Deep leakage from Gradients论文解析
Deep leakage from Gradients论文解析
今天来给大家介绍下2019年NIPS上发表的一篇通过梯度进行原始数据恢复的论文。
论文传送门
**问题背景:**现在分布式机器学习和联邦学习中普遍接受的一个做法是将数据梯度进行共享,多方数据通过共享的梯度信息进行联合建模,即在原始数据不出库的前提下进行建模,那么这样引出作者的一个思考:这样的梯度信息是否是安全的呢?我们知道,梯度与标签和样本特征有关,那么意味着梯度其中包含着部分的标签信息和原始信息,所以作者做了这样一个工作,通过神经网络中的梯度信息去反推原始数据和标签。
**方法:**作者将随机生成一份和真数据同样大小的假输入样本和假的标签,然后把这些假样本和假标签输入到现有的模型当中,然后得到假的模型梯度。方法的目标是生成与原模型相同梯度的假梯度,这样在假样本和假标签就和真实的样本标签一致。目标函数如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g2V8G1qx-1625824202252)(/Users/chenxiaolin/Library/Application Support/typora-user-images/image-20210709172942169.png)]](http://img.e-com-net.com/image/info8/b181acdb763d4ba79484522a0e25bcb7.jpg)
流程:
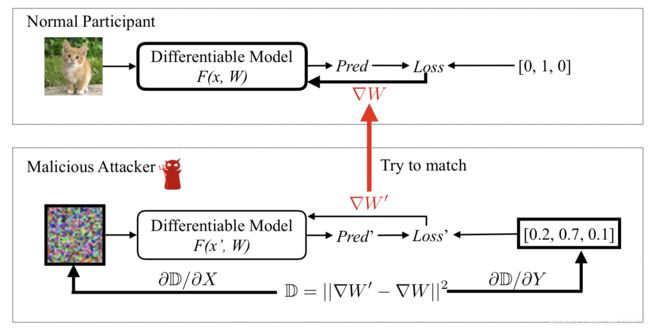
这里拿一张小猫图片进行示例,对于输入样本可以通过训练过的网络得到预测值和梯度。而在攻击模型中,将随机输入我们的输入x和标签向量,将模型迁移过来。然后我们将计算我们的梯度与原模型梯度大差值,通过反推更新输入样本和标签信息,以此进行迭代。
算法:

如上所属,对没个输入样本遍历,迭代更新输入的假样本和假标签,直到达到收敛。
实验结果:

从实验中,我们看出,对于输入的图片,经过少轮的迭代即可恢复出大致图像信息。

可以看出,随着网络层数的增加,原始信息恢复的就更多,相比Meils方法,作者的方法显著更小。
代码:
原作者代码传送
代码解读:这里有详细的代码解析。
def main():
seed = 1234 # 经过专家的实验, 随机种子数为1234结果会较好
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
dataset = args.dataset # 获得命令行输入的dataset
root_path = '.'
data_path = os.path.join(root_path, './data').replace('\\', '/') # 指定数据存放的路径地址, replace是进行转义
save_path = os.path.join(root_path, 'results/DLG_%s' % dataset).replace('\\', '/') # 图片保存的路径
lr = 0.2 # 学习率
num_dummy = 1 # 一次输入还原的图片数量
iteration = 300 # 一张图片迭代的次数
num_exp = 1 # 实验次数也就是神经网络训练的epoch
use_cuda = torch.cuda.is_available() # 是否可以使用gpu,返回值为True或False
device = 'cuda' if use_cuda else 'cpu' # 设置 device是cpu或者cuda
tt = transforms.Compose([transforms.ToTensor()]) # 将图像类型数据(PILImage)转换成Tensor张量
tp = transforms.Compose([transforms.ToPILImage()]) # 将Tensor张量转换成图像类型数据
'''
打印路径而已
'''
print(dataset, 'root_path:', root_path)
print(dataset, 'data_path:', data_path)
print(dataset, 'save_path:', save_path)
if not os.path.exists('results'): # 判断是否存在results文件夹,没有就创建,Linux中mkdir创建文件夹
os.mkdir('results')
if not os.path.exists(save_path): # 是否存在路径, 不存在则创建保存图片的路径
os.mkdir(save_path)
'''
加载数据
'''
if dataset == 'MNIST' or dataset == 'mnist': # 判断是什么数据集
image_shape = (28, 28) # mnist数据集图片尺寸是28x28
num_classes = 10 # mnist数据分类为十分类: 0 ~ 9
channel = 1 # mnist数据集是灰度图像所以是单通道
hidden = 588 # hidden是神经网络最后一层全连接层的维度
dst = datasets.MNIST(data_path, download=True)
elif dataset == 'cifar10' or dataset == 'CIFAR10':
image_shape = (32, 32) # cifar10数据集图片尺寸是32x32
num_classes = 10 # cifar10数据分类为十分类:卡车、 飞机等
channel = 3 # cifar10数据集是RGB图像所以是三通道
hidden = 768 # hidden是神经网络最后一层全连接层的维度
dst = datasets.CIFAR10(data_path, download=True)
elif dataset == 'cifar100' or dataset == 'CIFAR100':
image_shape = (32, 32) # cifar100数据集图片尺寸是32x32
num_classes = 100 # cifar100数据分类为一百个分类
channel = 3 # cifar100数据集是灰度图像所以是单通道
hidden = 768 # hidden是神经网络最后一层全连接层的维度
dst = datasets.CIFAR100(data_path, download=True)
elif dataset == 'lfw':
shape_img = (32, 32)
num_classes = 5749
channel = 3
hidden = 768
lfw_path = os.path.join(root_path, './data/lfw')
dst = lfw_dataset(lfw_path, shape_img)
else:
exit('unkown dataset') # 未定义的数据集
for idx_net in range(num_exp):
net = LeNet(channel=channel, hidden=hidden, num_classes=num_classes) # 初始化LeNet模型
net.apply(weights_init) # 初始化模型中的卷积核的权重
print('running %d|%d experiment' % (idx_net, num_exp))
net = net.to(device)
print('%s, Try to generate %d images' % ('DLG', num_dummy))
criterion = nn.CrossEntropyLoss().to(device) # 设置损失函数为交叉熵函数
imidx_list = [] # 用于记录当前还原图片的下标
for imidx in range(num_dummy):
idx = args.index # 从命令行获取还原图片的index
imidx_list.append(idx) # 将index加入到列表中
tmp_datum = tt(dst[idx][0]).float().to(device) # 将数据集中index对应的图片数据拿出来转换成Tensor张量
tmp_datum = tmp_datum.view(1, *tmp_datum.size()) # 将tmp_datum数据重构形状, 可以用shape打印出来看看
tmp_label = torch.Tensor([dst[idx][1]]).long().to(device) # 将数据集中index对应的图片的标签拿出来转换成Tensor张量
tmp_label = tmp_label.view(1, ) # 将标签重塑为列向量形式
if imidx == 0: # 如果imidx为0, 代表只处理一张图片
gt_data = tmp_datum # gt_data表示真实图片数据
gt_label = tmp_label # gt_label 表示真实图片的标签
else:
gt_data = torch.cat((gt_data, tmp_datum), dim=0) # 如果是多张图片就要将数据cat拼接起来
gt_label = torch.cat((gt_label, tmp_label), dim=0)
# compute original gradient
out = net(gt_data) # 将真实图片数据丢入到net网络中获得一个预测的输出
y = criterion(out, gt_label) # 使用交叉熵误差函数计算真实数据的预测输出和真实标签的误差
dy_dx = torch.autograd.grad(y, net.parameters()) # 通过自动求微分得到真实梯度
# 这一步是一个列表推导式,先从dy_dx这个Tensor中一步一步取元素出来,对原有的tensor进行克隆, 放在一个list中
# https://blog.csdn.net/Answer3664/article/details/104417013
original_dy_dx = list((_.detach().clone() for _ in dy_dx))
# generate dummy data and label。 生成假的数据和标签
dummy_data = torch.randn(gt_data.size()).to(device).requires_grad_(True)
dummy_label = torch.randn((gt_data.shape[0], num_classes)).to(device).requires_grad_(True)
optimizer = torch.optim.LBFGS([dummy_data, dummy_label], lr=lr) #设置优化器为拟牛顿法
history = [] # 记录全部的假的数据(这里假的数据指的是随机产生的假图像)
history_iters = [] # 记录画图使用的迭代次数
grad_difference = [] # 记录真实梯度和虚假梯度的差
data_difference = [] # 记录真实图片和虚假图片的差
train_iters = [] #
print('lr =', lr)
for iters in range(iteration): # 开始训练迭代
def closure(): # 闭包函数
optimizer.zero_grad() # 每次都将梯度清零
pred = net(dummy_data) # 将假的图片数据丢给神经网络求出预测的标签
# 将假的预测进行softmax归一化,转换为概率
dummy_loss = -torch.mean(
torch.sum(torch.softmax(dummy_label, -1) * torch.log(torch.softmax(pred, -1)), dim=-1))
# dummy_loss = criterion(pred, gt_label)
# 对假的数据进行自动微分, 求出假的梯度
dummy_dy_dx = torch.autograd.grad(dummy_loss, net.parameters(), create_graph=True)
grad_diff = 0 # 定义真实梯度和假梯度的差值
for gx, gy in zip(dummy_dy_dx, original_dy_dx): # 对应论文中的假的梯度减掉真的梯度平方的式子
grad_diff += ((gx - gy) ** 2).sum()
grad_diff.backward() # 对||dw假 - dw真|| 进行反向传播进行更新
return grad_diff
optimizer.step(closure) # 优化器更新梯度
current_loss = closure().item() # .item()方法是将Tensor中的元素转为值。item是得到一个元素张量里面的元素值
train_iters.append(iters) # 将每次迭代次数append到列表中
grad_difference.append(current_loss) # 将梯度差记录到losses列表中
data_difference.append(torch.mean((dummy_data - gt_data) ** 2).item()) # 记录数据差
if iters % int(iteration / 30) == 0: # 这一行是代表多少个iters画一张图
current_time = str(time.strftime("[%Y-%m-%d %H:%M:%S]", time.localtime())) # 每次迭代打印出来时间
print(current_time, iters, '梯度差 = %.8f, 数据差 = %.8f' % (current_loss, data_difference[-1])) # 打印出梯度差和数据差
history.append([tp(dummy_data[imidx].cpu()) for imidx in range(num_dummy)]) # history 记录的是假的图片数据
history_iters.append(iters) # 记录迭代次数用于画图使用
for imidx in range(num_dummy): # 这个循环是迭代有多少张图片输入
plt.figure(figsize=(12, 8)) # plt.figure(figsize=())让图画在画布上, 并且使用figsize指定画布的大小(传入参数为元组)
plt.subplot(3, 10, 1) # 在figure画布上画子图的意思
# plt.imshow(tp(gt_data[imidx].cpu())) # 这一行是显示真实图片的意思, 如果是mnist数据集,将这一行改为如下
plt.imshow(tp(gt_data[imidx].cpu()), cmap='gray') # 灰度图像
for i in range(min(len(history), 29)): # 这一行是迭代画出子图的意思
plt.subplot(3, 10, i + 2)
# plt.imshow(history[i][imidx]) # 在figure显示history存储假的图片数据
plt.imshow(history[i][imidx], cmap='gray') # 显示灰度图像
plt.title('iter=%d' % (history_iters[i])) # 第几次迭代
plt.axis('off')
plt.savefig('%s/DLG_on_%s_%05d.png' % (save_path, imidx_list, imidx_list[imidx])) # 保存图片地址
plt.close()
if current_loss < 0.000001: # converge
break
loss_DLG = grad_difference # 梯度差
label_DLG = torch.argmax(dummy_label, dim=-1).detach().item() # 求虚假数据产生的标签, 方便和真实图片产生的标签进行比较
mse_DLG = data_difference # 数据差`
缺陷:读者认为该论文方向新颖,通过逼近现有模型的梯度信息来反推原始数据,并且取得效果不错。但方法条件研究苛刻,需要将原模型的网络架构共享给攻击模型,在实际场景中是难以满足这样要求的,其他方是不可能完整拿到网络结构的,因此单纯实际场景下该方法并不能直接使用,此外,经验证,文章的DLG攻击仅适用于未达到收敛的模型,因为到达收敛后,梯度信息数值较小,反推原始数据时相对误差较大,从而不能很好的收敛。但这篇论文引起联邦从业者的广泛担忧,毕竟梯度信息泄漏是可能是“危险的”。
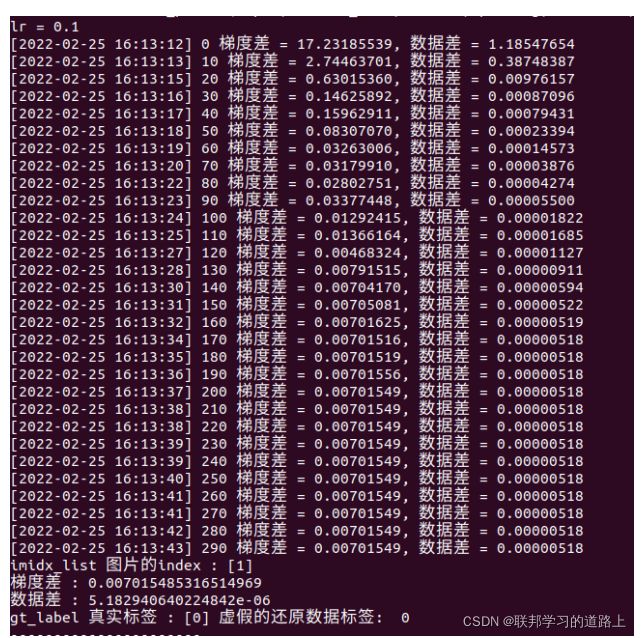
原始实验是初始化随机初始化权重后,利用损失梯度和模型对原始数据进行特征反推攻击,而这里由于预测值是初始值,梯度中包含大量信息,实验结果如下:

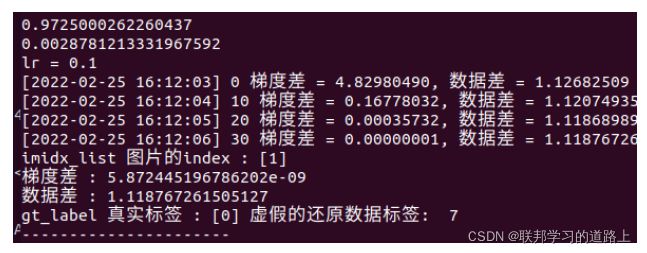
然而经过一轮迭代后,再进行梯度反推攻击得到实验结果如下:

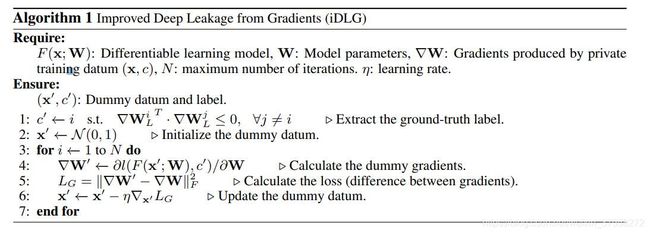
提升(iDLG):此外,有作者发现可以改进的方法:论文传送门
NN模型一般是用one-hot标签的交叉熵损失来训练的,它被定义为

y = [y1, y2, …] 是输出(logit),yi表示对第i类的预测得分(置信度)。那么,每个输出的损失梯度为

然而,我们可能无法获得关于输出y的梯度,因为它们不包括在共享梯度∇W中,后者是关于模型W的权重的导数。我们发现梯度向量可以写成

当使用非负的激活函数时,例如ReLU和Sigmoid,他们激活函数输出的符号是相同的。因此,我们可以简单地识别出其对应的梯度为负值的ground truth标签。有了这个规则,我们就很容易从共享梯度∇W中识别出私有训练数据x的ground truth标签c。因此,可以通过寻找梯度∇W中符号“与众不同”的分量来确定真实的lable