NNDL 作业4:第四章课后题
习题4-1
试设计一个前馈神经网络来解决 XOR 问题,要求该前馈神经网络具有两个隐藏神经元和一个输出神经元,并使用 ReLU 作为激活函数。
答:XOR就是逻辑运算中的异或问题,异或是对两个运算元的一种逻辑分析类型,当两两数值相同时为否,而数值不同时为真。下面是异或运算表:
| 输入 | 输出 | |
| A | B | A XOR |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
要解决XOR运算问题,需要生成非线性的决策边界。因此,我们使用多层感知机进行求解,在单层前馈神经网络的基础上,加入一层隐含层,即二层的前馈神经网络进行XOR的运算,我们设计了一个二层的前馈神经网络对XOR运算进行求解。网络结构由一个输入层、一个隐含层和一个输出层构成,其中输入层有两个神经元,隐含层有两个神经元,输出层有一个神经元构成。
XOR运算网络结构图如下所示:
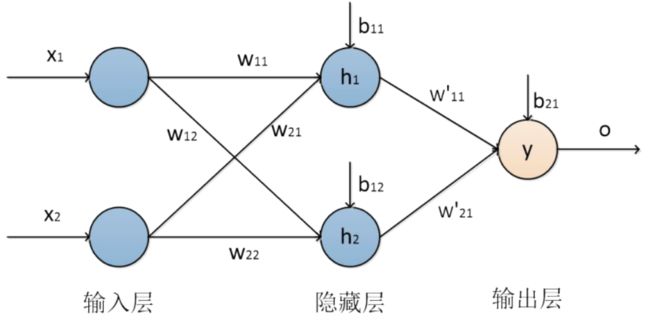
代码实现如下:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class XORModule(nn.Module):
def __init__(self):
super(XORModule, self).__init__()
self.fc1 = nn.Linear(2, 2) # 输入层和隐藏层
self.fc2 = nn.Linear(2, 1) # 隐藏层和输出层
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 2)
x = self.relu((self.fc1(x)))
x = self.fc2(x)
return x
# 输入和输出数据
input_x = torch.Tensor([[0, 0], [0, 1], [1, 0], [1, 1]])
input_x1 = input_x.float()
real_y = torch.Tensor([[0], [1], [1], [0]])
real_y1 = real_y.float()
# 设置损失函数和参数优化函数
net = XORModule()
loss_function = nn.MSELoss() # 用交叉熵损失函数会出现维度错误
optimizer = optim.SGD(net.parameters(), lr=0.5) # 用Adam优化参数选不好会出现计算值超出0-1的范围
# 进行训练
for epoch in range(100):
out_y = net(input_x1)
loss = loss_function(out_y, real_y1) # 计算损失函数
optimizer.zero_grad() # 对梯度清零,避免造成累加
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 输出权值和偏置
print('w1 = ', net.fc1.weight.detach().numpy())
print('b1 = ', net.fc1.bias.detach().numpy())
print('w2 = ', net.fc2.weight.detach().numpy())
print('b2 = ', net.fc2.bias.detach().numpy())
# 测试
input_test = input_x1
out_test = net(input_test)
a = np.around(out_test.detach()).numpy().tolist()
b = real_y1.numpy().tolist()
count = 0
for i in range(4):
if a[i] == b[i]:
count += 1
print("正确率为", count*100/4, "%")
运行结果:
w1 = [[-0.76744676 -0.6956512 ]
[-0.18567026 -0.5393881 ]]
b1 = [ 0.69010293 -0.6672847 ]
w2 = [[-0.9660393 -0.00620884]]
b2 = [0.6666666]
input_x:
[[0. 0.]
[0. 1.]
[1. 0.]
[1. 1.]]
out_y:
[[0.]
[1.]
[1.]
[1.]]
习题4-3
试举例说明“死亡ReLU问题”,并提出解决办法。
基础知识
在优化方面,相比于Sigmoid型函数的两端饱和,ReLU函数为左饱和函数,且在x > 0时导数为1,在一定程度上缓解了神经网络的梯度消失问题,加速梯度下降的收敛速度。——来源于邱锡鹏老师的《神经网络与深度学习》
ReLU函数及其导数的图像:
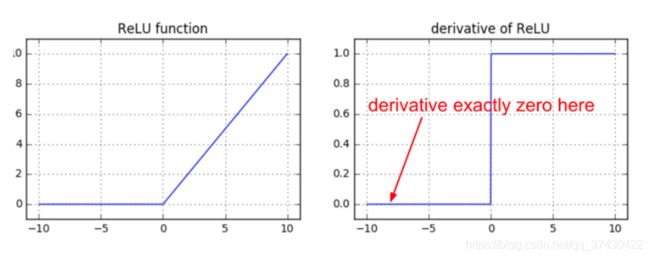
ReLU也是非线性函数,它将低于或等于 0 的神经元输入都计算成 0。使用R e L U ReLUReLU的全连接层的前向与后向传递的主要计算如下:
z = np.maximum(0, np.dot(W, x)) # forward pass
dz_dW = np.outer(z > 0, x) # backward pass: local gradient for W
观察上述代码你会发现,当前向传递中一个神经元的值恒等于 0,该神经元对应的权重的梯度将为0,这时权重得不到更新。这就会导致所谓的“死亡”ReLU问题。
如果一个 ReLU 神经元由于被不恰当地初始化而恒等于 0(这时不是模型参数的问题),或是其对应的参数在训练过程中由于大幅度的更新而接近于 0(这时在下一样本的计算中该神经元的值就会趋于为 0,随着而来的是权重的梯度为 0,权重无法更新,导致该神经元的值恒为 0),那么这个神经元将永远处于死亡状态。这就是“死亡” ReLU。这就像是永恒的,无法恢复的大脑损伤。有时,你将整个训练数据集放入一个训练过的网络中进行前向计算,你可能会发现大部分(如40% )的神经元的值一直恒为零。
所以,在使用 ReLUs 时,要警惕死亡 ReLUs,这些神经元在整个训练数据集中任一样本中都不会被激活,而是处于死亡状态。神经元在训练过程中的“死亡”,通常是学习率过大造成的。
解决方法:
使用Leaky ReLU、PReLU、ELU函数或者Softplus函数替换。
习题4-7
为什么在神经网络模型的结构化风险函数中不对偏置进行正则化?
正则化的作用是为了限制模型的复杂度避免模型过拟合,提高模型的泛化能力。
对于某个神经元的输入来说,input = w(0)x(0) + w(1)x(1) + w(2)x(2) + ······ + b
对于样本特征向量X,其对input的贡献只与权重向量W有关。
若W向量中的值都很大,若特征向量X中的值发生细微的变化会导致input值的突变。
这就导致了模型的不稳定,所有我们希望得到较小的权重值。而偏置b对于所有输入样本来说都是一致的,是一个不变量,所以不需要考虑对B进行正则化。
习题4-8
为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接令 w = 0 , b = 0?
若将和都初始化为0,则在输入层之后的所有隐藏层神经元接收到的输入都是一样的,那么在使用反向传播算法进行梯度的传递时,每一隐藏层的权重梯度值都是相同的,这就导致了权重只能向同一方向下降,这和问题4-1有一定的相似性,只不过是从权重和偏置方面导致了输入X值的非零均值化(更极端的是所有值相同)。
习题4-9
梯度消失问题是否可以通过增加学习率来缓解?
梯度消失
主要是因为网络层数太多,太深,导致梯度无法传播。本质应该是激活函数的饱和性。
表现:神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差就因为乘了很多的小于1的数而越来越小,最终就会变为0,从而导致层数比较浅的权重没有更新,这就是梯度消失。
DNN结果出现nan值?梯度爆炸,导致结果不收敛。都是梯度太大惹的祸,所以可以通过减小学习率(梯度变化直接变小)、减小batch size(累积梯度更小)、 features规格化(避免突然来一个大的输入)。
怎么解决这个问题呢?
使用其他激活函数
一个方法就是使用其他激活函数,比如说双曲正切
Relu函数,这个函数也是除了sigmoid之外最常用的,我们可以在前面的一些单元使用relu函数,最后使用sigmoid函数,因为sigmoid会返回0~1的值
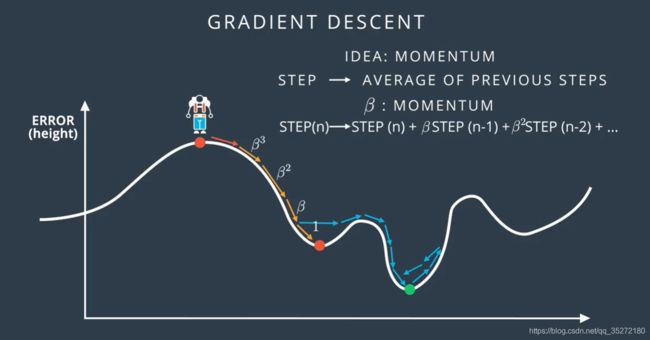
动量
还有一个方法就是动量,动量β是一个0~1之间的数,每次的步长跟前几次的步长有关系,上一步×1,再上一步×β,再再上一步×β²……,越往前的影响越小,这种方法在实际应用中效果很好
学习速率衰退
如果学习速率太大,那么可能最后会在最小值附近震荡,如果速率太小,速度又很慢,我们可以使用学习速率衰减的方法。
参考:
前馈神经网络求解XOR问题_人工智能AI算法的博客-CSDN博客 https://blog.csdn.net/sinat_28178805/article/details/118764250?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166536144516782417097574%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166536144516782417097574&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-118764250-null-null.142%5Ev52%5Epc_rank_34_2,201%5Ev3%5Eadd_ask&utm_term=xor%E9%97%AE%E9%A2%98&spm=1018.2226.3001.4187Sigmoid型函数梯度消失、“死亡”ReLUs 和 RNNs梯度爆炸问题_夏树让的博客-CSDN博客_梯度死亡https://blog.csdn.net/qq_37430422/article/details/102496384?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166536333316782388096063%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166536333316782388096063&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-102496384-null-null.142%5Ev52%5Epc_rank_34_2,201%5Ev3%5Eadd_ask&utm_term=%E6%AD%BB%E4%BA%A1ReLU%E9%97%AE%E9%A2%98&spm=1018.2226.3001.4187深度学习-梯度爆炸和梯度消失_sisteryaya的博客-CSDN博客_梯度消失和梯度爆炸https://blog.csdn.net/sisteryaya/article/details/81364089?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166536428516782388067126%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166536428516782388067126&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-3-81364089-null-null.142%5Ev52%5Epc_rank_34_2,201%5Ev3%5Eadd_ask&utm_term=%E6%A2%AF%E5%BA%A6%E6%B6%88%E5%A4%B1%E9%97%AE%E9%A2%98%E6%98%AF%E5%90%A6%E5%8F%AF%E4%BB%A5%E9%80%9A%E8%BF%87%E5%A2%9E%E5%8A%A0%E5%AD%A6%E4%B9%A0%E7%8E%87%E6%9D%A5%E7%BC%93%E8%A7%A3&spm=1018.2226.3001.4187
https://blog.csdn.net/sinat_28178805/article/details/118764250?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166536144516782417097574%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166536144516782417097574&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-118764250-null-null.142%5Ev52%5Epc_rank_34_2,201%5Ev3%5Eadd_ask&utm_term=xor%E9%97%AE%E9%A2%98&spm=1018.2226.3001.4187Sigmoid型函数梯度消失、“死亡”ReLUs 和 RNNs梯度爆炸问题_夏树让的博客-CSDN博客_梯度死亡https://blog.csdn.net/qq_37430422/article/details/102496384?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166536333316782388096063%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166536333316782388096063&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-102496384-null-null.142%5Ev52%5Epc_rank_34_2,201%5Ev3%5Eadd_ask&utm_term=%E6%AD%BB%E4%BA%A1ReLU%E9%97%AE%E9%A2%98&spm=1018.2226.3001.4187深度学习-梯度爆炸和梯度消失_sisteryaya的博客-CSDN博客_梯度消失和梯度爆炸https://blog.csdn.net/sisteryaya/article/details/81364089?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166536428516782388067126%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166536428516782388067126&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-3-81364089-null-null.142%5Ev52%5Epc_rank_34_2,201%5Ev3%5Eadd_ask&utm_term=%E6%A2%AF%E5%BA%A6%E6%B6%88%E5%A4%B1%E9%97%AE%E9%A2%98%E6%98%AF%E5%90%A6%E5%8F%AF%E4%BB%A5%E9%80%9A%E8%BF%87%E5%A2%9E%E5%8A%A0%E5%AD%A6%E4%B9%A0%E7%8E%87%E6%9D%A5%E7%BC%93%E8%A7%A3&spm=1018.2226.3001.4187