零基础讲解PCA降维算法原理推导
降维是一种对特征进行压缩的过程,能将特征中的重复冗余特征删除,保留少数最有效的特征。本文从0开始讲解PCA线性降维的推导过程。
注:虽说是零基础,但完整推导必备知识点有拉格朗日乘子法,简单的矩阵求导,矩阵特征分解,若不会也没关系,知道大概怎么一回事就行。
PCA降维的直观理解
原始数据为 X = ( x 1 , x 2 , ⋯ , x n ) ∈ R D × N X=(x_1,x_2,\cdots,x_n)\in \mathbb{R}^{D \times N} X=(x1,x2,⋯,xn)∈RD×N, D D D是样本的维度, N N N是样本的数量。
我们目的是通过PCA降低样本维度,得到新的低维数据点 X = ( z 1 , z 2 , ⋯ , z N ) ∈ R D ′ × N X=(z_1,z_2,\cdots,z_N)\in \mathbb{R}^{D'\times N} X=(z1,z2,⋯,zN)∈RD′×N,其中 D ′ ≪ D D'\ll D D′≪D。
PCA算法的直观解释:
- 通过PCA算法,可以得到1个新的坐标系,包含 D ′ D' D′个标准正交(单位且正交)的坐标轴 W = ( w 1 , w 2 , ⋯ , w D ′ ) W=(w_1,w_2,\cdots,w_{D'}) W=(w1,w2,⋯,wD′)
- 将原始数据映射到新的坐标系 W W W中,那么每个数据的维度都是 D ′ D' D′了
因此PCA算法的关键问题就是如何寻找一个新的坐标轴,能保证映射后的数据与原始数据尽量的接近,尽量少的丢失信息,而且尽量要把维度降低下来。
当然,少丢失信息和维度降低肯定不能两全,维度越低丢失的信息就一定会更多,维度越高丢失的信息就越少,因此需要在这二者中进行一个权衡。
下面就开始推导如何得到这个新的坐标轴 W W W。
目标函数:最小化重建误差
任何机器学习算法都有损失函数,PCA也有一个损失函数,这个损失函数描述了降维后的数据还原回降维前的数据时,与降维前数据之间的误差,因此也叫重建误差。
之前我们说了,我们目标是求一个标准正交的坐标轴 W W W,那么就有 w i T w j = 0 ( i ≠ j ) w_i^Tw_j=0(i\neq j) wiTwj=0(i=j), w i T w i = 1 ( 或 ∣ ∣ w i ∣ ∣ = 1 ) w_i^Tw_i=1(或||w_i||=1) wiTwi=1(或∣∣wi∣∣=1)。
那么PCA编码(降维)的过程就是将原始数据映射到这个新的坐标轴中,第 i i i个低维数据 z i z_i zi的计算公式为 z i = W T x i z_i=W^Tx_i zi=WTxi,其中的第 j j j个分量为 z i , j = W j T x i z_{i,j}=W_j^Tx_i zi,j=WjTxi,新坐标系中每个坐标轴可以得到低维数据的一个分量, D ′ D' D′个坐标轴得到 D ′ D' D′个分量。可以参考同济线代课本关于这部分的知识:

解码过程就是把上述过程反过来,通过低维数据坐标以及坐标轴,得到原始的数据。由于坐标轴 W W W是标准正交的,因此 W − 1 = W T W^{-1}=W^T W−1=WT,很容易得到重建数据为 x ^ i = ∑ i = 1 D ′ z i , j w i = W z i \hat{x}_i=\sum_{i=1}^{D'}z_{i,j}w_i=Wz_i x^i=∑i=1D′zi,jwi=Wzi(也可以根据上图中的公式直接得到)。
那么我们的目标就是将重建误差最小化:
min W ∈ R D × D ′ ∑ i = 1 N ∥ x i − W z i ∥ 2 2 \min _{W \in \mathbb{R}^{D \times D^{\prime}}} \sum_{i=1}^N\left\|x_i-W z_i\right\|^2_2 W∈RD×D′mini=1∑N∥xi−Wzi∥22
∣ ∣ a − b ∣ ∣ 2 2 ||a-b||_2^2 ∣∣a−b∣∣22表示L2距离的平方,待求的参数是坐标轴 W W W。
将上述公式继续化简:
∑ i = 1 N ∥ x i − W z i ∥ 2 = ∑ i = 1 N ( x i − W z i ) T ( x i − W z i ) = ∑ i = 1 N ( x i T x i − x i T ( W z i ) − ( W z i ) T x i + z i T W T W z i ) = ∑ i = 1 N ( z i T z i − 2 z i T W T x i + c o n s t ) = − ∑ i = 1 N z i T z i + c o n s t \begin{aligned} \sum_{i=1}^N\left\|x_i-W z_i\right\|^2&=\sum_{i=1}^N(x_i-Wz_i)^T(x_i-Wz_i)\\ &=\sum_{i=1}^N(x_i^Tx_i-x_i^T(Wz_i)-(Wz_i)^Tx_i+z_i^TW^TWz_i)\\ &=\sum_{i=1}^N(z_i^Tz_i-2z_i^TW^Tx_i+const)\\ &=-\sum_{i=1}^Nz_i^Tz_i+const \end{aligned} i=1∑N∥xi−Wzi∥2=i=1∑N(xi−Wzi)T(xi−Wzi)=i=1∑N(xiTxi−xiT(Wzi)−(Wzi)Txi+ziTWTWzi)=i=1∑N(ziTzi−2ziTWTxi+const)=−i=1∑NziTzi+const
解释一下上述公式, ∥ x i − W z i ∥ 2 \left\|x_i-W z_i\right\|^2 ∥xi−Wzi∥2是向量的模长的平方,也就是每个元素平方的乘积,第一步就是转化成向量的形式,第二步先把转置放进去,然后乘法分配律乘开来,第三步中用到了 W T W = E W^TW=E WTW=E,且 x i T ( W z i ) x_i^T(Wz_i) xiT(Wzi)是个常数,转置也是常数,所以合并起来就是2,然后 x i T x i x_i^Tx_i xiTxi是个与优化目标无关的常数,因此不用管。最后一步用到了 z i = W T x i z_i=W^Tx_i zi=WTxi。
经过上述步骤化简,我们得到了最终的优化目标:
− ∑ i = 1 N z i T z i -\sum_{i=1}^Nz_i^Tz_i −i=1∑NziTzi
我们要让上述值最小,也就是让下式最大:
∑ i = 1 N z i T z i \sum_{i=1}^Nz_i^Tz_i i=1∑NziTzi
z i T z i z_i^Tz_i ziTzi是降维后第 i i i个数据的方差(假定样本已经中心化了),那么对PCA可以进一步直观的理解为:
- 寻找一个新的坐标轴,让原始数据投影到这个新的坐标轴后,数据(第一个维度)的方差最大
- 如果能找到,继续寻找下一个与之前坐标轴正交的坐标轴,同时也要使数据(第二个维度)的方差最大(因为每个坐标轴是不相关的,除了相互正交,各自不影响)
- 如果能找到一些这样的坐标轴(方向向量),我们就称它们为主成分,通过这些主成分我们能精确的描述原始数据

目标函数的计算
我们目前要求解的是一个最优的 W W W:
max W ∑ i = 1 N z i T z i = max W t r ( Z Z T ) = max W t r ( W T X X T W ) \max_W\sum_{i=1}^Nz_i^Tz_i=\max_W tr(ZZ^T)=\max_Wtr(W^TXX^TW) Wmaxi=1∑NziTzi=Wmaxtr(ZZT)=Wmaxtr(WTXXTW)
t r ( X ) tr(X) tr(X)表示矩阵 X X X的迹,也就是对角线元素求和,可以拿笔画一画,二者是一致的。再另 S = X X T S=XX^T S=XXT,上式转化为:
max W t r ( W T S W ) \max_Wtr(W^TSW) Wmaxtr(WTSW)
寻找一个 W ∈ R D × D ′ W\in\mathbb{R}^{D\times D'} W∈RD×D′,使得上式成立,不过要注意,还有一个约束条件: s . t . W T W = I s.t.W^TW=I s.t.WTW=I,矩阵 W W W是坐标系,要求单位且正交。
带约束的优化问题,使用拉格朗日乘子法。
由于目标函数是求迹的最大值,对角线元素的最大值,我们可以分解为对每个对角线元素求最大值,因为每个对角线上的每个元素只与一个 w w w有关,而各个 w w w除了正交都是不相关的,因此可以单独考虑。
坐标系中的第一个方向向量 w 1 w_1 w1,目标函数为 J = t r ( w 1 T S w 1 ) = w 1 S w 1 J=tr(w_1^TSw_1)=w_1Sw_1 J=tr(w1TSw1)=w1Sw1,约束为 w 1 T w 1 = 1 w_1^Tw_1=1 w1Tw1=1,引入拉格朗日函数
- L = w 1 T S w 1 − λ 1 ( w 1 T w 1 − 1 ) L=\boldsymbol{w}_1^T \boldsymbol{S} \boldsymbol{w}_1-\lambda_1\left(\boldsymbol{w}_1^T \boldsymbol{w}_1-1\right) L=w1TSw1−λ1(w1Tw1−1)
- ∂ L ∂ w 1 = 2 S w 1 − 2 λ 1 w 1 = 0 \frac{\partial L}{\partial \boldsymbol{w}_1}=2 \boldsymbol{S} \boldsymbol{w}_1-2 \lambda_1 \boldsymbol{w}_1=0 ∂w1∂L=2Sw1−2λ1w1=0,
- 那么 S w 1 = λ 1 w 1 \boldsymbol{S} \boldsymbol{w}_1=\lambda_1 \boldsymbol{w}_1 Sw1=λ1w1,即 w 1 \boldsymbol{w_1} w1是 S \boldsymbol{S} S的特征向量。
- 目标函数 J = w 1 T S w 1 = w 1 T λ 1 w 1 = λ 1 J=\boldsymbol{w}_1^T \boldsymbol{S} \boldsymbol{w}_1=\boldsymbol{w}_1^T \lambda_1 \boldsymbol{w}_1=\lambda_1 J=w1TSw1=w1Tλ1w1=λ1
然后考虑第二个方向向量 w 2 w_2 w2,按照上述算法同样计算,能得到 w 2 w_2 w2也是 S S S的特征向量,目标函数为 J = λ 1 + λ 2 J=\lambda_1+\lambda_2 J=λ1+λ2。
依次计算下去,每个坐标轴都是 S S S的特征向量,定义 w d w_d wd是 S S S的第 d d d大特征向量,目标函数为 J = ∑ i λ i J=\sum_i\lambda_i J=∑iλi。
原本我们还需要考虑每个投影坐标轴之间相互正交,现在求出来的坐标轴就是特征向量,一个可逆矩阵的特征向量必定正交,因此我们此时无需再考虑那个条件。( S S S矩阵不一定可逆,因此有基于SVD的PCA)
至此,我们求出了最优的投影坐标轴,并且得到了每个坐标轴所包含的信息量(该坐标轴对应的特征值大小),选的坐标轴越多,所包含的信息越多,维度也越高,选的坐标越少,所包含的信息也越少,维度也越低。
PCA算法流程
输入: X = ( x 1 , x 2 , ⋯ , x N ) X=(x_1,x_2,\cdots,x_N) X=(x1,x2,⋯,xN),低维度空间的维度: D ′ D' D′
算法流程:
-
计算数据的平均值: x ‾ = 1 N ∑ j = 1 N x j \overline{x}=\frac{1}{N}\sum_{j=1}^Nx_j x=N1∑j=1Nxj
-
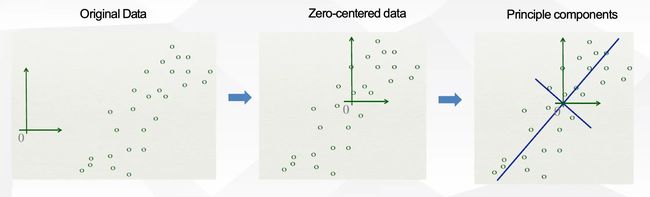
数据中心化: x i = x i − x ‾ x_i=x_i-\overline{x} xi=xi−x(为了保证变化后的 z i z_i zi是中心化的,上述推导用到了 z i z_i zi是中心化的数据)
-
计算协方差矩阵: S = X X T S=XX^T S=XXT
-
对 S S S做特征分解
-
得到最大的 D ′ D' D′个特征值对应的特征向量: w 1 , w 2 , ⋯ , w D ′ w_1,w_2,\cdots,w_{D'} w1,w2,⋯,wD′
输出: W = ( w 1 , w 2 , ⋯ , w D ′ ) W=(w_1,w_2,\cdots,w_{D'}) W=(w1,w2,⋯,wD′)
基于SVD的PCA
在上述PCA算法中,我们要计算协方差矩阵 S = X X T ∈ R D × D S=XX^T\in\mathbb{R}^{D\times D} S=XXT∈RD×D,若原始维度就有 1 0 4 10^4 104,那这个矩阵有 1 0 8 10^8 108个元素,运算量十分巨大。而且还要求 S S S是可逆矩阵,虽然可能90%的情况下 S S S都会是可逆的,但如果这个矩阵就是不可逆,那我们就没法通过上述方法进行降维了。
此时我们需要用到奇异值分解(SVD)方法,SVD的有一些实现能快速获得矩阵的最大 D D D个特征值对应的特征向量,与我们的原始目的一致。

这一部分就不详细讲,有兴趣的可以去看看怎么分解,与降维的关系已经不大了。
基于SVD的PCA算法流程
输入: X = ( x 1 , x 2 , ⋯ , x N ) X=(x_1,x_2,\cdots,x_N) X=(x1,x2,⋯,xN),低维度空间的维度: D ′ D' D′
算法流程:
- 计算数据的平均值: x ‾ = 1 N ∑ j = 1 N x j \overline{x}=\frac{1}{N}\sum_{j=1}^Nx_j x=N1∑j=1Nxj
- 奇异值分解 X = U D × D Σ D × N V N × N T \boldsymbol{X}=\boldsymbol{U}_{D \times D} \boldsymbol{\Sigma}_{D \times N} \boldsymbol{V}_{N \times N}^{\mathrm{T}} X=UD×DΣD×NVN×NT
- D ′ D' D′个奇异值对应的左奇异向量: u 1 , u 2 , ⋯ , u D ′ u_1,u_2,\cdots,u_{D'} u1,u2,⋯,uD′
输出: U = ( u 1 , u 2 , ⋯ , u D ′ ) U=(u_1,u_2,\cdots,u_{D'}) U=(u1,u2,⋯,uD′)
PCA算法中参数的指定
之前推到中看到每个坐标轴方向对应的特征值实际上能表示包含的信息量,因此可以通过这个特征值判断所选择的参数保留了多少原始信息,然后通过一个重建阈值来选择最小的降维维度:
∑ d = 1 D ′ λ d / ∑ d = 1 D λ d ≥ t ( e . g . 方差的85%) \sum_{d=1}^{D^{\prime}} \lambda_d / \sum_{d=1}^D \lambda_d \geq t(\mathrm{e} . \mathrm{g} . \text { 方差的85\%) } d=1∑D′λd/d=1∑Dλd≥t(e.g. 方差的85%)
PCA中保留的信息量一般随着维度增加上升的非常快,因此一般都能降到很低维。

非线性降维KPCA
PCA进阶之KPCA可以看下一篇文章
KPCA非线性降维原理推导