AI处理器-寒武纪NPU芯片简介
一、前言
当今时代,人工智能(AI)正被广泛运用于各式各样的应用上。人工智能的三大支撑是硬件、算法和数据,其中硬件指的是运行 AI 算法的芯片与相对应的计算平台。由于使用场景变多,所需处理的数据量变大,人们的需求也更高,这就使得AI算法必须能够高效的运行在硬件平台上。在硬件方面,目前主要是使用 GPU 并行计算神经网络,同时,还有 FPGA 和 ASIC 也具有未来异军突起的潜能。
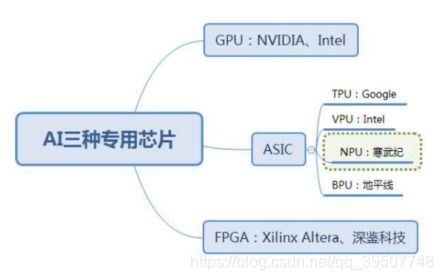
GPU称为图形处理器,它是显卡的“心脏”,与 CPU 类似,只不过是一种专门进行图像运算工作的微处理器。GPU 在浮点运算、并行计算等部分计算方面可以提供数十倍乃至于上百倍于 CPU 的性能。不过在应用于深度学习算法时,有三个方面的局限性:
- 应用过程中无法充分发挥并行计算优势
- 硬件结构固定不具备可编程性
- 运行深度学习算法能效远低于 ASIC 及 FPGA。
FPGA称为现场可编程门阵列,用户可以根据自身的需求进行重复编程。与 GPU、CPU 相比,具有性能高、能耗低、可硬件编程的特点。FPGA 比GPU 具有更低的功耗,比 ASIC 具有更短的开发时间和更低的成本。FPGA也有三类局限:
- 基本单元的计算能力有限;
- 速度和功耗有待提升;
- FPGA 价格较为昂贵。
ASIC(Application Specific Integrated Circuit)是一种为专门目的而设计的集成电路。无法重新编程,效能高功耗低,但价格昂贵。近年来涌现出的类似TPU、NPU、VPU、BPU等令人眼花缭乱的各种芯片,本质上都属于ASIC。ASIC不同于 GPU 和 FPGA 的灵活性,定制化的 ASIC 一旦制造完成将不能更改,所以初期成本高、开发周期长的使得进入门槛高。目前,大多是具备 AI 算法又擅长芯片研发的巨头参与,如 Google 的 TPU。由于完美适用于神经网络相关算法,ASIC 在性能和功耗上都要优于 GPU 和 FPGA,TPU1 是传统 GPU 性能的 14-16 倍,NPU 是 GPU 的 118 倍。寒武纪已发布对外应用指令集,预计 ASIC 将是未来 AI 芯片的核心。
综上所述,在性能上,ASIC是优于另外几种计算方案的。在ASIC类众多芯片中,NPU的性能非常的突出,所以下面来介绍一下NPU。
二、NPU介绍
所谓NPU(Neural network Processing Unit), 即神经网络处理器。顾名思义,它是用电路来模拟人类的神经元和突触结构!如果想用电路模仿人类的神经元,就得把每个神经元抽象为一个激励函数,该函数的输入由与其相连的神经元的输出以及连接神经元的突触共同决定。为了表达特定的知识,使用者通常需要(通过某些特定的算法)调整人工神经网络中突触的取值、网络的拓扑结构等。该过程称为“学习”。在学习之后,人工神经网络可通过习得的知识来解决特定的问题。
由于深度学习的基本操作是神经元和突触的处理,而传统的处理器指令集(包括x86和ARM等)是为了进行通用计算发展起来的,其基本操作为算术操作(加减乘除)和逻辑操作(与或非),往往需要数百甚至上千条指令才能完成一个神经元的处理,深度学习的处理效率不高。这时就必须另辟蹊径——突破经典的冯·诺伊曼结构!
神经网络中存储和处理是一体化的,都是通过突触权重来体现。 而冯·诺伊曼结构中,存储和处理是分离的,分别由存储器和运算器来实现,二者之间存在巨大的差异。当用现有的基于冯·诺伊曼结构的经典计算机(如X86处理器和英伟达GPU)来跑神经网络应用时,就不可避免地受到存储和处理分离式结构的制约,因而影响效率。这也就是专门针对人工智能的专业芯片能够对传统芯片有一定先天优势的原因之一。
NPU的典型代表有国内的寒武纪(Cambricon)芯片和IBM的TrueNorth。以中国的寒武纪为例,2016年3月,中国科学院计算技术研究所陈云霁、陈天石课题组提出了国际上首个深度学习处理器指令集DianNaoYu。DianNaoYu指令直接面对大规模神经元和突触的处理,一条指令即可完成一组神经元的处理,并对神经元和突触数据在芯片上的传输提供了一系列专门的支持。
三、寒武纪NPU介绍
2016年,寒武纪科技发布了世界首款终端AI处理器、首款商用神经网络处理器(NPU)“寒武纪1A”(Cambricon-1A),面向智能手机、安防监控、可穿戴设备、无人机和智能驾驶等各类终端设备,主流智能算法能耗比全面超越传统CPU、GPU。其高性能硬件架构及软件支持Caffe、Tensorflow、MXnet等主流AI开发平台。可广泛应用于计算机视觉、语音识别、自然语言处理等智能处理关键领域。
2017年,寒武纪科技又发布了第二代NPU架构“寒武纪1H”(Cambricon-1H),该系列较初代产品1A系列其能效比有着数倍提升,可以广泛应用于计算机视觉、语言识别、自然语言处理等智能处理关键领域。其中,Cambricon-1H16版本的IP作为1H系列高性能版本使用256MAC 16位浮点运算器以及512MAC 8位定点运算器。在1GHz主频下,进行16位浮点神经网络运算的峰值速度为0.5Tops;进行8位定点神经网络运算的峰值速度为1Tops。Cambricon-1H8版本IP作为1H系列中量级版本使用512MAC 8位定点运算器。在1GHz主频下,进行8位定点神经网络运算的峰值速度为1Tops。Cambricon-1H8mini版本IP作为1H系列轻量级版本使用256MAC 8位定点运算器。在1GHz主频下,进行8位定点神经网络运算的峰值速度为0.5Tops。
2018,寒武纪科技又发布了第三代IP产品“寒武纪1M”(Cambricon-1M),全球首个采用台积电7nm工艺制造,能耗比达到5Tops/W,即每瓦特5万亿次运算,并提供2Tops、4Tops、8Tops三种规模的处理器核,满足不同场景、不同量级的AI处理需求,并支持多核互联。寒武纪1M处理器延续了前两代IP产品寒武纪1H/1A卓越的完备性,单个处理器核即可支持CNN、RNN、SOM等多样化的深度学习模型,更进一步支持SVM、k-NN、k-Means、决策树等经典机器学习算法,支持本地训练,为视觉、语音、自然语言处理以及各类经典的机器学习任务提供灵活高效的计算平台,可广泛应用于智能手机、智能音箱、智能摄像头、智能驾驶等领域。
四、Cambricon-1A NPU应用
这里要首先介绍一下华为海思的麒麟970手机处理器,是因为它是全球首款人工智能移动计算平台,是业界首颗带有独立NPU(Neural Network Processing Unit)专用硬件处理单元的手机芯片。麒麟970创新性的集成了NPU专用硬件处理单元,创新设计了HiAI移动计算架构,其AI性能密度大幅优于CPU和GPU。相较于四个Cortex-A73核心,处理相同AI任务,新的异构计算架构拥有约 50 倍能效和 25 倍性能优势,图像识别速度可达到约2000张/分钟。而如此强大的NPU专用硬件处理单元,正是使用的寒武纪的Cambricon-1A系列的IP,也即麒麟970芯片集成了“寒武纪1A”处理器作为其核心人工智能处理单元(NPU)。