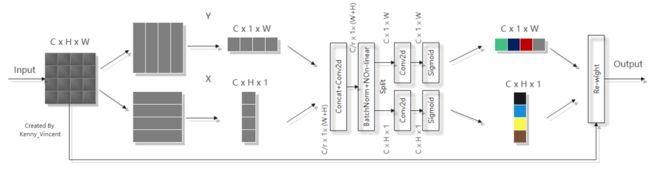
那么坐标注意⼒是怎么做的呢?
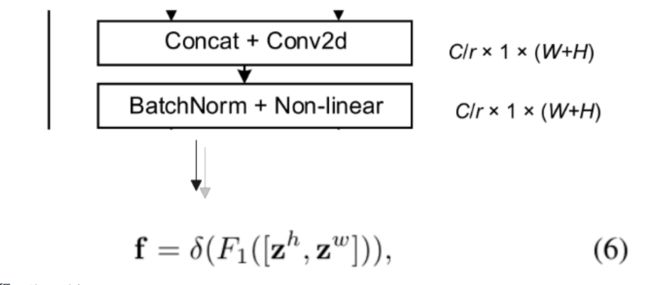
⼀开始也进行了全局池化,但是是分了两个方向进⾏的——水平(X)方向和垂直(Y)方向,这就为通道注意⼒保留这两个方向的长距离依赖关系;然后拼接起来进行卷积,这⼀步则是对两个方向上的信息进行交互;BN+非线性激活函数之后,再对这个特征图分割开来分别进行卷积,也就是在水平和垂直方向同时对它关注,最后进入Sigmoid函数;最后得到的这个这个两个注意力图就能够很好的反映出我们感兴趣的对象是否存在于相应的行和列中,使得我们能够准确地定位出目标对象地位置,解决了上面论文所提到的问题。
坐标注意力直观的计算过程如下图:
公式
⽽且这篇论文的公式也超简单,在论文所以给出的框架图中都可以⼀⼀找到对应:
1. 沿着水平和垂直方向计算1维平均池化
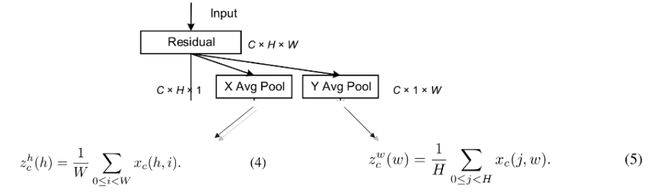
2. 拼接、卷积、BN、激活函数
3. 分别卷积、Sigmoid
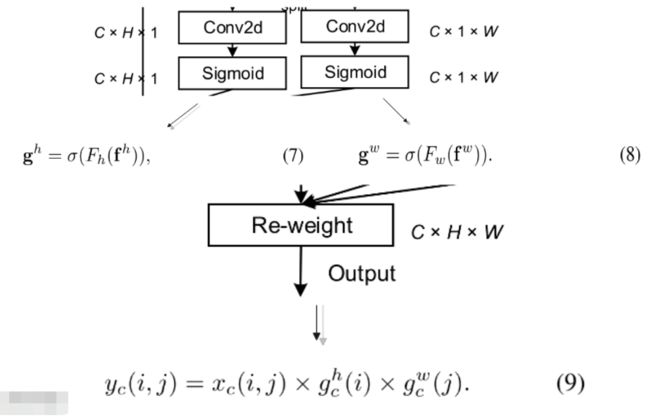
4. 最后输出
实验
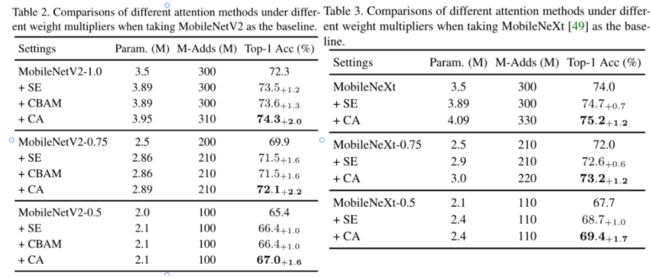
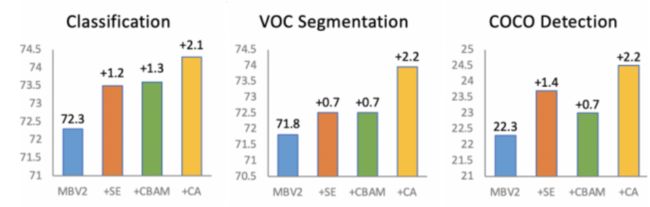
1. 下⾯这两张表是在分别以MobileNetV2,MobileNeXtV2为backbone下,采用不同权重乘数与SE、CBAM的性能比较,可以发现无论是哪个backbone哪个权重乘数,坐标注意力在分类任务上都有明显提高,并且它的参数增加的不多。
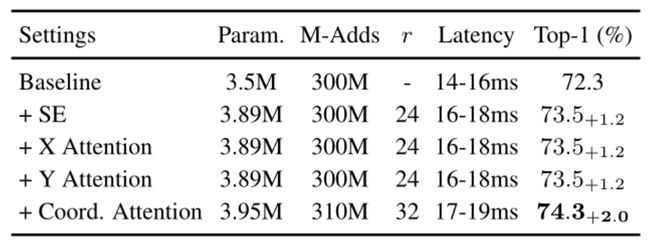
2. 下表则是消融实验,可以发现加入坐标注意力后比没加之前性能确实提高了。
3. 从下表中可以发现,坐标注意力在不同视觉任务下,性能都有所提高
Talk is cheap, Show me the code
这个注意力模块不仅仅看上去很简单,实现起来也很简单!
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out怎么样,加起来不到40行,而且每⼀步都清晰!但是还是推荐到官方github上面去看,毕竟作者在上⾯也做了不少实验,可以学习的也不少。
总结
一个实现简单,效果显著,轻量级,即插即用,可扩展性强的注意力模块。
— 完 —
点这里关注我,记得标星哦~