【读点论文】Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
Abstract
-
由于复杂的注意力机制和模型设计,大多数现有的视觉transformer(ViT)在现实的工业部署场景(如TensorRT和CoreML)中不能像卷积神经网络(CNN)那样高效地执行。这提出了一个明显的挑战:视觉神经网络能否设计得像CNN一样快速推断,并像ViT一样强大?
-
在这些工作中,提出了一种用于在现实工业场景中高效部署的下一代视觉transformer,即next ViT,从延迟/准确性权衡的角度来看,它主导了CNN和ViT。下一个卷积块(NCB)和下一个transformer块(NTB)分别被开发用于利用部署友好机制捕获本地和全局信息。
-
然后,下一个混合策略(NHS)被设计为以高效的混合模式来堆叠NCB和NTB,从而提高各种下游任务的性能。大量实验表明,Next ViT在各种视觉任务的延迟/准确性权衡方面显著优于现有的CNN、ViT和CNN Transformer混合架构。
-
在TensorRT上,Next ViT在COCO检测上超过ResNet 5.5 mAP(从40.4到45.9),在ADE20K分割上超过7.7%mIoU(从38.8%到46.5%),延迟时间相似。同时,它实现了与CSWin相当的性能,而推理速度加快了3.6倍。在CoreML上,Next ViT在COCO检测上超过EfficientFormer 4.6 mAP(从42.6到47.2),在ADE20K分割上超过3.5%mIoU(从45.1%到48.6%)。
-
本文的代码和模型公开于: https://github.com/bytedance/Next-ViT
-
来自字节跳动的研究者提出了一种能在现实工业场景中有效部署的下一代视觉 Transformer,即 Next-ViT。Next-ViT 能像 CNN 一样快速推断,并有 ViT 一样强大的性能。
-
Next-ViT 的研究团队通过开发新型的卷积块(NCB)和 Transformer 块(NTB),部署了友好的机制来捕获局部和全局信息。然后,该研究提出了一种新型混合策略 NHS,旨在以高效的混合范式堆叠 NCB 和 NTB,从而提高各种下游任务的性能。
Introduction
-
由于复杂的注意力机制和模型设计,大多数现有的视觉 Transformer(ViT)在现实的工业部署场景中不能像卷积神经网络(CNN)那样高效地执行。这就带来了一个问题:视觉神经网络能否像 CNN 一样快速推断并像 ViT 一样强大?
-
最近,视觉transformer(ViT)在工业界和学术界受到了越来越多的关注,并在各种计算机视觉任务中取得了很大的成功,如图像分类、对象检测、语义分割等。然而,从真实世界部署的角度来看,CNN仍然主导着视觉任务,因为ViT通常比经典CNN(例如ResNets)慢得多。
-
有一些因素限制了Transformer模型的推理速度,包括与多头自我注意(MHSA)机制的令牌长度有关的二次复杂性、不可折叠的LayerNorm和GELU层、复杂的模型设计导致频繁的内存访问和复制等。
-
许多作品都在努力将ViT从高延迟困境中解放出来。例如,Swin Transformer和PVT试图设计更有效的空间注意力机制,以缓解MHSA二次增长的计算复杂性。其他人[Coatnet,Efficientformer,Mobilevit]考虑将有效的卷积块和强大的Transformer块相结合,以设计CNN-Transformer混合架构,从而在准确性和延迟之间获得更好的折衷。
-
巧合的是,几乎所有现有的混合架构都在浅级采用卷积块,而在最后几级只堆叠Transformer块。然而,本文观察到,这种混合策略很容易导致下游任务(例如分割和检测)的性能饱和。此外,本文发现现有工作中的卷积块和transformer块不能同时具有效率和性能的特性。尽管与Vision Transformer相比,精度-延迟权衡得到了改善,但现有混合架构的总体性能仍远不能令人满意。
-
为了解决上述问题,本工作开发了三个重要组件来设计高效的视觉transformer网络。首先,介绍了下一个卷积块(NCB),它能够通过一种新的部署友好型多头卷积注意力(MHCA)熟练地捕获视觉数据中的短期依赖信息。
-
其次,构建了下一个transformer块(NTB),NTB不仅是捕获长期依赖信息的专家,而且还可以作为一个轻量级的高低频信号混频器来增强建模能力。最后,设计了下一个混合策略(NHS),以在每个阶段以新的混合模式堆叠NCB和NTB,这大大减少了Transformer块的比例,并在各种下游任务中保持了视觉Transformer网络的高精度。
-
基于以上提出的方法,本文提出了用于现实工业部署场景的下一代视觉transformer(缩写为next ViT)。在本文中,为了进行公平的比较,提供了一种将特定硬件上的延迟视为直接效率反馈的视图。TensorRT和CoreML分别代表服务器端和移动端设备的通用和易于部署的解决方案,有助于提供令人信服的面向硬件的性能指导。通过这种直接和准确的指导,重新绘制了下图中几种现有竞争模型的准确性和延迟权衡图。
-
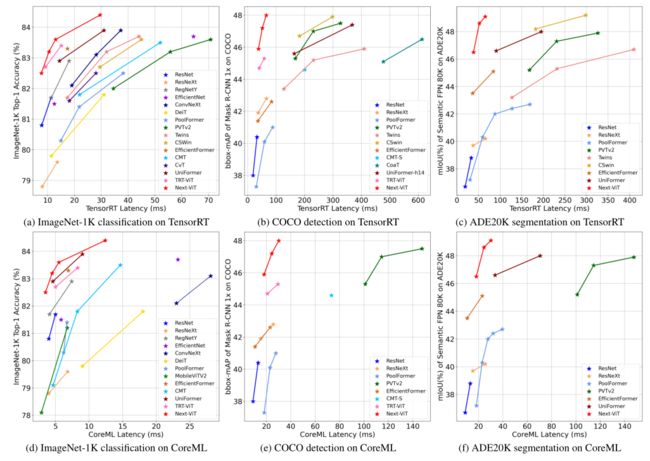
-
Next-ViT和高效网络之间的准确性-延迟权衡比较。
-
-
如上图(a)(d)所示,Next ViT在ImageNet-1K分类任务中实现了最佳的延迟/准确性权衡。更重要的是,Next ViT在下游任务上显示出更显著的延迟/准确性权衡优势。如上图(b)(c)所示,在TensorRT上,Next ViT在COCO检测方面的表现优于ResNet 5.5 mAP(从40.4到45.9),在ADE20K分割方面的表现为7.7%mIoU(从38.8%到46.5%)。
-
Next ViT的性能与CSWin相当,而推理速度提高了3.6倍。如上图(e)(f)所示,在CoreML上,Next ViT在COCO检测上超过了EfficientFormer 4.6 mAP(从42.6到47.2),在ADE20K分割上超过了3.5%mIoU(从45.1%到48.6%)。
-
本文的主要贡献总结如下:
-
本文开发了强大的卷积块和变压器块,即NCB和NTB,具有部署友好的机制。接下来,ViT将NCB和NTB叠加在一起,构建先进的CNNtransformer混合架构。
-
本文从一个新的视角设计了一个创新的CNN Transformer混合策略,以提高性能和效率。
-
本文介绍Next ViT,一个强大的视觉transformer架构家族。大量实验证明了Next ViT的优势。它在TensorRT和CoreML上实现了图像分类、对象检测和语义分割的SOTA延迟/准确性权衡。
-
Related Work
Convolutional Networks.
- 在过去的十年中,卷积神经网络(CNN)在各种计算机视觉任务中主导了视觉架构,包括图像分类、对象检测和语义分割。ResNet使用残差连接来消除网络退化,确保网络构建得更深,并能够捕获高级抽象。DenseNet交替增强特征重用,并通过密集连接连接特征图。MobileNets引入深度卷积和点卷积来构建具有小内存和低延迟的模型。ShuffleNet采用分组逐点卷积和信道混洗来进一步降低计算成本。ShuffleNetv2提出,网络架构设计应考虑速度等直接指标,而不是FLOP等间接指标。ConvNeXt审查了视觉transformer的设计,并提出了一种纯CNN模型,该模型可以在多个计算机视觉基准上与SOTA分层视觉transformer进行竞争,同时保持标准CNN的简单性和效率。
ResNet提出的BottleNeck块因其固有的归纳偏差和部署而在视觉神经网络中长期占据主导地位。大多数硬件平台的友好特性。包括多头自注意力(MHSA)机制其复杂度与Token长度呈二次关系、不可融合的LayerNorm和GELU层、复杂模型设计导致频繁的内存访问和复制等因素限制了ViTs模型的推理速度。
Vision Transformers.
- Transformer首先在自然语言处理(NLP)领域提出。ViT将图像分割为多个块,并将这些块视为文字来进行自我关注,这表明Transformer在各种视觉任务中也取得了令人印象深刻的表现。DeiT介绍了一种针对transformer的师生策略。T2T ViT引入了一种新的令牌到令牌(T2T)过程,以逐步将图像令牌化为令牌,并在结构上聚合令牌。Swin Transformer提出了一种通用的Transformer主干,该主干构建分层特征图,并具有与图像大小线性的计算复杂度。PiT在ViT中加入了池化层,并通过大量实验表明,这些优势可以很好地与ViT协调。如今,研究人员更加注重效率,包括高效的自我关注、训练策略、金字塔设计等。
Hybrid Models.
- 最近的工作[Cmt: Convolutional neural networks meet vision transformers,Effi-
cientformer,Mobilevit,Bottleneck transformers for visual recognition,Cvt,Understanding the robustness in vision transformers]表明,将卷积和Transformer结合为混合架构有助于吸收两种架构的优势。BoTNet在ResNet的最后三个瓶颈块中用全局自我关注替换空间卷积。CvT在自我注意前面引入了深度和点卷积。CMT提出了一种新的基于transformer的混合网络,它利用transformer来捕获长距离依赖关系,并利用CNN来建模局部特征。在MobileViT中,介绍了一种用于移动设备的轻型通用视觉转换器。Mobile Former结合所提出的轻量级交叉注意力来建模桥梁,这不仅计算效率高,而且具有更大的表示能力。EfficientFormer符合尺寸一致的设计,能够平滑地利用硬件友好的4D MetaBlock和功能强大的3D MHSA块。在本文中,设计了一系列更适合实际工业场景的Next ViT模型。
Methods
- 在本节中,首先演示了建议的Next ViT的概述。然后,讨论了Next ViT中的一些核心设计,包括Next Convolution Block(NCB)、Next Transformer Block(NTB)和Next Hybrid Strategy(NHS)。此外,还提供了不同模型大小的架构规范。
Overview
-
展示了如下图所示的Next ViT。按照惯例,Next ViT遵循分层金字塔结构,每个阶段都配备了补丁嵌入层和一系列卷积或Transformer块。空间分辨率将逐渐降低32×,而通道尺寸将在不同阶段扩展。
-

-
左栏是Next ViT的整体分层架构。中间列是下一个卷积块(NCB)和下一个变压器块(NTB)。右栏是多头卷积注意力(MHCA)、高效多头自我注意力(E-MHSA)和优化的MLP模块的详细可视化。
-
Next-ViT 遵循分层金字塔架构,在每个阶段配备一个 patch 嵌入层和一系列卷积或 Transformer 块。空间分辨率将逐步降低为原来的 1/32,而通道维度将按阶段扩展。
-
-
在本章中,首先深入设计信息交互的核心块,并分别开发强大的NCB和NTB来建模视觉数据中的短期和长期依赖关系。局部和全局信息的融合也在NTB中执行,这进一步增强了建模能力。最后,系统地研究了卷积和Transformer块的集成方式。为了克服现有方法的固有缺陷,引入了下一个混合策略,该策略将创新的NCB和NTB叠加在一起,以构建先进的CNN与transformer混合架构。
-
研究者首先深入设计了信息交互的核心模块,并分别开发强大的 NCB 和 NTB 来模拟视觉数据中的短期和长期依赖关系。NTB 中还进行了局部和全局信息的融合,进一步提高了建模能力。最后,为了克服现有方法的固有缺陷,该研究系统地研究了卷积和 Transformer 块的集成方式,提出了 NHS 策略,来堆叠 NCB 和 NTB 构建新型 CNN-Transformer 混合架构。
Next Convolution Block (NCB)
-
为了展示所提出的NCB的优越性,首先回顾了卷积块和transformer块的一些经典结构设计,如下图所示。ResNet提出的瓶颈块由于其固有的电感偏差和大多数硬件平台中的部署友好特性,在视觉神经网络中长期占据主导地位。
-
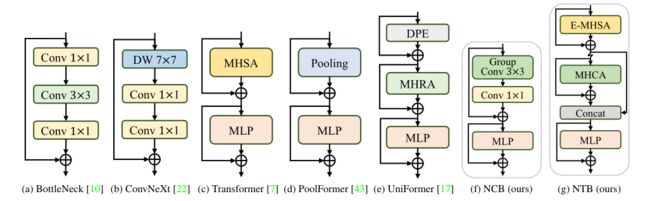
-
不同的基于transformer和基于卷积的块的比较。
-
-
不幸的是,与transformer块相比,瓶颈块的有效性不足。ConvNeXt块通过模仿transformer块的设计使瓶颈块现代化。虽然ConvNeXt块部分提高了网络性能,但其在TensorRT/CoreML上的推理速度受到效率低下的组件的严重限制,如7×7深度卷积、LayerNorm和GELU。
-
Transformer块在各种视觉任务中取得了优异的成绩,其内在优势由MetaFormer的范例和基于注意力的令牌混合器模块共同赋予。然而,Transformer块的推理速度比BottleNeck块慢得多,因为其复杂的注意力机制,这在大多数现实的工业场景中是无法承受的。
-
为了克服上述块的缺点,引入了下一个卷积块(NCB),它保持了瓶颈块的部署优势,同时获得了transformer块的突出性能。如上图(f)所示,NCB遵循MetaFormer的一般架构,该架构被验证为transformer块的关键。同时,一个高效的基于注意力的令牌混合器也同样重要。本文设计了一种新型的多头卷积注意力(MHCA),作为一种具有部署友好卷积操作的高效令牌混合器。最后,在MetaFormer的范式中构建了具有MHCA和MLP层的NCB。建议的NCB可以制定如下:
-
z ˉ l = M H C A ( z l − 1 ) + z l − 1 , ( 1 ) z l = M L P ( z ˉ l ) + z l ˉ \bar{z}^l=MHCA(z^{l-1})+z^{l-1},(1)\\ z^l=MLP(\bar{z}^l)+\bar{z^l} zˉl=MHCA(zl−1)+zl−1,(1)zl=MLP(zˉl)+zlˉ
-
其中zl−1表示来自l− 1的输入块、~zl和zl是MHCA和l NCB的输出。将在下一节详细介绍MHCA。
-
-
Multi-Head Convolutional Attention (MHCA)
-
为了将现有的基于注意力的token mixer从高延迟困境中解放出来,设计了一种具有高效卷积运算的新型注意力机制,即卷积注意力(CA),以提高推理速度。
-
同时,受MHSA中有效的多头设计的启发,利用多头范式构建了本文的卷积注意力,该范式共同关注来自不同位置的不同表示子空间的信息,以实现有效的局部表示学习。本文提出的的多头卷积注意力(MHCA)的定义可概括如下:
-
M H C A ( z ) = C o n c a t ( C A 1 ( z 1 ) , C A 2 ( z 2 ) , . . . C A h ( z h ) ) W P , ( 2 ) MHCA(z)=Concat(CA_1(z_1),CA_2(z_2),...CA_h(z_h))W^P,(2) MHCA(z)=Concat(CA1(z1),CA2(z2),...CAh(zh))WP,(2)
-
这里,MHCA从h个并行表示子空间捕获信息。z=[z1,z2,…,zh]表示在通道维度上将输入特征z分成多头部形式。为了促进多个头之间的信息交互,还为MHCA配备了投影层(WP)。CA是单头卷积注意力,可定义为:
-
C A ( z ) = O ( W , ( T m , T n ) ) , w h e r e T { m , n } ∈ z , ( 3 ) CA(z)=O(W,(T_m,T_n)),where~T_{\{m,n\}}\in z,(3) CA(z)=O(W,(Tm,Tn)),where T{m,n}∈z,(3)
-
其中Tm和Tn是输入特征z中的相邻标记。O是具有可训练参数W和输入标记T{m,n}的内积运算。CA能够通过迭代优化可训练参数W来学习局部感受野中不同标记之间的亲和力。具体而言,MHCA的实现是通过组卷积(多头卷积)和点卷积来实现的,如上图(f)所示。为了在TensorRT上使用各种数据类型实现快速推理速度,将所有MHCA中的头部亮度统一设置为32。此外,在NCB中采用了高效的BatchNorm(BN)和ReLU激活函数,而不是传统Transformer块中的LayerNorm(LN)和GELU,这进一步加快了推理速度。消融研究中的实验结果表明,NCB与现有块(如瓶颈块、ConvNext块、LSA块等)相比具有优越性。
-
Next Transformer Block (NTB)
-
尽管通过NCB有效地了解了局部特征代表性,但获取全局信息的问题亟待解决。transformer块具有很强的捕捉低频信号的能力,这些低频信号提供了全局信息(例如全局形状和结构)。然而,相关研究观察到,transformer块可能会在一定程度上恶化高频信息,如局部纹理信息。不同频率段中的信号在人类视觉系统中是必不可少的,并且将以某种特定的方式融合,以提取更重要和独特的特征。
-
在这些观察的激励下,本文开发了下一个transformer块(NTB),以在轻量化机制中捕获多频率信号。此外,NTB作为一个有效的多频信号mixer,进一步增强了整体建模能力。如图【整体分层架构】所示,NTB首先使用高效的多头部自我注意(E-MHSA)捕获低频信号,其可以描述为:
-
E − M H S A ( z ) = C o n c a t ( S A 1 ( z 1 ) , S A 2 ( z 2 ) , . . . S A h ( z h ) ) W P , ( 4 ) E-MHSA(z)=Concat(SA_1(z_1),SA_2(z_2),...SA_h(z_h))W^P,(4) E−MHSA(z)=Concat(SA1(z1),SA2(z2),...SAh(zh))WP,(4)
-
其中z=[z1,z2,…,zh]表示在通道维度上将输入特征z划分为多头部形式。SA是一种空间约简自关注算子,其灵感来自线性SRA,其表现为:
-
S A ( X ) = A t t e n t i o n ( X , W Q , P s ( X ⋅ W K ) , P s ( X ⋅ W V ) ) , ( 5 ) SA(X)=Attention(X,W^Q,P_s(X·W^K),P_s(X·W^V)),(5) SA(X)=Attention(X,WQ,Ps(X⋅WK),Ps(X⋅WV)),(5)
-
其中,注意力表示标准注意力,计算为注意力(Q,K,V)=softmax(QKT-dk)V,其中dk表示缩放因子。WQ、WK、WV是用于上下文编码的线性层。Ps是具有步幅s的平均池操作,用于在注意力操作之前对空间维度进行下采样以降低计算成本。具体而言,本文观察到E-MHSA模块的时间消耗也受到其信道数量的极大影响。因此,NTB利用逐点卷积在E-MHSA模块之前执行信道维度缩减,以进一步加速推断。为了减少信道,引入了收缩比r。还利用E-MHSA模块中的批量规范化来实现极其高效的部署。
-
此外,NTB配备了MHCA模块,该模块与E-MHSA模块协作以捕获多频信号。之后,来自E-MHSA和MHCA的输出特征被级联以混合高低频信息。最后,在最后借用MLP层来提取更基本和独特的特征。简言之,NTB的实施可以制定如下:
-
z l ˉ \bar{z^l} zlˉ
-
其中~zl、ˆzl和zl分别表示E-MHSA、MHCA和NTB的输出。Proj表示信道投影的逐点卷积层。此外,NTB统一采用BN和ReLU作为有效的范数和激活层,而不是LN和GELU。与传统的Transformer块相比,NTB能够在轻量级机制中捕获和混合多频率信息,这大大提高了模型性能。
-
Next Hybrid Strategy (NHS)
-
最近的一些工作付出了巨大努力,将CNN和Transformer结合起来,以实现高效部署。如下图(b)(c)所示,它们几乎都在浅层中单调地采用卷积块,在最后一个或两个阶段中仅堆叠Transformer块,这在分类任务中提供了有效的结果。
-

-
Comparison of traditional hybrid strategies and NHS.
-
-
不幸的是,观察到,这些传统的混合策略在下游任务(例如分割和检测)上很容易达到性能饱和。原因是,分类任务仅使用最后阶段的输出进行预测,而下游任务(例如分割和检测)通常依赖于每个阶段的特征来获得更好的结果。
-
然而,传统的混合策略只是在最后几个阶段堆叠Transformer块。因此,浅阶段无法捕获全局信息,例如对象的全局形状和结构,这对于分割和检测任务至关重要。
-
为了克服现有混合策略的失败,本文从新的角度提出了下一个混合策略(NHS),该策略创造性地将卷积块(NCB)和transformer块(NTB)与(N+1)叠加在一起∗ L混合范式。
-
NHS在控制transformer块的比例以实现高效部署的情况下,显著提高了下游任务中的模型性能。首先,为了赋予浅级捕获全局信息的能力,提出了一种新的(NCB×N+NTB×1)模式混合策略,如上图(d)所示,该策略在每个级中依次堆叠N个NCB和一个NTB。
-
具体而言,Transformer块(NTB)放置在每个阶段的末尾,这使模型能够学习浅层中的全局表示。本文进行了一系列实验来验证所提出的混合策略的优越性。差分混合策略的性能如下表所示。
-
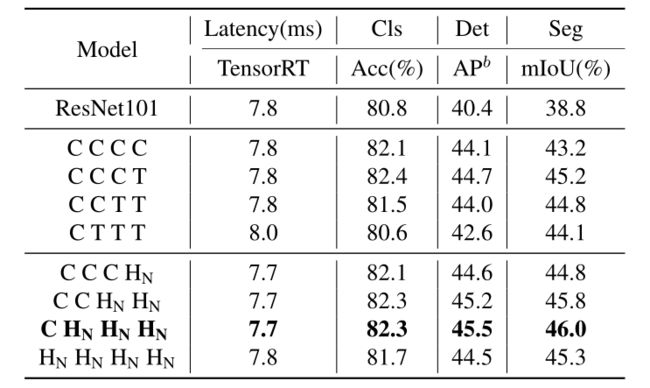
-
不同混合策略的比较。Cls表示ImageNet-1K分类任务。Det表示使用掩码RCNN 1×。Seg表示在ADE20K数据集上具有语义FPN 80k的分割任务。TensorRT延迟是以8×3×224×224的输入大小均匀测量的。
-
-
C表示在一个阶段中均匀堆叠卷积块(NCB),T表示用transformer块(NTB)一致构建一个阶段。特别地,HN表示在相应阶段以(NCB×N+NTB×1)图案堆叠NCB和NTB。上表中的所有型号都配备了四级。
-
例如,C C C表示在所有四个阶段中始终使用卷积块。为了公平比较,在相似的TensorRT延迟下构建了所有模型。第4节介绍了更多的实现细节。如上表所示,与下游任务中的现有方法相比,所提出的混合策略显著提高了模型性能。
-
C HN HN实现了最佳的整体性能。例如,C HN HN在检测方面超过C C T 0.8 mAP,在分割方面超过0.8%mIoU。此外,HN-HN-HN的结果表明,将transformer块放置在第一阶段将恶化模型的等待时间精度权衡。
-
本文通过增加第三阶段的块数,如ResNet,进一步验证了C HN HN HN在大模型上的总体有效性。下表中前三行的实验结果表明,大型模型的性能很难提高,并逐渐达到饱和。这种现象表明,通过扩大(NCB×N+NTB×1)模式的N来扩展模型大小,即简单地添加更多卷积块不是最佳选择。
-
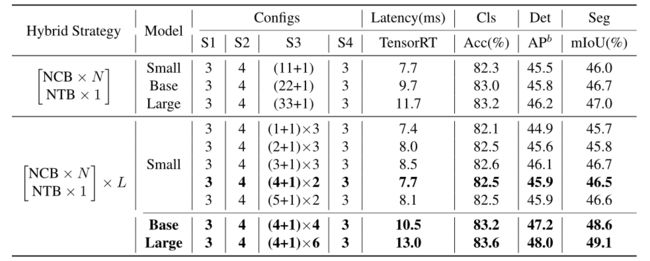
-
NHS中不同模式的比较和不同超参数配置的探索。S1、S2、S3和S4分别表示阶段1、阶段2、阶段3和阶段4。
-
-
这也意味着(NCB×N+NTB×1)模式中的N值可能会严重影响模型性能。因此,开始通过大量实验探索N值对模型性能的影响。如上表(中间)所示,在第三阶段构建了N的不同配置的模型。为了建立具有相似延迟的模型以进行公平比较,当N的值很小时,堆叠L组(NCB×N+NTB×1)模式。令人惊讶的是,发现(NCB×N+NTB×1)×L模式中的堆栈NCB和NTB与(NCB x N+NTC×1)模式相比实现了更好的模型性能。
-
这表明,以适当的方式((NCB×N+NTB×1))重复组合低频信号提取器和高频信号提取机会导致更高质量的表示学习。如上表所示,第三阶段N=4的模型在性能和延迟之间实现了最佳平衡。在第三阶段通过放大(NCB×4+NTB×1)×L模式的L来进一步构建更大的模型。
-
如上表(底部)所示,与小模型相比,Base(L=4)和Large(L=6)模型的性能显著提高,这验证了所提出的(NCB×N+NTB×1)×L模式的总体有效性。在本文的其余部分中,使用N=4作为基本配置。、
-
本文将NCB和NTB与上述下一个混合策略叠加,以构建下一个ViT,其正式定义为:
-
N e x t − V i T ( X ) = Next-ViT(X)= Next−ViT(X)=
-
其中 i∈ (1,2,3,4)表示阶段索引。Ψ表示NCB。Γ表示i=1时的身份层,否则为NTB。最后,H表示按顺序堆叠级的操作。
-
Next-ViT Architectures
-
为了与现有的SOTA网络进行公平的比较,提出了三种典型的变体,即Next ViTS/B/L。架构规范列于下表中,其中C表示输出通道,S表示每个阶段的步幅。此外,NTB中的信道收缩比r被均匀地设置为0.75,E-MHSA中的空间缩减比s在不同阶段为[8,4,2,1]。MLP层的膨胀比分别设置为NCB的3和NTB的2。E-MHSA和MHCA中的头部尺寸设置为32。对于标准化层和激活功能,NCB和NTB都使用BatchNorm和ReLU。
-

-
Detailed configurations of Next-ViT variants.
-
Experimental Results
ImageNet-1K Classification
Implementation
-
在ImageNet-1K上进行了图像分类实验,其中包含约1.28M个训练图像和来自1K个类别的50K个验证图像。为了进行公平的比较,遵循了最近的视觉transformer[Twins,Sepvit,Pyramid vision transformer,Scalablevit]的训练设置,并进行了细微的更改。具体而言,所有Next-ViT变体都在8个V100 GPU上训练了300个epoch,总批量大小为2048。输入图像的分辨率调整为224×224。采用AdamW作为优化器,权重衰减为0.1。学习速率基于余弦策略逐渐衰减,初始化2e-3,并对所有NextViT变体使用20个epoch的线性预热策略。此外,还采用了增加的随机深度增加,Next-ViT-S/B/L的最大跌落路径速率为0.1、0.2、0.2。
-
根据SSLD,在大规模数据集上训练带有†的模型。对于384×384的输入大小,微调了30个epoch的模型,权重衰减为1e-8,学习率为1e-5,批量大小为1024。输入大小对应于相应的方法,下表中的延迟是基于TensorRT-8.0.3框架(T4 GPU(批量大小=8)和CoreML框架(iPhone12 Pro Max和iOS 16.0(批量大小=1))统一测量的。请注意,iPhone 12和iPhone 12 Pro Max都配备了相同的A14处理器。
-

-
比较ImageNet-1K分类的不同最新方法。CoreML不支持HardSwish,∗ 表示本文将其替换为GELU以进行公平比较。†表示使用大规模数据集遵循SSLD。
-
Comparison with State-of-the-art Models
-
如上表所示,与最新的技术方法(如CNN、ViT和混合网络)相比,在准确性和延迟之间实现了最佳权衡。具体而言,与ResNet101等著名CNN相比,Next-ViT-S在TensorRT上的延迟相似,在CoreML上的速度更快(从4.0ms到3.5ms),准确性提高了1.7%。
-
同时,NextViTL实现了与EfficientNet-B5和ConvNeXt-B类似的准确性,而在Tensor RT上的速度是4.0倍和1.4倍,在Core ML上是3.2倍和44倍。就高级ViT而言,Next-ViT-S在TensorRT上的推理速度快1.3倍,比Twins-SVT-S[3]快0.8%。
-
Next-ViT-B超过CSwin-T,0.5%,而推理延迟在TensorRT上压缩了64%。最后,与最近的混合方法相比,Next-ViT-S在TensorRT和CoreML上以1.8倍和1.4倍的速度超过CMT-XS 0.7%。与EfficientFormer-L7相比,Next-ViT-L预测在CoreML上的运行时间减少20%,在TensorRT上的运行时减少25%,同时性能从83.3%提高到83.6%。
-
Next-ViT-L还获得了15%的推理延迟增益,并实现了比TRTViT-D更好的性能。这些结果表明,所提出的NextViT设计是一种有效且有前景的范例。
ADE20K Semantic Segmentation
Implementation
-
为了进一步验证本文的Next ViT的能力,对ADE20K进行了语义分割实验,其中包含来自150个类别的大约20K个训练图像和2K个验证图像。为了进行公平的比较,还遵循了先前视觉transformer在语义FPN和UperNet框架上的训练惯例。
-
大多数模型在ImageNet-1k上进行了预训练,带有†的模型在大规模数据集上进行了预先训练。所有模型都以分辨率224×224进行预训练,然后在输入大小为512×512的ADE20K上进行训练。对于语义FPN框架,采用AdamW优化器,学习率和权重衰减均为0.0001。然后,基于Next-ViT-S/B/L的随机深度0.2,以总批大小32为基础,对整个网络进行40K次迭代的训练。
-
为了在UperNet框架上进行训练和测试,还训练了160K次迭代的模型,随机深度为0.2。AdamW优化器也被使用,但学习率为6×10−5,总批量16,重量衰减0.01。然后,基于单尺度和多尺度(MS)测试mIoU,其中尺度从0.5到1.75,间隔为0.25。
-
对于检测和分割任务,由于Mask R-CNN和Upernet中的某些模块不容易部署在TensorRT和CoreML上,仅测量主干的延迟,以进行公平比较,使用与分类相同的测试环境。为了简单起见,512×512的输入大小统一用于测量下表中的延迟。
-
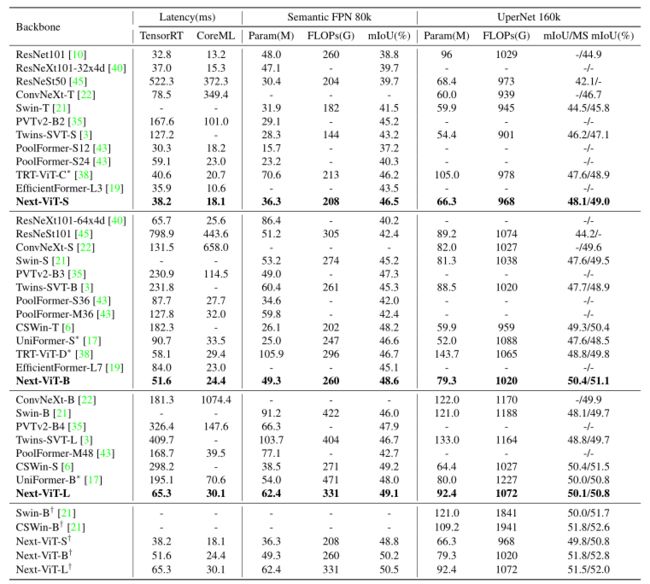
-
ADE20K语义分割任务中不同骨干的比较。FLOP的输入大小为512×2048。†表示训练语义FPN-80K,用于80K次迭代,总批大小为32,与常规设置相比,是2×训练数据迭代。†表明该模型是在大规模数据集上预先训练的。
-

-
基于Mask R-CNN的对象检测和实例分割任务中不同骨干的比较。以800×1280的inpus大小测量FLOP。上标b和m表示框检测和掩码实例分割。
-
Comparison with State-of-the-art Models
-
在上表中,还与CNN、ViT和最近的混合方法进行了比较。Next-ViT-S分别超过ResNet101和ResNeXt101-32x4d 7.7%和6.8%mIoU。Next-ViT-B比CSwin-T快0.4%mIoU,推理速度在TensorRT上加快了2.5倍。与Uniformer-S/B相比,Next-ViT-B/L实现了2.0%和1.1%的mIoU性能增益,而CoreML和TensorRT分别快0.4×/1.3倍和0.8×/1.6倍。
-
Next-ViT-B在类似的CoreML运行时间下超过EfficientFormerL7 3.5%mIoU,在TensorRT上的延迟减少38%。就UperNet框架而言,Next-ViT-S超越了最近的SOTA CNN模型ConvNeXt 2.3%MS mIoU,而在TensorRT和CoreML上分别快1.0倍和18.0倍。与CSWin-S相比,Next-ViT-L在TensorRT上实现了3.6倍的速度,性能相似。广泛的实验表明,本文的Next ViT在分割任务中具有优异的潜力。
Object Detection and Instance Segmentation
Implementation
- 接下来,使用COCO2017基于Mask R-CNN框架,评估Next ViT在目标检测和实例分割任务上的表现。具体而言,本文的所有模型都在ImageNet-1K上进行了预训练,然后根据先前工作的设置进行微调。对于12个周期(1×)实验,使用了权重衰减为0.05的AdamW优化器。在训练过程中,热身有500次迭代,在第8和第11阶段,学习率将下降10倍。基于多尺度(MS)训练的36个阶段(3倍)实验,使用调整大小的图像对模型进行训练,以使较短的边从480到800,较长的边最多为1333。在第27和第33阶段,学习速度将下降10×。其他设置与1×相同。
Comparison with State-of-the-art Models
-
上表显示了Mask R-CNN框架的评估结果。根据1×时间表,Next-ViT-S超过ResNet101和ResNeSt50 5.5 APb和3.3 APb。Next-ViT-L比PVTv2-B4快0.5 APb,在TensorRT和CoreML上预测运行速度分别快4.0倍和3.9倍。与EfficientFormer-L7相比,Next-ViT-B以相似的CoreML延迟和39%的TensorRT运行时间将APb从42.6提高到47.2。
-
NextViT-B优于TRT-ViT-D 1.9 APb,但在TensorRT和CoreML上仍然更快。基于3×时间表,Next ViT显示出与1×相同的优势。具体来说,Next-ViT-S以5.2 APb的延迟超过了ResNet101,具有相似的延迟。与Twins-SVT-S相比,NextViT-S的性能提高了1.2 APb,但在TensorRT上的速度提高了3.2倍。Next-ViT-B的预测时间比CSwinT快0.5 APb,但预测时间少2.5倍。对于Next-ViT-L,它在对象检测和实例分割方面表现出与CSwin相似的性能,但推理速度加快了79%。
Ablation Study and Visualization
- 为了更好地理解本文的Next ViT,通过评估其在ImageNet-1K分类和下游任务上的性能来消融每个关键设计。还可视化了输出特征的傅里叶光谱和热图,以显示Next ViT的内在优势。
Impact of Next Convolution Block
-
为了验证所提出的NCB的有效性,将Next ViT中的NCB替换为著名的块,如ResNet中的瓶颈、ConvNeXt块、Twins中的LSA块等。为了公平比较,一致使用NTB和NHS在TensorRT上的相似延迟下构建不同的模型。
-
如下表所示,NCB在所有三个任务中实现了最佳的延迟/准确性权衡,这验证了所提出的NCB的优势。例如,NCB在分类方面优于最近的ConvNeXt块[10]2.9%,在检测方面优于4.5APb,在分割方面优于2.8%mIoU。
-
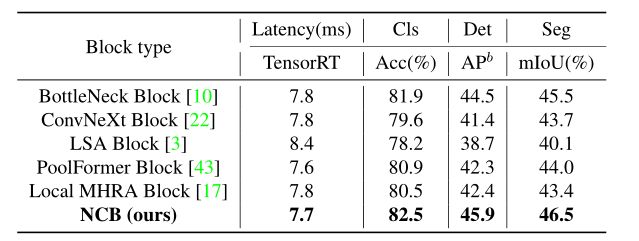
-
Comparison of different convolution blocks.
-
Impact of Different Shrink Ratios in NTB
-
此外,探讨了Next ViT块的收缩比r对Next ViT整体性能的影响。如下表所示,减小收缩比r,即e-MHSA模块中的信道数,将减少模型延迟。此外,r=0.75和r=0.5的模型比使用纯transformer的模型(r=1)获得更好的性能。这表明以适当的方式融合多频率信号将增强表示学习的模型能力。
-
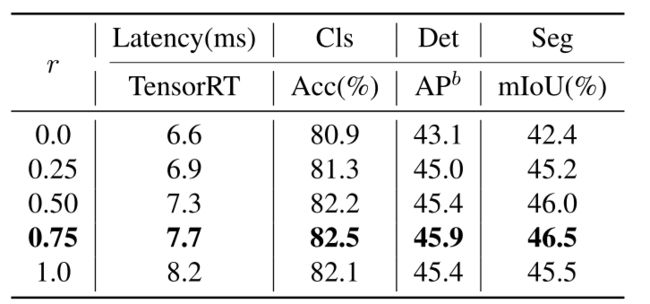
-
Comparison of results of different ratios.
-
-
特别是,r=0.75的模型实现了最佳的延迟/准确性权衡。它在分类、检测和分割方面优于基线模型(r=1.0),分别为0.4%、0.5APb和1.0%mIoU,同时更轻。上述结果表明了所提出的NTB块的有效性。
Impact of Normalization and Activation
-
进一步研究了Next ViT中不同归一化层和激活函数的影响。如下表所示,LN和GELU都带来了微不足道的性能改进,但在TensorRT上具有明显更高的推理延迟。另一方面,BN和ReLU在总体任务上实现了最佳的延迟/准确性权衡。因此,在Next ViT中统一使用BN和ReLU,以便在实际工业场景中高效部署。
-
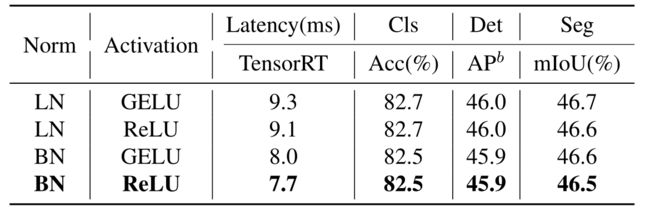
-
Different normalizations and activations comparison.
-
Visualization
-
为了验证本文的Next ViT的优越性,在下图(a)中可视化了ResNet、Swin Transformer和Next ViT的输出特征的傅里叶光谱和热图。ResNet的频谱分布表示卷积块倾向于捕获高频信号,而难以关注低频信息。另一方面,ViT擅长捕捉低频信号,但忽略高频信号。最后,Next ViT能够同时捕获高质量和多频信号,这表明了NTB的有效性。
-
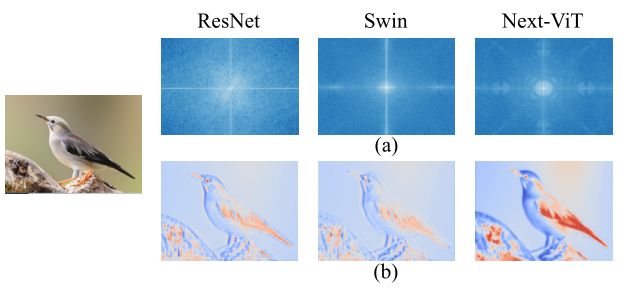
- (a) ResNet、Swin和Next ViT的傅里叶光谱。(b) ResNet、Swin和Next ViT输出特征的热图。
-
此外,如图(b)所示,与ResNet和Swin相比,Next ViT可以捕获更丰富的纹理信息和更准确的全局信息(例如边缘形状),这表明Next ViT具有更强的建模能力。
Conclusion
- 在本文中,提出了一系列Next ViT,该系列将高效的Next卷积块和Next Transformer块堆叠在一种新的策略中,以构建强大的CNNTransformer混合架构,以便在移动设备和服务器GPU上高效部署。实验结果表明,Next ViT在各种视觉任务(如图像分类、对象检测和语义分割)中实现了最先进的延迟/准确性权衡。在视觉神经网络设计方面,本文的工作在学术研究和工业部署之间建立了一座稳定的桥梁。希望本文的工作将提供新的见解,并促进针对现实工业部署的神经网络架构设计的更多研究。
和更准确的全局信息(例如边缘形状),这表明Next ViT具有更强的建模能力**。