【MEIF:ℓ1-ℓ0混合分解】
Multimodal Medical Image Fusion Using Hybrid Layer Decomposition With CNN-Based Feature Mapping and Structural Clustering
(基于CNN的特征映射和结构聚类的混合层分解的多模态医学图像融合)
本文提出了一种特征级多模态医学图像融合,使用两尺度ℓ1-ℓ0混合层分解方案,以最大限度地提高结构细节,同时抑制显著的噪声和伪影。所提出的方法分别使用具有一致性验证和结构补丁聚类 (基于模糊c均值) 的卷积神经网络 (CNN) 进行分解的基础层和细节层融合。首先,使用颜色空间变换来分离从源图像中提取的亮度和色度分量,并分解每个图像的亮度部分。在第二步中,使用预训练的CNN模型从每个分解的基础层组件中提取突出的特征。对于输出特征图,计算基于区域能量的活动度量并生成融合得分,在一致性验证步骤中对其进行细化,以优化用于融合基础层的权重图。两个比例的细节层由基于聚类的预学习字典合并,以有效地映射层的结构细节。还使用颜色显着性度量来组合与两个图像相关联的颜色分量。最后,融合的基础层,细节层和颜色分量被合并以获得合成的融合图像。
介绍
融合技术大致分为像素、特征和决策级别。通常,这些用于图像融合的抽象级别是在空间和变换域中设计的。但是,空间域方法的对比度和空间定位较差。在这种情况下,不同的多尺度分解,例如离散小波变换 (WT) ,curvelet变换 (CVT) ,平稳WT (SWT),双树复数WT (DTCWT) ,contourlet变换 (CT) ,非下采样CT (NSCT) 和非下采样shearlet变换 (NSST)已被引入,以设计一个有效的平台,提供更好的定位图像轮廓和纹理细节与卓越的视觉质量。基于NSCT的方法在不同的融合规则组合下显示出相当可接受的融合结果。Yang等人提出了NSCT域中的模糊自适应脉冲耦合神经网络 (PCNN)。为了克服NSCT的局限性,基于NSST的融合规则被构建起来,并且在不同的图像处理应用中看起来很有希望,但是仍然缺乏像素对比度和微小边缘的保留。
一种边缘保留分解技术,如混合ℓ1-ℓ0先验层分解,考虑了基础层和细节层的两个单独的正则化参数,以保留弱结构和锋利边缘。该模型能够避免光晕伪影并提供更好的视觉质量。提出了一个统一的融合框架,使用WT和广义同态滤波 融合多模态图像,其中使用灰狼优化估计控制参数。这提供了显著的结果,但存在较高的计算成本。基于引导滤波的图像融合 也变得流行,因为它保留了体面的空间一致性,但在图像边界处遭受空间平滑或阶梯效应的影响。当前,深度学习已有效地用于图像处理的多个应用中,例如图像分割,分类,特征映射和决策。基于卷积神经网络 (CNN)的多模态医学图像融合方案在处理步骤中发挥了重要作用,以提高像素到决策级融合的性能 。这种方法的主要缺点是执行复杂性和模型训练需要大量数据 。此外,提出了一种基于卷积稀疏度的形态成分分析 (CS-MCA) 融合方法,该方法显示出更好的结果,但仍有改善功能成像模态性能的空间。在本文中,针对多模式医学神经图像,提出了一种具有CNN和主成分分析 (PCA) 聚类的新型融合模型。所提出的框架能够有效地捕获空间信息,保持空间一致性并抑制噪声和伪影。
贡献
1)采用新颖的两比例复合ℓ1-ℓ0层分解模型来保留每个比例的所需边缘和强度变化。
2)为了生成像素活动和融合权重图,由于医学图像的准确性低,采用了基于CNN的方法,然后进行一致性验证 (二进制阈值,迭代形态学滤波和加权引导滤波)。
3)基于模糊c均值 (Fuzzy c-means (FCMs)) 聚类的局部内容映射方法用于捕获复杂的细节层结构,然后进行基于PCA的子空间学习。
4)使用广泛的实验结果和使用一些最先进的融合技术对灰色和彩色医学图像进行的比较,证明了所提出框架的有效性。
相关工作
ℓ1-ℓ0混合分解
ℓ1-ℓ0稀疏正则化参数的复合使用,即提出的图像分解方法,如相关文献中所述。ℓ1-渐变先验项很好地保留了图像边缘,但是由于过度平滑的性质,它显示了对结构信息的较差保存。但是,ℓ0梯度先验项具有明显的分段常数属性,因此大大保留了结构细节。首先,在输入图像上应用ℓ1-ℓ0先验,以获得如下公式的第一比例分解分量:
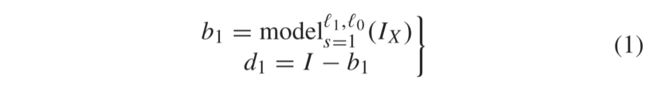
其中s表示比例,而I、b1和d1分别显示输入图像、第一比例基数和细节层。ℓ1-ℓ0优化模型的方程

变量 λ1和 λ2分别是关于两个梯度稀疏项ℓ1-ℓ0的两个正则化参数。第一项指定原始图像和分解的基础层之间的平方误差最小化,以便正确复制主要信息。第二项表示施加在基础层上的1梯度稀疏先验 (边缘保留) 以抑制异常值,第三项表示施加在细节层上的0梯度稀疏先验 (结构表示) 以抑制人工和弱纹理使用函数F(·)表示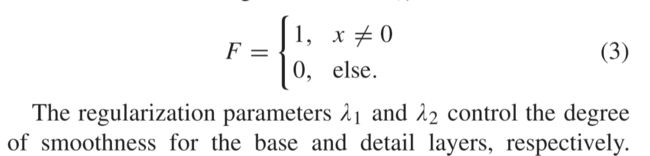
这些正则化参数在很大程度上取决于一阶分解时源图像中存在的像素分布。因此,对于细节层,参数应该较低,而对于基础层,参数必须较高。统计行为的变化更多地在于分解的第一阶段,并随着分解水平的增加而减少。对于第二比例分解,现在在层b1中应用 (2) 中的模型,以保留在第一比例分解期间转移到其上的纹理细节,其余部分将仅包含局部亮度

其中 λ3是最终基层b2的控制参数。在保留较强的基层梯度同时提供分段平滑效果之前, λ3作为ℓ1梯度稀疏性的权重。为了引导最终的基础层组件,对b2和b1进行加权引导滤波,以恢复清晰边界中的空间一致性。重建是通过将所有三层d1、d2和b2求和来完成的,表示为

这两种先验 (基于ℓ1-和ℓ0-的稀疏度参数) 的混合组成显示了图1所示的有效和高效的分解模型。为了实现基层的边缘感知滤波,使用了加权引导滤波器 (WGF) ,它通过去除光晕伪影来增强图像特征。

色调映射算法
逆色调映射相关内容
Convolutional Neural Network
如今,基于CNN的方法已成为多模式医学输入的主要公认模型,用于估计重要的视觉特征和相应的得分图。CNN是一种可训练的前馈神经网络,具有对应于一定数量的特征图的多个阶段。在提出的用于特征映射和基础层融合的工作中使用的基于暹罗的CNN架构具有两个共享相似权重和偏差的通道。与其他网络相比,这在计算上也很容易被训练。预训练的CNN模型具有三个卷积层,然后是非线性激活函数,即每层的整流线性单元 (ReLU) 和一个最大池化层。在建议的融合框架中,使用深度学习平台 “Caffe”从ImageNet数据集中获取的200万块真实和高斯滤波图像训练CNN模型。
训练图像被划分为几个大小为16 × 16的补丁,这些补丁与大小为3 × 3的层内核进行单步幅卷积,并在第一阶段具有64个过滤通道。每个卷积层提取图像特征,并提供深度大小为64 × 2^(i-1)的映射图,其中i = (1,2,3) 是层索引。具有内核大小的下一个最大池化层设置为2 × 2,步幅为2。在第三阶段之后,执行特征图的串联,并生成二维特征向量。此特征向量被送入到两通道soft-max层以计算概率分布,以便生成最终得分图。对于大小为N × M的输入图像,输出特征图的大小为 (N/2 − 2i +1) × (M/2 − 2i +1),其中i = 3,学习率最初设置为10 − 4。在软max层中,使用梯度下降法使输出层的逻辑损失函数最小化,以获得每个层的优化权重和偏置。如图2所示,该网络包含两个随后的卷积层,然后是最大池化层和第三卷积层。
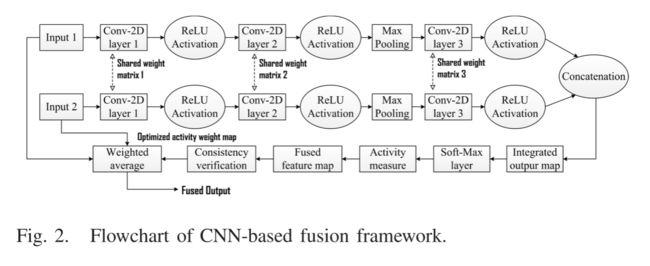

输入和卷积算子 (权重矩阵) 的非线性公式可以表示为:

卷积运算是在大小为n × n的局部掩码内执行的,这对于所有三层都保持不变,而池化层将层输出的分辨率降低了2。
在所提出的框架中,基于CNN的基层融合分三个关键步骤得到: 1) 使用预先训练的CNN模型生成初始特征图; 2) 使用基于加权平均的规则进行活动度量和融合;3) 对融合图像进行一致性验证,以在所得图像中获得足够的对比度和亮度。
Clustering PCA-Based Statistical Feature Mapping
本节重点介绍基于patchwise统计PCA聚类的图像结构特征的保存和增强。该方法由以下三个基本步骤组成: 1) 基于层的几何细节进行补丁划分; 2) 对最大方差区域进行聚类; 以及3) 学习每个类的PCA基础并组合每个子基础以形成复合字典。对于给定的输入数据,基于统计度量 (例如精细细节,局部内容和颜色变化) 应用结构补丁分解。使用FCMs对分解的补丁组进行聚类,以为每个度量生成不同的聚类组。基于统计聚类的融合框架如图3所示。
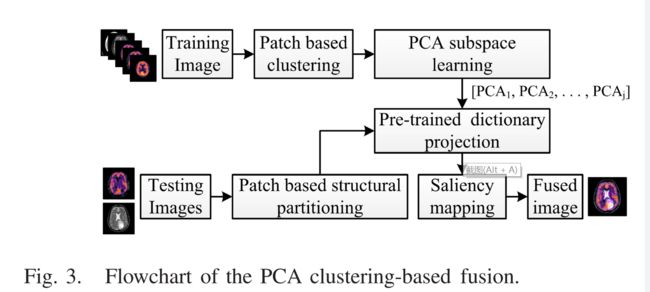
对于输入图像,使用固定的窗口和步长进行重叠的基于补丁的图像分区。图像分区后,每个补丁被分解为两个主要组成部分,即图像的局部均值和细节结构。局部均值 μ 是通过平均在补丁 p中呈现的像素并表示p的平坦区域来计算的。通过从提取的图像补丁p中减去补丁均值来计算Pd表示的细节结构,如下所示:
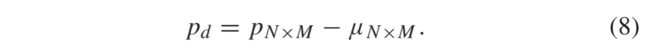
使用上述定义的组件,每个补丁p的重构如下:
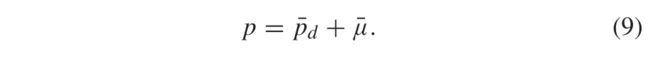
如果输入图像具有三个通道,则分别为每个颜色通道R,G和B计算两个分解的分量,然后将每个补丁重建为
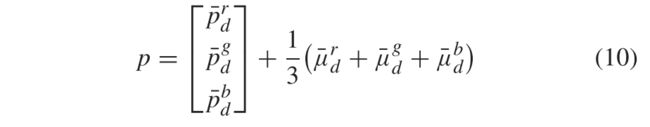
其中,第一分量表示从三个通道提取的颜色结构,第二分量表示三通道色块的平均局部均值。
在下一阶段,基于结构相似性,使用补丁聚类来捕获聚类中的像素。为了对像素进行聚类,使用了基于FCM的学习方法。每个簇都是通过使用PCA构造的子空间基础来定义的,以获取输入数据的突出结构。最后,将生成的表示细节图像中最常见和最重要特征的PCA基础应用于将图像补丁转换为PCA子空间。
方法
流程图如下:

Implementation Steps
Step 1:
使用给定的表达式将输入图像的RGB模型隐藏到YIQ颜色空间中

其中,Y指亮度,I和Q分别指基于色度的 “同相(in-phase)” (青色-红色轴) 和 “正交相(quadrature-phase)” (品红色-绿色) 分量。
Step 2:

Step 3(Base-Layer Fusion):
基于CNN的融合方法用于合并每个分解数据中的基本层组件。为了实现这种方法,使用了已有的预训练的CNN模型,并在输出层获得了特征图。对于每个输入,使用基于特征的活动得分图,然后进行一致性验证来优化特征图。详细的融合过程按以下步骤给出:

2)使用来自第三卷积层的串联输出特征图OX计算二维软最大层的初始权重图WX(y,z),并表示为:

3)使用基于块的区域能量 (block-based regional energy (RE)) 作为单个输出图的活动度量来计算融合的权重图,并使用上采样进行加权平均,以获得与参考输入大小相似的最终活动


其中b和a分别指块大小和上采样单位。此处考虑块大小b = 5,以保留从CNN映射的有用高频特征 (即边缘),并具有所需的伪影抑制。将上采样步长设置为a = 8,以使用关系a = (0,1,·,2^(i-1)-1) 重建映射并调整到源图像的初始特征,其中i是层在卷积网络中。最后,结合结果活动图以保留相对于两个基础层系数的大多数突出内容 (亮度和结构信息),如下所示:
4)Postprocessing of decision map:
决策图的后处理: 为了得到优化的决策图,后处理分三个步骤进行: 1) 初始分割图,使用阈值取中值 (WF(y,z)) 的二进制阈值,获得二进制分割图;2) 使用bwareaopen和close操作进行形态学滤波,以减少错误分类的像素 (平滑的微小区域); 3) 基于加权引导滤波的权重图优化。最终决策图提高了空间一致性,抑制了噪声和伪像。[0015] 设针对步骤2后得到的目标分割图像t (y,z) 、融合制导图像g(y,z) 、优化后的最终决策图D(y,z)

Step 4(Detail-Layer Fusion):
对于细节层融合,采用了基于统计聚类的PCA 的概念,从而显着提高了对比度水平并增强了整体图像清晰度。考虑以下程序来实现如下讨论的融合过程。
1)1) PCA基础学习: 使用离线学习过程生成紧凑的PCA基础,以提高计算效率。训练阶段是用大小为256 × 256的130医学图像完成的。将基于sliding window的补丁提取 (补丁大小为8,步幅为1) 应用于训练数据集,并为每个补丁计算两个结构组件 (补丁平均值和补丁详细信息)。基于FCM的结构聚类用于索引具有几乎相似特征但强度不同的N个组中的补丁。对于每个聚类,通过选择最上层的主成分来计算聚类质心和基于PCA的近似模型。合成的主子空间被组合以生成字典P,该字典由群集补丁的主要元素组成。
2)将细节层组件DX划分为重叠的补丁 (大小8和步骤1) pX i,其中X ∈ (R,S) 和i ∈ (2,1) 是分解标度。
3) 对于每个补丁,将统计信息计算为补丁平均值和补丁结构,分别用 μ x i和pX i表示。


7)使用基于局部对比度变化的显着性度量来融合贴片结构信息,以保留边缘细节,然后匹配显着性度量。


Τ 是视觉阈值,用于控制在两个不同的源图像之间映射的基于显着性的匹配度量。上述公式呈现了LC(y,z) 和M(y,z) 之间的相互依赖性,然后是决策权重图d(y,z) ∈ [0,1]。如果基于局部对比度的图案相似度高于视觉阈值 (τ),则基于两个图像之间的主导图案,决策权重图将几乎变化约 ± 0.5。然而,如果在给定空间位置处的相似度低于视觉阈值或者显著图案的相关性较小,则具有更显著显著的图像将更典型地由决策图中的dmax(y,z) = τ 加权。在建议的工作中,考虑参数 τ = 0.7,以根据Burt的方法生成最佳的决策权重图。
8) 组合步骤6和7中的融合贴片,以重建给定的融合细节层

Step 5:
使用三个融合层重建所得的融合亮度图像,可以表示为

Step 6:
使用下面给出的表达式,使用YIQ到RGB变换将融合图像重新转换为RGB颜色空间,并获得融合结果
PS:色调映射不错,其他的感觉就是在一直输出公式。