UP-DETR:收敛更快!精度更高!华南理工&微信开源无监督预训练目标检测模型...
关注公众号,发现CV技术之美
0
写在前面
基于Transformer编码器-解码器结构的DETR达到了与Faster R-CNN类似的性能。受预训练Transformer在自然语言处理方面取得巨大成功的启发,作者提出了一种基于random query patch detection 预训练代理任务的无监督预训练DETR(UP-DETR)来用于目标检测。
该模型在预训练过程中,能够从原始图像中检测出查询patch。在预训练任务中,作者主要解决了两个关键问题:多任务学习 和多查询定位 :
1)为了权衡代理任务中的分类和定位的重要性,作者冻结了CNN主干网络,并提出了一个与patch检测联合优化的patch特征重构分支 。
2)为了实现多查询定位,作者基于单查询patch,将其扩展到具有对象查询shuffle 和注意力掩码 的多查询patch中,进一步缩小预训练任务和目标检测任务之间的gap。
实验表明,UP-DETR显著提高了DETR的性能,在目标检测、one-shot检测和全景分割任务上具有更快的收敛速度和更高的精度。
1
论文和代码地址

UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
论文地址:https://arxiv.org/abs/2011.09094
代码地址:https://github.com/dddzg/up-detr
CVPR 2021 Oral 论文。
2
Motivation

DETR是目前目标检测的一个新框架,它将目标检测任务视为通过Transformer编码器-解码器的直接预测问题。在没有手工设计的anchor机制和nms的情况下,DETR达到了与Faster R-CNN相似的性能。
然而,DETR需要大规模的训练数据和更长的训练时间。上表展示了DETR和UP-DETR在训练过程中精度的变化,可以看出DETR的收敛速度更慢。此外,作者也发现,当DETR用于小规模的数据训练时(比如:PASCAL VOC),它的模型性能会有显著的下降。
通过设计良好的预训练代理任务,无监督的预训练模型在自然语言处理(如GPT和BERT)和计算机视觉(如MoCo和SwAV)上取得了快速的发展。在DETR中,CNN主干网络是用ImageNet预训练过的,能够提取良好的视觉表示,但Transformer模块并没有进行预训练。
此外,虽然无监督视觉表征学习在最近的研究中引起了广泛关注,但现有的这些代理任务都不能直接应用于DETR的预训练。其主要原因是DETR主要关注空间定位学习,而不是基于图像实例或基于聚类的对比学习 。
受自然语言处理中无监督预训练的启发,本文的目标是在一个大规模的数据集(如ImageNet)上对DETR中的Transformer进行无监督的预训练,并将目标检测作为下游任务进行处理 。然而,现有的代理任务大多是基于图像实例和聚类的学习,不适用于目标检测。
因此,作者在本文中提出了一个新的用于目标检测的代理任务——random query patch detection ,并基于这个预训练代理任务提出了无监督预训练DETR(UP-DETR)。该任务从给定的图像中随机裁剪多个查询patch,并对Transformer进行检测的预训练,以预测给定的图像中这些查询patch的边界框。
在预训练过程中,作者主要解决了两个问题:
1)多任务学习 :目标检测是目标分类和目标定位任务的耦合。为了避免查询patch检测破坏分类特征,作者提出冻结预训练主干网络 和patch特征重建 ,以保持Transformer的特征识别。
2)多查询定位 :单查询patch预训练不能满足目标检测的要求,而直接将单查询patch的版本拓展为多查询版本又会存在一些问题。因此,对于多查询patch,作者设计了对象查询shuffle 和注意掩码机制 ,来解决查询patch和对象查询之间的分配问题。
3
方法
UP-DETR包括预训练和微调两个过程:
1)Transformer在无任何人工标注的大规模数据集上进行无监督预训练;
2)整个模型使用标注的数据进行微调,这与下游任务上的原始DETR相同。
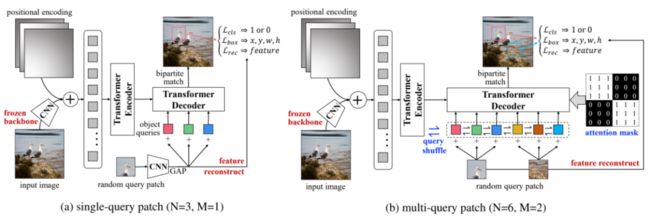
UP-DETR的流程如上图所示,首先一个冻结参数的CNN backbone用于提取视觉特征 。然后,将位置编码添加到特征映射中,并传递到DETR中的Transformer编码器。对于随机裁剪的查询patch,用具有全局平均池化(GAP)的CNN主干网络提取patch特征,然后将其与目标查询相加之后输入到Transformer的解码器中。在预训练过程中,解码器预测与查询patch的位置相对应的边界框。
3.1. Single-Query Patch
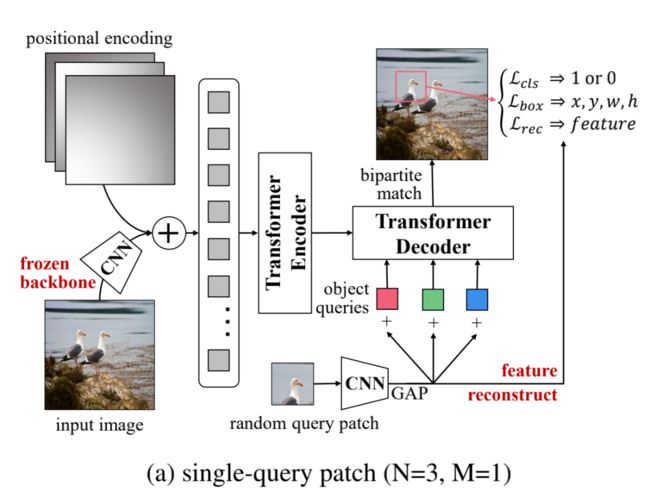
DETR为每个对象查询(object queries)学习不同的空间位置,这表明不同的对象查询关注于不同的位置区域和框大小。由于这些patch是从图像中随机裁剪的,因此没有任何关于查询patch的位置和框大小的先验。为了使得patch和查询能够对应,作者显式地为所有对象查询(M=3)指定单个查询patch(M=1),如上图所示。
在预训练过程中,将patch特征p添加到每个不同的对象查询q中,解码器生成N个预测来检测p的边界框在输入图像中的位置和大小。与DETR相同,作者也是通过匈牙利算法来进行查询和patch之间的匹配。
解码器的预测结果包含三个部分(,,),其中为每个对象查询分类的结果;为每个检测框的中心位置和宽高,,,,为重建之后的特征(这一部分的重建损失函数会在下一节中介绍)。最后,预训练的损失函数定义如下:
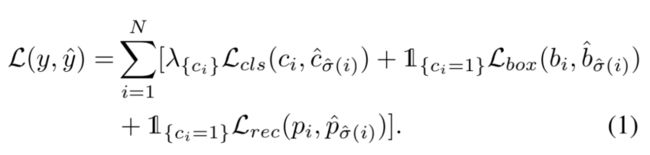
其中为对象查询是否匹配的二分类损失函数;为用于定位的L1损失函数;是用于平衡分类任务和定位任务的损失函数。
3.1.1 Patch Feature Reconstruction
目标检测是目标分类和目标定位任务的耦合,其中这两个任务具有不同的特征偏好。与DETR不同,作者提出了一个特征重构损失函数来在定位预训练任务中保持分类特征的特性。因此,这个损失函数是为了将CNN的特征输入到Transformer中之后,依旧能够保持CNN的特征性质。的定义如下所示:

3.1.2 Frozen Pre-training Backbone
由于作者希望让Transformer之后的特征能和CNN的特征尽可能相似,从而保留分类的特征特性。因此,作者在预训练的时候固定住了CNN Backbone的参数,并通过损失函数,使得Transformer之后的特征与CNN提取的特征尽可能相似。此外,稳定CNN主干网络的参数更有利于Transformer的训练,从而加速模型的训练。
3.2. Multi-Query Patches
对于一般的目标检测,每个图像中都有多个目标实例(例如,COCO数据集中每个图像平均有7.7个目标实例)。此外,当对象查询的数量N较大时,单个查询patch可能会收敛困难。因此,单查询patch预训练与多目标的检测任务目标是不一致的。然而,将单个查询patch扩展到多查询patch也是不简单的,因为M个查询patch和N个对象查询之间的如何对齐也存在一定的问题。
为了解决这个问题,作者将N个对象查询划分为M个组,其中每个查询patch都按顺序被分配给N/M个对象查询。例如,第一个查询patch被分配给第一组N/M个对象查询,第二个查询patch被分配给第二组N/M个对象查询,以此类推。但是在这里,预训练需要满足两个要求:
1)查询patch的独立性(Independence of query patches) :所有的查询patch都是从图像中随机裁剪出来的。因此,它们是独立的,没有任何关系。
2)对象查询的多样性(Diversity of object queries) :在下游任务的对象查询之间没有显式的组分配。换句话说,查询patch在理想情况下可以添加到任意的N/M个对象查询中。
3.2.1 Attention Mask
为了满足查询patch的独立性,作者使用一个attention mask矩阵来控制不同对象查询之间的交互。具体实现为,将mask矩阵添加到原来self-attention中softmax之后的attention矩阵上。mask矩阵定义如下:

其中,,用来确定对象查询是否与对象查询进行交互。
3.2.2 Object Query Shuffle

在上述的描述中,对象查询组都是人工分配的。但是,在下游目标检测任务中,对象查询之间没有显式的组分配。因此,为了模拟目标检测的下游任务,作者在预训练过程中随机打乱所有对象查询的排列。
如上图所示,作者使用了基于注意力mask和对象查询shuffle的多查询patch预训练。此外,为了提高模型泛化性,作者在预训练过程中随机将10%的查询patch设置为0,类似于dropout。
4
实验
4.1. PASCAL VOC Object Detection

上表显示了PASCAL VOC数据集上DETR和UP-DETR的性能对比,可以看出,在小数据集上,UP-DETR的性能明显优于DETR。
4.2. COCO Object Detection
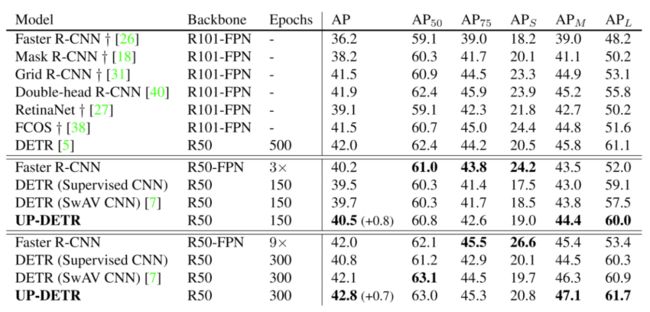
上表显示了COCO数据集上各种目标检测方法的性能对比,可以看出UP-DETR能够达到比较不错的性能。
4.3. One-Shot Detection

上表展示了one-shot detection任务上的不同模型性能对比。与DETR相比,UP-DETR在见过和未见过的类上都显著提高了DETR的性能。
4.4. Panoptic Segmentation

上表显示了全景分割任务上,本文方法和SOTA方法的对比,可以看出,相比于DETR,UP-DETR依旧具备性能上的优势。
4.5. Ablations

上表显示了冻结CNN参数和特征重建模块的消融实验,可以看出,冻结CNN的参数对于模型性能的提升有非常大的作用。

上表显示了四种不同UP-DETR模型在训练过程中,模型性能的变化。可以看出(d) UP-DETR相比于其他UP-DETR模型结构具有更快的收敛速度和更高的精度。
4.6. Visualization

上图显示了不同查询patch在预训练过程中,得到的无监督结果。说明采用随机查询patch检测的UP-DETR可以有效地学习目标定位的能力。
5
总结
在本文中,作者提出了一种新的预训练代理任务——random query patch detection ,来对DETR中的Transformer进行预训练。在无监督预训练下,UP-DETR在目标检测、one-shot检测和全景分割任务上显著优于DETR。即使在有足够训练数据的COCO数据集上,UP-DETR仍然表现优于DETR。
近年来对无监督预训练的研究主要集中在对比学习的特征识别上,而没有为目标检测任务这类空间定位的任务设计专门的模块。UP-DETR填补了这一部分的空白,使得模型能够通过学习空间位置来进行预训练。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「目标检测」交流群备注:OD
