用于TensorFlow对象检测的开放图像数据集

数据是建立深度学习模型时要考虑的最强支柱之一。数据越精确,模型就越有经验。
要训练深度学习模型,你需要大量数据,你可能需要创建自己的数据,或者你可以使用互联网上的公共数据集,如MS COCO、ImageNet、Open Images等。
有时,这些数据集遵循不同的格式,而你想要训练的模型遵循另一种格式。
当数据非常大时,使模型能够使用数据变得很麻烦。
物体检测是计算机视觉的一个分支,你可以在图像中定位特定的物体。我使用Tensorflow对象检测API创建自定义对象检测器。
为了创建检测器,从OpenImagesV4数据集创建了数据。该数据集共有600个类和170万张图像,分为训练集、验证集和测试集。它已经更新到V6,本文决定使用V4。
要训练Tensorflow对象检测模型,你需要创建TFRecords,它使用以下内容:
1.图像
2.图像注释
打开的图像同时包含图像和它们的注释。但是,所有注释都集中在一个文件中,当你需要特定类的数据时,这会变得很笨拙。
为了处理这个问题,决定将数据转换为PASCAL VOC格式。现在,你可能会问什么是PASCAL VOC?简而言之,PASCAL VOC格式为每个图像创建了一个XML文件,该文件包含图像中每个对象的边界框坐标。
如果你想了解更多关于PASCAL VOC的信息,这里有一个参考资料:https://towardsdatascience.com/coco-data-format-for-object-detection-a4c5eaf518c5#:~:text=Pascal%20VOC%20is%20an%20XML,for%20training%2C%20testing%20and%20validation.。
现在说的够多了,让我们看看实际怎么做吧!
这是github repo的笔记本:https://github.com/horizons-ml/OIDv4_annotation_tool/blob/master/OIDv4_Dataset_Download_Processing.ipynb。
建议使用GoogleColab,因为这些工具可能需要的一些文件很大,对于将来的用例可能没有用处。
这个工具可以让我们下载特定种类和特定数量的图像。通过克隆repo下载该工具:https://github.com/EscVM/OIDv4_ToolKi。
下载后,你将找到classes.txt文件。这里你需要提到要收集其数据的类名。你可以在这里找到类的列表:https://storage.googleapis.com/openimages/2018_04/bbox_labels_600_hierarchy_visualizer/circle.html。例如,以“手机”类和98张图片为例。
粘贴以下代码:
python OIDv4_ToolKit/main.py downloader --classes OIDv4_ToolKit/classes.txt --type_csv train --limit 98当你第一次运行脚本时,工具可能会要求你下载一些文件,如果允许的话。下面是提示的样子

该工具创建目录,并再次为这些目录中的每个类创建子目录。
现在,让我们使用以下脚本查看每个类的文件数:
import os
dir = '/content/OID/Dataset/train/'
for folder in os.listdir(dir):
print('Number for files in '+folder+'=',len(os.listdir(dir+folder)))输出以查看目录中的文件:
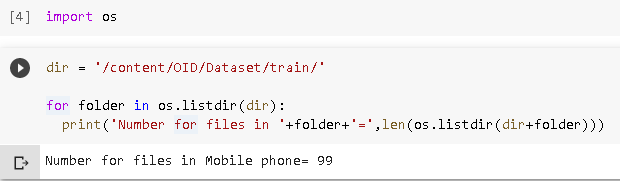
有98张图片并且它创建一个名为“Label”的文件夹,其中包含每个图像的注释。
让我们看看文件夹“Label”包含什么:
import os
dir = '/content/OID/Dataset/train/'
for folder in os.listdir(dir):
for file in os.listdir(dir+folder+'/Label')[:5]:
print(dir+folder+'/Label'+'/'+file)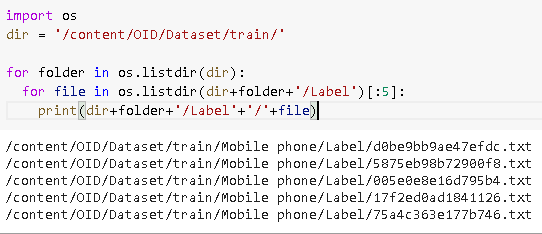
我们每个图像都有一个注释文件。但是注释不符合PASCAL VOC格式。因此,我们需要另一种工具,可以将这些注释转换为所需的格式。
这个工具为我们做最后的工作。克隆它。稍微修改了这个工具,用于名称中包含一个单词以上的类,你可以在这个repo中找到它们:https://github.com/horizons-ml/OIDv4_annotation_tool/blob/master/OIDv4_to_VOC.py。
完成后,运行以下命令转换注释文件:
from subprocess import check_output
source = '/content/OID/Dataset/train'
for folder in os.listdir(source):
target = f'{source}/{folder}'
output = check_output(["python", '/content/OIDv4_annotation_tool/OIDv4_to_VOC.py', "--sourcepath" , f"{source}/{folder}", "--dest_path", f"{target}"])这里,sourcepath是每个类的“Label”文件夹的位置,dest_path是存储XML注释的位置。
一旦创建了XML注释,我们就不再需要txt注释了。让我们删除它们:
import shutil
dir = '/content/OID/Dataset/train/'
for folder in os.listdir(dir):
shutil.rmtree(f'/{dir}/{folder}/Label')这将删除所有类目录中名为“Label”的所有文件夹。
现在你有了你的过滤数据集!
提示:数据集准备好后,使用labelImg验证注释。对象有时可能被错误地注释。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
