YOLOV1要点总结
YOLOV1论文要点总结
写在前面
YOLO作为目标检测领域重要one-stage的模型,从提出之初就受到广泛关注,现在基于YOLO的version层出不穷。本博客作为本人学习笔记,依照YOLOV1原论文总结了YOLOV1的模型要点。本博客主要从其思想、模型搭建、损失函数以及其缺点等展开总结。本博客中YOLO均指代YOLOV1。
学习视频点击此处

目录
- YOLOV1论文要点总结
-
- 一、主要思想
-
- 1. 分类还是回归?
- 2. One-stage,快!
- 3. 总揽全局:You Only Look Once
- 二、模型架构
-
- 1. Grid网格划分
- 2. 每个网格cell的预测
- 3. 网络设计
- 三、损失函数
-
- 1. L o s s b − b o x Loss_{b-box} Lossb−box 损失
- 2. L o s s c o n f i d e n c e Loss_{confidence} Lossconfidence 损失
- 3. L o s s c l s Loss_{cls} Losscls 损失
- 4. 惩罚项 λ c o o r d \lambda_{coord} λcoord 与 λ n o o b j \lambda_{noobj} λnoobj
- 四、训练细节
- 五、优点与缺点
-
- 1. 优点
- 2. 缺点
一、主要思想
1. 分类还是回归?
YOLO的作者认为,当时主流的目标检测模型是以各种“Classfier”为核心的。例如DPM使用滑窗在整个图片上均匀探测目标;R-CNN使用候选兴趣区域,有针对的对图片局部进行卷积提取特征并分类等。YOLO则将目标检测问题视为“Regerssion”问题,在空间上分离了b-box并结合了类别概率。
2. One-stage,快!
YOLO不像R-CNN家族的two-stage策略,它仅需训练的单个task,便能得到待检测物体的cls与b-box信息。是一种端到端的学习。one-stage的策略造就了YOLO快的特点,基础网络可以跑到45fps,更快的fast版本甚至可以达到150fps,并且在实时视频处理上有低的延迟。
3. 总揽全局:You Only Look Once
YOLO不像DPM以及R-CNN等一次只关注某个局部特征,它看到的是整张图片。就像人一样,只需看到整张图片一眼,就能分辨出图中的目标。看到整张图片代表YOLO对整个图片隐式编码,论文证实这有效的降低了背景识别的错误率。
二、模型架构
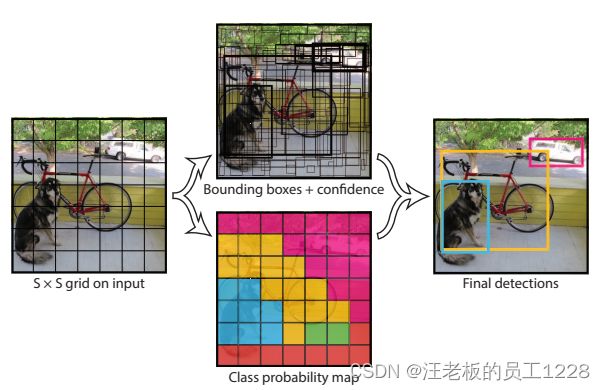
1. Grid网格划分
模型先将输入的图片划分为SxS个cell,在训练阶段,若目标的GT b-box中心点落入一个grid,此cell则负责这个目标。这点将在损失函数部分作为重点辨析概念。原论文设置S为7。
2. 每个网格cell的预测
每个网格经过网络,输出三种数据:B个b-box数据;B个confidence置信度数据;C个类别概率。 原论文分别设置为2, 20。
(1)b-box数据包含{x, y, w, h},均为相对偏移坐标。x, y是相对于网格的偏移;w, h是相对于整张图片的偏移。偏移量使用归一化操作得到,均在0-1范围内。
(2)confidence置信度用于衡量网络对对应b-box的相信程度。 confidence数量与b-box数量一致且相对应。具体计算方式为:
C o n f i d e n c e = P r ( O b j e c t ) ∗ I O U p r e d t r u t h Confidence = Pr(Object) * IOU_{pred}^{truth} Confidence=Pr(Object)∗IOUpredtruth
等式右边第一项为0-1函数:若此grid里没有负责任何目标,则为0,即confidence也为0;否则则为1。第二项则是预测出的b-box与GT b-box的IOU值。作者希望有目标的grid里,confidence代表网络预测的b-box框住GT的能力。
(3)类别概率为该grid对于其负责的目标分类的概率。 其总是一个C维的向量,与b-box数量B无关。
则每张图片最终输出tensor维度为:S x S x (5 * B + C)。 即为7 x 7 x 30。 这是对于PASCAL VOC数据集的设置。
3. 网络设计
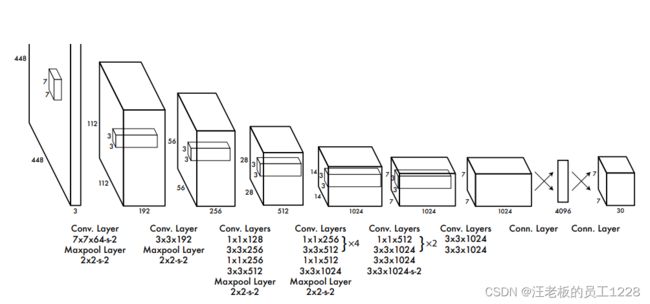
(1)预训练部分网络
结构图中前20个conv层预先在ImageNet 1000-class 比赛数据集上预训练。模型需要稍加修改为20conv层 + avg pooling layer + FC layer 去预训练。预训练输入图片大小为224x224。正式训练输入图片大小为448x448。作者解释为:检测task需要更细粒度的info,所以使用了更大的图片输入size。
(2)激活函数
除最后一个FC层外,其余层激活函数均使用使用Leaky ReLU。具体参数如下:
ϕ ( x ) = { x , i f x > 0 0.1 x , o t h e r w i s e \phi(x) = \left\{ \begin{array}{rcl} x,\quad &&{if \quad x > 0}\\ 0.1x, &&{otherwise} \end{array} \right. ϕ(x)={x,0.1x,ifx>0otherwise
最后一个FC层使用线性激活函数。
(3)主要结构
conv部分有24个卷积层,有s-x的代表卷积步长设为x。具体参数如图中所示。网络还包含了4个max pooling层,皆将图片下采样为一半size。
主结构包含2个FC层。第一个FC层先进行了flatten操作再计算,最后一个FC层先计算再反flatten为7x7x30的tensor作为输出,tensor大小适用于PASCAL VOC数据集。
三、损失函数
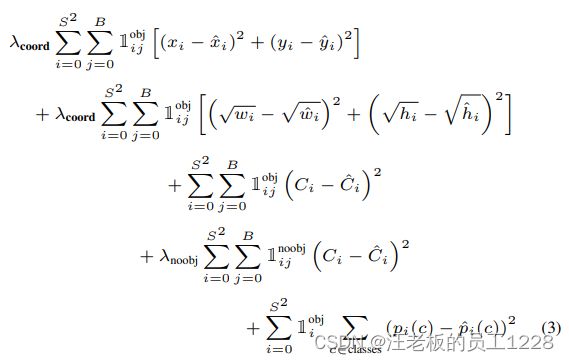
损失函数包含三个部分,皆采用平方和损失,即:
L o s s = L o s s b − b o x + L o s s c o n f i d e n c e + L o s s c l s Loss = Loss_{b-box} + Loss_{confidence} + Loss_{cls} Loss=Lossb−box+Lossconfidence+Losscls
分别对应图中第1-2, 3-4, 5行。各字母所代指概念前文大部分已提到,只需注意带hat的为GT值, p i ( c ) p_{i}(c) pi(c)为第i号cell在类别c上的分类预测概率。注意:此损失函数为计算单个类别物体loss的公式,并非网络总loss。
1. L o s s b − b o x Loss_{b-box} Lossb−box 损失
L o s s b − b o x Loss_{b-box} Lossb−box 衡量bbox的预测准确程度。 1 i j o b j \mathbb{1}_{ij}^{obj} 1ijobj 代表只计算对存在目标的i号cell负责的j号bbox的loss。这里bbox长宽参数先开了平方再进行计算loss的原因是:为了使不同尺寸bbox对于同等数值上的偏移应有不同的影响结果(这里有详细解答)。
2. L o s s c o n f i d e n c e Loss_{confidence} Lossconfidence 损失
L o s s c o n f i d e n c e Loss_{confidence} Lossconfidence 衡量confidence值的预测准确程度。同样的, 1 i j o b j \mathbb{1}_{ij}^{obj} 1ijobj 代表只计算对存在目标的i号cell负责的j号bbox的confidence的loss,但 1 i j n o o b j \mathbb{1}_{ij}^{noobj} 1ijnoobj 代表只计算不存在目标的i号cell负责的j号bbox的confidence的loss。还需要注意的一点是:由confidence的定义公式, 1 i j o b j \mathbb{1}_{ij}^{obj} 1ijobj 对应的confidence GT值为1, 1 i j n o o b j \mathbb{1}_{ij}^{noobj} 1ijnoobj 对应的confidence GT值应该为0。即无目标的cell按照公式计算的confidence GT值就该为0。
3. L o s s c l s Loss_{cls} Losscls 损失
L o s s c l s Loss_{cls} Losscls 衡量各类别概率预测的准确程度。 1 i o b j \mathbb{1}_{i}^{obj} 1iobj 代表只计算存在目标的i号cell上各类别预测概率的累加loss。对于此类别的GT概率值采用one-hot编码,即只有一项为1,其余为0。
4. 惩罚项 λ c o o r d \lambda_{coord} λcoord 与 λ n o o b j \lambda_{noobj} λnoobj
λ c o o r d \lambda_{coord} λcoord 用于调整 L o s s b − b o x Loss_{b-box} Lossb−box 与 L o s s c l s Loss_{cls} Losscls 的平衡。作者认为两者维度不匹配(前者维度为4 * B,后者维度为C),所以需要惩罚项平衡。原论文实验中此项设置为5。
λ n o o b j \lambda_{noobj} λnoobj 用于调整 L o s s c o n f i d e n c e Loss_{confidence} Lossconfidence 两项内部的平衡。作者发现一张图片中许多cell并未包含任何目标,所以需要平衡有目标与无目标loss之和。原论文实验中此项设置为0.5。
四、训练细节
- 数据集:PASCAL VOC 2007&2012,类别数为20
- 输入:resize为448x448x3的RGB图片
- 输出:7x7x30的tensor
- Optimizer : SGD with batch=64、momentum=0.9、weight decay=0.0005
- Epoch:135
- Learning rate scheduler :
| Epoch | Learning Rate |
|---|---|
| First epochs | 10-2 ~ 10-3 ,预热 |
| ~ 75 | 10-2 |
| 76 ~ 105 | 10-3 |
| 106 ~ 135 | 10-2 |
- Dropout : 在第一个FC层后使用p=0.5的dropout
- Data augmentation : 对图像随机缩放和平移,最大可达原始图像大小的20%;调整图像的曝光和饱和度,将其随机调整到HSV颜色空间中的1.5倍
五、优点与缺点
1. 优点
- 快且准确率不俗
- 迁移到其他任务的能力强
2. 缺点
- YOLO对相互靠近的物体,以及很小的群体检测效果不好。这是因为一个网格只预测了B个框,并且每个cell都只属于同一类,只有一个one-hot类别概率tensor。
- 在w,h的损失上的处理并未完全解决问题,只是一定程度上缓解了不同size的bbox对于相同偏移不平衡的问题。作者提到:特别是针对小物体的预测,YOLO还有待加强。YOLO出现的主要问题也是bbox的准确度不高。
- YOLO对不常见的角度的目标泛化性能偏弱。