【基于深度学习的细粒度分类笔记5】22岁复旦学生拿下世界深度学习竞赛冠军:50层ResNet网络
【导读】 拥有世界上最大的开源车对车(V2V)网络的 Nexar 公布了第二届 Nexar 挑战赛的结果。来自复旦大学的Hengduo Li 拿下冠军。
10月29日,Nexar 公布了第二届 Nexar 挑战赛(使用NEXET 数据库实现户外汽车识别)的获奖名单。Nexar公司成立于2015年,使用智能手机和车辆的摄像头和传感器来创建驾驶感知和ADAS警报,以及发生碰撞时记录的证据。
Nexar 通过将智能手机转变为相互连接的 AI “汽车前端摄像头”,构建了世界上最大的开源车对车(V2V)网络。 通过将深度学习技术加入由用户产生的数百万众包汽车驾驶里程数上,Nexar希望提供一种新的,更安全的驾驶体验。
Nexar正在建立一个 ADAS系统,该系统是基于安装在全球各地的消费者汽车上单眼摄像机,这些摄像机在所有天气,光线条件和驾驶场景下都不断拍摄世界道路的图像。

在这个挑战中,参赛者被要求开发后方车辆检测功能,计算前方每个清晰可见的车辆周围的边界框(bounding boxes)。检测器应该寻找相机前方与司机驾驶方向相同的汽车。
这个感知任务的目的是改善Nexar的前方车辆碰撞预警(Forward Vehicle Collision Warning)功能,该功能需要对前方车辆四周有非常精确的边界框。
NEXET 数据库
Nexar介绍,对于这个挑战,他们发布了世界上最大和最多样化的道路数据集之一。他们的愿景是创造一个“无碰撞”的世界,这是一个全球性的计划,所以,他们选择开源部分自己的训练数据,让更多的研究者开源从Nexar每日搜集的海量图像和视频数据中获利。
目前为止,该数据集只为参赛者提供,很快它将作为全球研究人员的免费数据集提供。有关此数据集的更多信息,请参阅此博文:NEXET - 世界上最大和最多样化的道路数据集。https://www.getnexar.com/challenge-2/
比赛结果
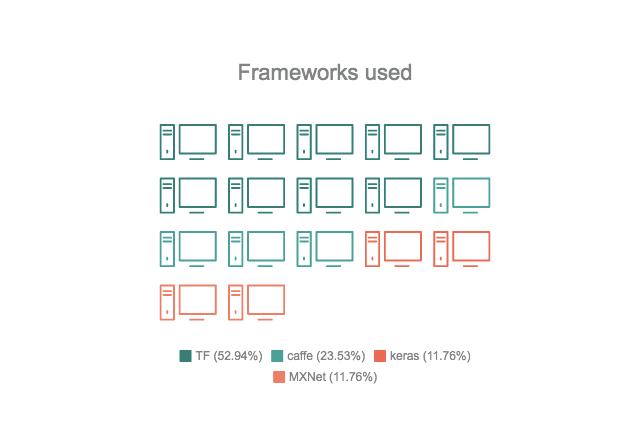
比赛中研究者使用的框架占比分布:TensorFlow 52.94%、Caffe 23.53%、Keras 11.76%、MXnet 11.76%。
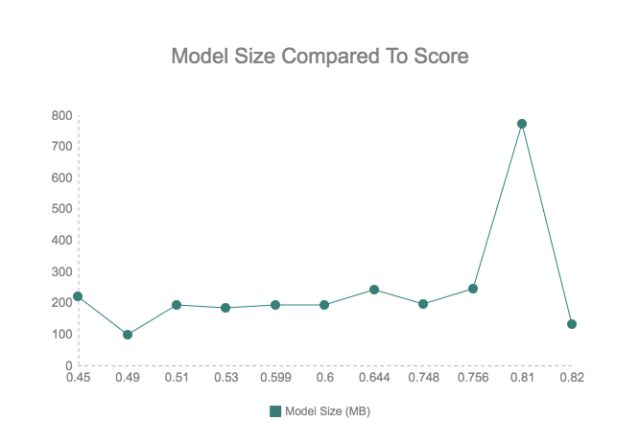
比赛中出现了各种各样的网络 :包括多个网络的集成,从而得到非常大的模型,但是最终我们看到, 模型大小通常并不重要。
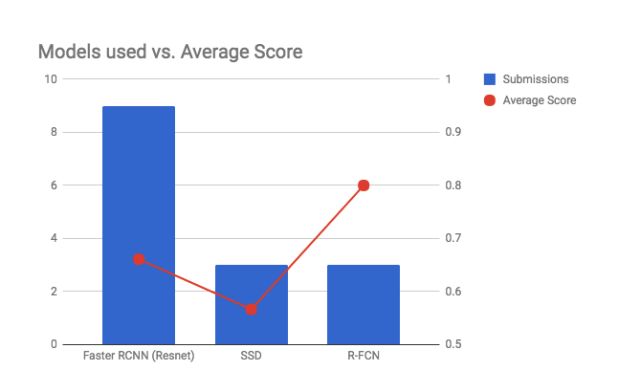
大多数参赛者使用更快的RCNN作为他们的模型,其得分范围从0.5到0.77。但是明显的获胜者是Deformable R-FCN,平均得分为0.8。
最终,来自中国上海复旦大学的研究者获得了最高分,拿下冠军。
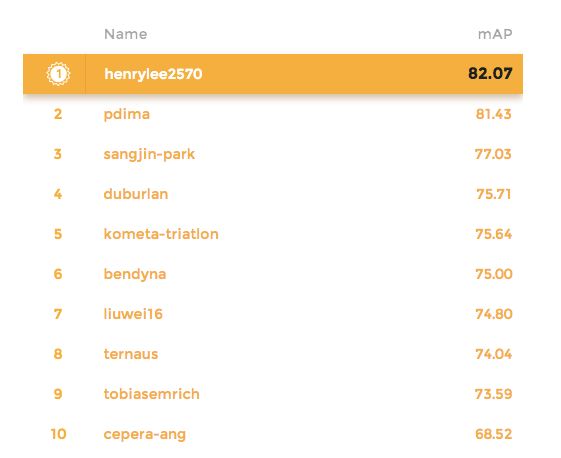
前三名经验分享
第一名:Hengduo Li (Henry)

“现在是复旦大学本科生。我对计算机视觉感兴趣,关注了人体检测、物体检测等课题。我希望在未来的研究中继续研究这些主题,帮助现实生活应用,就像Nexar在做的一样:) ”
“我使用具有soft-NMS的Deformable R-FCN参加了这次挑战。使用了从ImageNet上用ResNet-50预训练的一个单模型。
核心要点:
1. Deformable Convnets和R-FCN功能强大,在ImageNet和COCO上获得了最先进的性能。我都不需要使用集成。如果我使用集成,和ResNet-101一起,加上更多trick,性能可以更好。
2. 水平翻转训练图像效果很好。我将所有训练数据水平翻转。这已经是一个非常普遍的数据增强/扩充方法了。
3. 小尺寸锚点。查看训练数据,我看到很多小的边界框,于是决定添加更多的小尺寸锚点。结果证明这样做效果很好。
4. 多尺度测试。这一般会带来大约2%的性能提升。我在720训练,在(600,720,1000)测试,获得了性能提升。
第二名:Dmytro Poplavskiy

年龄:38岁
居住地:澳大利亚布里斯班
教育:无线电物理与电子学硕士学位
自我介绍:我是一名最近对机器学习感兴趣的软件工程师。
本质上我的源代码组成如下:
1)基于Faster-RCNN的Deformable ConvNets,代码(https://github.com/msracver/Deformable-ConvNets)。我进行了一些小的修改,包括读取Nexar数据集的适配器,禁用非最大抑制阶段的选项,以及能够运行多个预测的小脚本。
2)一些用于准备数据集扩充和转换结果的实用程序脚本。
3)实施定制的灵活非最大抑制阶段(non maximum suppression stage)。
核心要点
我决定使用Faster-RCNN或R-FCN的Deformable ConvNets修改。
由于比赛时可以修改/标注训练数据集,我首先检查了训练数据的改进情况。
标签的规模和性质都不适合用手工进行重新打标签。
我将训练数据集分为两个,在每个上都训练了R-FCN模型。
我比较了两个分开数据集预测与原始标签预测的结果,发现了训练集中缺少的边界框。
几乎在所有情况下,我发现这都是标签缺失导致的。
我按照缺失的边界框数量对训练集中的图像进行排序,并重新标记了其中15-20%边界框缺失最多的图像,最坏情况下图像中有多达8辆车没有边界框。
由于模型生成的边界框相当准确,所以我只需要选择将哪些预测边界框添加到训练数据集中,所以过程还是相对较快。
我决定使用Faster-RCNN,因为经过一个快速测试,它比R-FCN实现了稍微更好的结果。
我计划尝试这篇论文(https://arxiv.org/abs/1704.04503)中描述的Soft NMS方法
我扩展了Soft NMS的原始概念,不仅调整置信区间,还要调整边界框的位置。
我在NMS阶段之前检查了Faster-RCNN的结果,发现它经常产生一些具有相似置信区间和位置的封闭边界框。
只保留置信区间最上层结果,抛弃其他所有的结果,听起来有点浪费,尤其是当结合使用多个模型或测试时间扩充以后。
所以,我的 Flexible NMS方法如下:
1)对于置信度最高的边界框,将其与iou> 0.8的所有其他类似框组合,框的位置作为具有置信度权重的边界框位置的加权平均值。
2)对于组合框的置信度,我使用conf = sum(最多N个边界框)/ N
。这对组合多个结果特别有用,我还想惩罚那些只有单个网络找到的一个结果(相比更多网络/边界框预测的置信度更高的结果)。
我使用N == 4 ×预测数的组合。
3)对于与当前框重叠的所有其他框,我按照原始 Soft NMS文章中的所述调整了置信度。
总体来说,这种方法让我从单个模型、默认NMS得分~0.72–0.73,增加到0.77-0.78,后面是使用 Flexible NMS从2个不同模型组合大约6个预测的结果。
我最终提交的结果,训练了3个Faster RCNN模型,对于所有图像的每个预测,翻转和±20%调整大小。
我将所有结果结合,禁用原始NMS,并通过Flexible NMS进行后处理。
第三名:Sang Jin Park

年龄:40岁
居住地:首尔,韩国
教育:物理/计算机科学本科 KAIST
核心要点
“为了避免过拟合,我使用了Dropout层以及数据扩充,比如水平翻转、旋转和缩放。”
“至于工具,在尝试单纯使用Tensorflow之后,我开始将Keras和Python notebook一起用,这有助于实验和可视化。”
“裁减——我有一种感觉,裁剪下半部分的画面可能有助于训练,但看来这实际上减少了学习。”
“我花了好几个小时处理亚马逊云GPU帮助我进行实验,但最终,由于模型尺寸必须保持较小,我最终使用自己的笔记本电脑上进行实验,而且速度很快。”