时间序列分析工具箱—— h2o + timetk

作者:徐瑞龙,量化分析师,R语言中文社区专栏作者
博客专栏:
https://www.cnblogs.com/xuruilong100
本文翻译自《Demo Week: Time Series Machine Learning with h2o and timetk》
原文链接:https://www.business-science.io/code-tools/2017/10/28/demo_week_h2o.html
文字和代码略有删改
h2o 的用途
h2o 包是 H2O.ai 提供的产品,包含许多先进的机器学习算法,表现指标和辅助函数,使机器学习功能强大而且容易使用。h2o 的主要优点之一是它可以部署在集群上(今天不会讨论),从 R 的角度来看,有四个主要用途:
数据操作:拼接、分组、旋转、传输、拆分成训练 / 测试 / 验证集,等等。
机器学习算法:包含非常复杂的监督和非监督学习算法。监督学习算法包括深度学习(神经网络)、随机森林、广义线性模型、梯度增强机、朴素贝叶斯分析、模型堆叠集成和 xgboost;无监督算法包括广义低秩模型、k 均值模型和 PCA;还有 Word2vec 用于文本分析。最新的稳定版本还有 AutoML——自动机器学习,我们将在这篇文章中看到这个非常酷的功能!
辅助机器学习功能:表现分析和超参数网格搜索。
产品、MapReduce 和 云:Java 环境下进行产品化;使用 Hadoop / Spark(Sparkling Water)进行集群部署;在云环境(Azure、AWS、Databricks 等)中部署。
我们将讨论如何将 h2o 用作时间序列机器学习的一种高级算法。我们将在本地使用 h2o,在先前关于 timetk 和 sweep 的教程中使用的数据集(beer_sales_tbl)上开发一个高精度的时间序列模型。这是一个监督学习的回归问题。
加载包
我们需要三个包:
h2o:机器学习算法包tidyquant:用于获取数据和加载tidyverse系列工具timetk:R 中的时间序列工具箱
安装 h2o
推荐在 ubuntu 环境下安装最新稳定版 h2o。
加载包
# Load libraries library(h2o) # Awesome ML Library library(timetk) # Toolkit for working with time series in R library(tidyquant) # Loads tidyverse, financial pkgs, used to get data
数据
我们使用 tidyquant 的函数 tq_get(),获取 FRED 的数据——啤酒、红酒和蒸馏酒销售。
# Beer, Wine, Distilled Alcoholic Beverages, in Millions USD beer_sales_tbl <- tq_get( "S4248SM144NCEN", get = "economic.data", from = "2010-01-01", to = "2017-10-27") beer_sales_tbl
## # A tibble: 92 x 2 ## date price ##
可视化是一个好主意,我们要知道我们正在使用的是什么数据,这对于时间序列分析和预测尤为重要,并且最好将数据分成训练、测试和验证集。
# Plot Beer Sales with train, validation, and test sets shown beer_sales_tbl %>% ggplot(aes(date, price)) + # Train Region annotate( "text", x = ymd("2012-01-01"), y = 7000, color = palette_light()[[1]], label = "Train Region") + # Validation Region geom_rect( xmin = as.numeric(ymd("2016-01-01")), xmax = as.numeric(ymd("2016-12-31")), ymin = 0, ymax = Inf, alpha = 0.02, fill = palette_light()[[3]]) + annotate( "text", x = ymd("2016-07-01"), y = 7000, color = palette_light()[[1]], label = "Validation\nRegion") + # Test Region geom_rect( xmin = as.numeric(ymd("2017-01-01")), xmax = as.numeric(ymd("2017-08-31")), ymin = 0, ymax = Inf, alpha = 0.02, fill = palette_light()[[4]]) + annotate( "text", x = ymd("2017-05-01"), y = 7000, color = palette_light()[[1]], label = "Test\nRegion") + # Data geom_line(col = palette_light()[1]) + geom_point(col = palette_light()[1]) + geom_ma(ma_fun = SMA, n = 12, size = 1) + # Aesthetics theme_tq() + scale_x_date( date_breaks = "1 year", date_labels = "%Y") + labs(title = "Beer Sales: 2007 through 2017", subtitle = "Train, Validation, and Test Sets Shown")
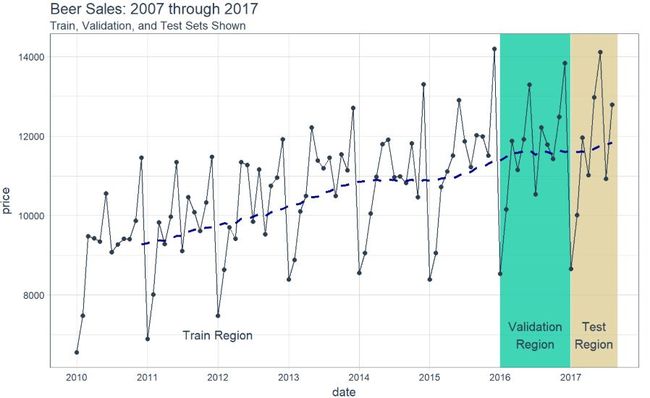
现在我们对数据有了直观的认识,让我们继续吧。
教程:h2o + timetk,时间序列机器学习
我们的时间序列机器学习项目遵循的工作流与之前 timetk + 线性回归文章中的类似。但是,这次我们将用 h2o.autoML() 替换 lm() 函数以获得更高的准确性。
时间序列机器学习
时间序列机器学习是预测时间序列数据的好方法,在开始之前,先明确教程的两个关键问题:
关键洞察:时间序列签名——将时间戳信息逐列扩展,成为特征集,用于执行机器学习算法。
目标:我们将用时间序列签名预测未来 8 个月的数据,并和先前教程中出现的两种方法(即
timetk+lm()和sweep+auto.arima())的预测结果作对比。
下面,我们将经历一遍执行时间序列机器学习的工作流。
STEP 0:检查数据
作为分析的起点,先用 glimpse() 打印出 beer_sales_tbl,获得数据的第一印象。
# Starting point beer_sales_tbl %>% glimpse()
## Observations: 92 ## Variables: 2 ## $ date
STEP 1:扩充时间序列签名
tk_augment_timeseries_signature() 函数将时间戳信息逐列扩展成机器学习所用的特征集,将时间序列信息列添加到原始数据框。再次使用 glimpse() 进行快速检查。现在有了 30 个特征,有些特征很重要,但并非所有特征都重要。
# Augment (adds data frame columns) beer_sales_tbl_aug <- beer_sales_tbl %>% tk_augment_timeseries_signature() beer_sales_tbl_aug %>% glimpse()
## Observations: 92 ## Variables: 30 ## $ date
STEP 2:为 h2o 准备数据
我们需要以 h2o 的格式准备数据。首先,让我们删除任何不必要的列,如日期列或存在缺失值的列,并将有序类型的数据更改为普通因子。我们推荐用 dplyr 操作这些步骤。
beer_sales_tbl_clean <- beer_sales_tbl_aug %>% select_if(~ !is.Date(.)) %>% select_if(~ !any(is.na(.))) %>% mutate_if(is.ordered, ~ as.character(.) %>% as.factor) beer_sales_tbl_clean %>% glimpse()
## Observations: 92 ## Variables: 28 ## $ price
让我们在可视化之前按照时间范围将数据分成训练、验证和测试集。
# Split into training, validation and test sets train_tbl <- beer_sales_tbl_clean %>% filter(year < 2016) valid_tbl <- beer_sales_tbl_clean %>% filter(year == 2016) test_tbl <- beer_sales_tbl_clean %>% filter(year == 2017)
STEP 3:h2o 模型
首先,启动 h2o。这将初始化 h2o 使用的 java 虚拟机。
h2o.init()# Fire up h2o
## Connection successful! ## ## R is connected to the H2O cluster: ## H2O cluster uptime: 46 minutes 4 seconds ## H2O cluster version: 3.14.0.3 ## H2O cluster version age: 1 month and 5 days ## H2O cluster name: H2O_started_from_R_mdancho_pcs046 ## H2O cluster total nodes: 1 ## H2O cluster total memory: 3.51 GB ## H2O cluster total cores: 4 ## H2O cluster allowed cores: 4 ## H2O cluster healthy: TRUE ## H2O Connection ip: localhost ## H2O Connection port: 54321 ## H2O Connection proxy: NA ## H2O Internal Security: FALSE ## H2O API Extensions: Algos, AutoML, Core V3, Core V4 ## R Version: R version 3.4.1 (2017-06-30)
h2o.no_progress() # Turn off progress bars
将数据转成 H2OFrame 对象,使得 h2o 包可以读取。
# Convert to H2OFrame objects train_h2o <- as.h2o(train_tbl) valid_h2o <- as.h2o(valid_tbl) test_h2o <- as.h2o(test_tbl)
为目标和预测变量命名。
# Set names for h2o y <- "price" x <- setdiff(names(train_h2o), y)
我们将使用 h2o.automl,在数据上尝试任何回归模型。
x = x:特征列的名字y = y:目标列的名字training_frame = train_h2o:训练集,包括 2010 - 2016 年的数据validation_frame = valid_h2o:验证集,包括 2016 年的数据,用于避免模型的过度拟合leaderboard_frame = test_h2o:模型基于测试集上 MAE 的表现排序max_runtime_secs = 60:设置这个参数用于加速h2o模型计算。算法背后有大量复杂模型需要计算,所以我们以牺牲精度为代价,保证模型可以正常运转。stopping_metric = "deviance":把偏离度作为停止指标,这可以改善结果的 MAPE。
# linear regression model used, but can use any model automl_models_h2o <- h2o.automl( x = x, y = y, training_frame = train_h2o, validation_frame = valid_h2o, leaderboard_frame = test_h2o, max_runtime_secs = 60, stopping_metric = "deviance")
接着,提取主模型。
# Extract leader model automl_leader <- automl_models_h2o@leader
STEP 4:预测
使用 h2o.predict() 在测试数据上产生预测。
pred_h2o <- h2o.predict( automl_leader, newdata = test_h2o)
STEP 5:评估表现
有几种方法可以评估模型表现,这里,将通过简单的方法,即 h2o.performance()。这产生了预设值,这些预设值通常用于比较回归模型,包括均方根误差(RMSE)和平均绝对误差(MAE)。
h2o.performance( automl_leader, newdata = test_h2o)
## H2ORegressionMetrics: gbm ## ## MSE: 340918.3 ## RMSE: 583.8821 ## MAE: 467.8388 ## RMSLE: 0.04844583 ## Mean Residual Deviance : 340918.3
我们偏好的评估指标是平均绝对百分比误差(MAPE),未包括在上面。但是,我们可以轻易计算出来。我们可以查看测试集上的误差(实际值 vs 预测值)。
# Investigate test error error_tbl <- beer_sales_tbl %>% filter(lubridate::year(date) == 2017) %>% add_column( pred = pred_h2o %>% as.tibble() %>% pull(predict)) %>% rename(actual = price) %>% mutate( error = actual - pred, error_pct = error / actual) error_tbl
## # A tibble: 8 x 5 ## date actual pred error error_pct ##
为了比较,我们计算了一些残差度量指标。
error_tbl %>% summarise( me = mean(error), rmse = mean(error^2)^0.5, mae = mean(abs(error)), mape = mean(abs(error_pct)), mpe = mean(error_pct)) %>% glimpse()
## Observations: 1 ## Variables: 5 ## $ me
STEP 6:可视化预测结果
最后,可视化我们得到的预测结果。
beer_sales_tbl %>% ggplot(aes(x = date, y = price)) + # Data - Spooky Orange geom_point(col = palette_light()[1]) + geom_line(col = palette_light()[1]) + geom_ma( n = 12) + # Predictions - Spooky Purple geom_point( aes(y = pred), col = palette_light()[2], data = error_tbl) + geom_line( aes(y = pred), col = palette_light()[2], data = error_tbl) + # Aesthetics theme_tq() + labs( title = "Beer Sales Forecast: h2o + timetk", subtitle = "H2O had highest accuracy, MAPE = 3.9%")
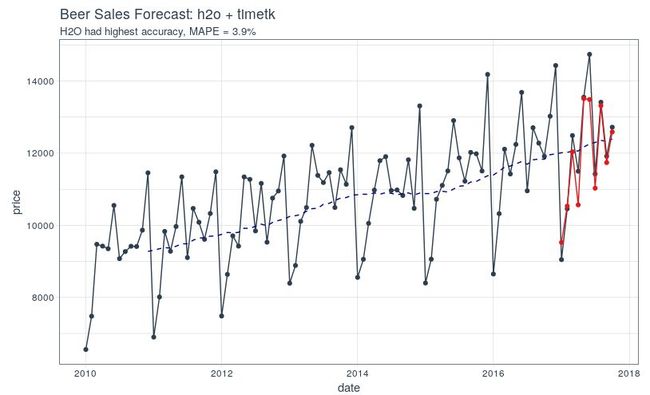
最终的胜利者是...
h2o + timetk 的 MAPE 优于先前两个教程中的方法:
timetk + h2o:MAPE = 3.9%(本教程)
timetk + linear regression:MAPE = 4.3%(时间序列分析工具箱——timetk)
sweep + ARIMA:MAPE = 4.3%(时间序列分析工具箱——sweep)
感兴趣的读者要问一个问题:对所有三种不同方法的预测进行平均时,准确度会发生什么变化?
请注意,时间序列机器学习的准确性可能并不总是优于 ARIMA 和其他预测技术,包括那些由 prophet(Facebook 开发的预测工具)和 GARCH 方法实现的技术。数据科学家有责任测试不同的方法并为工作选择合适的工具。
往期回顾
时间序列分析工具箱——timetk
时间序列分析工具箱——tidyquant
时间序列分析工具箱——sweep
时间序列分析工具箱——tibbletime
基于 Keras 用深度学习预测时间序列
基于 Keras 用 LSTM 网络做时间序列预测
时间序列深度学习:状态 LSTM 模型预测太阳黑子(一)
时间序列深度学习:状态 LSTM 模型预测太阳黑子(二)
时间序列深度学习:seq2seq 模型预测太阳黑子
R中的设计模式
理解 LSTM 及其图示

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法