社区协作,简洁易用,快来开箱新一代 YOLO 系列开源库

MMYOLO 是 OpenMMLab 生态面向 YOLO 系列的开源算法库,由社区主导,主要涵盖了 YOLO 系列的各个算法。
MMYOLO 致力于在复现诸多 YOLO 算法的基础上,提供公平统一的算法评测流程,支持多任务易扩展的高效训练推理引擎,提供丰富的从入门到进阶的教程文档,我们希望将其打造成 YOLO 系列核心热门开源库以及工业应用核心库。
MMYOLO 在 2022 年 9 月 21 日正式开源。接下来我们对 MMYOLO 的开源背景、愿景进行简要介绍,并重点介绍 MMYOLO 特性。
官方地址:https://github.com/open-mmlab/mmyolo
官方文档地址:https://mmyolo.readthedocs.io/zh_CN/latest
1 开源背景
为啥要推出 MMYOLO? 为何要单独开一个仓库而不是直接放到 MMDetection 中? 自从开源后,不断收到社区小伙伴们类似的疑问,答案可以归纳为以下三点:
(1) 统一运行和推理平台
目前目标检测领域出现了非常多 YOLO 的改进算法,并且非常受大家欢迎,但是这类算法基于不同框架不同后端实现,存在较大差异,缺少统一便捷的从训练到部署的公平评测流程。
(2) 协议限制
众所周知,YOLOv5 以及其衍生的 YOLOv6 和 YOLOv7 等算法都是 GPL 3.0 协议,不同于 MMDetection 的 Apache 协议。由于协议问题,无法将 MMYOLO 直接并入 MMDetection 中。
(3) 多任务支持
还有一层深远的原因: MMYOLO 任务不局限于 MMDetection,后续会支持更多任务例如基于 MMPose 实现关键点相关的应用,基于 MMTracking 实现追踪相关的应用,因此不太适合直接并入 MMDetection 中。
2 愿景
MMYOLO 基于 MMDetection 3.0 开发并处于早期快速迭代阶段。MMDetection 3.0 作为 OpenMMLab 2.0 的一部分,其采用 MMEngine 训练引擎,具备高效灵活统一等特点。
基于 MMEngine,MMYOLO 可以提供更高效的训练效率,同时也方便后续进行多任务开发。
OpenMMLab 中检测相关的算法库如下图所示:

基于 OpenMMLab 2.0,MMYOLO 愿景如下图所示:

MMYOLO 在任务和代码开发方面,未来工作会将重点放在如下三个方面
(1) 统一评测
实现各类 YOLO 算法只是第一步,更为重要的是提供统一的评测流程。MMYOLO 希望能够从精度、泛化性、训练速度、推理速度、显存占用等等方面进行全面评测,让大家从诸多 YOLO 中解放出来,可以快速根据评测指标选择适合自己的模型。
(2) 多任务支持
YOLO 虽然一开始为目标检测任务而开发,但是随着该系列算法的流行,大家也开始往多任务方向迭代了。MMYOLO 也希望能够扩展 YOLO 边界,支持实例分割、全景分割和关键点检测等等多视觉任务,打造为多任务支持易用框架。
基于 OpenMMLab 2.0 扩展多任务会轻松和快速很多。因为 OpenMMLab 本身就已经实现了大量视觉任务,借鉴 MMEngine 提供的强大的跨库功能,MMYOLO 可以快速方便地使用其他 OpenMMLab 开源库中提供的组件,通过配置即可直接复用,而无需复制代码。
(3) 文档和视频资源
YOLO 用户基数非常大,用户水平跨度比较大,因此丰富的文档教程和视频教学至关重要。
MMYOLO 希望能够在文档和视频方面发力,在复现的所有算法基础上提供从入门到进阶相关的丰富教程。
我们也希望更多的社区人员能够参与文档 和 视频 的 建设,打造出最好用的 MMYOLO。
3 MMYOLO 特性
MMYOLO 相比于竞品开源库来说,核心特性或者说发力点会在如下几个方面:
(1) 对 YOLO 系列算法 的严谨复现
我们会严格遵循官方论文和开源代码进行严谨复现,确保合入的代码都是经过多次验证的。如果有不一致地方会在 README 中注明,让大家用得放心。
(2) 提供公平统一的评测流程
在严谨复现的基础上,MMYOLO 会在公平评测流程上下功夫,提供清晰易用的评测流程,让大家可以方便的选择各类模型。
(3) 更加灵活简单的模块设计
MMYOLO 专注于 YOLO 系列算法,且以高效易用为优先准则,因此在设计上会比 MMDetection 更加简单,会提供更加灵活简单的模块设计,用户用起来会更加省心,降低入门和使用难度。
(4) 更丰富的文档教程
我们会提供算法解析、从入门到部署全流程文档、训练技巧实用教程,同时还会推出视频版解读教程,带你全方位掌握 YOLO 系列算法和目标检测前沿技术。
基于优秀且模块丰富的 MMDetection 3.0,MMYOLO 可以快速尝试各类组件,同时 MMYOLO 采用社区主导,敏捷开发迭代模式,相比 MMDetection 会进行更多新设计新功能的尝试,在收到社区的良好反馈后,就会沉淀到 MMDetection 中,让 MMDetection 和 MMYOLO 相互促进,相互成长。
目前 MMYOLO 迭代到了 v0.1.1 版本,当前版本的特点总共包括 4 个方面:
- 简洁的模块层次结构
- 可定制插件的网络模块
- 丰富的入门和进阶教程
- 高效透明的社区协作
3.1 简洁的模块层次结构
3.1.1 简洁的训练和测试流

MMYOLO 训练和测试流程图,MMDetection 也遵循此规范流程
具体来说:
- 训练流,始终是调用 loss 接口(detecter.loss -> head.loss)
- 预测流,始终是调用 predict 接口,不存在各类繁杂的接口(detecter.predict -> head.predict)
- 整个 detecter 外部只需要调用和 PyTorch 一致的 forward 接口即可
可以看出 OpenMMLab 2.0 对训练和测试流程进行简化。简单来说对原先 MMDetection 2.x 时代的诸多
forward``_train
simple_test
simple_test_rpn
aug_test
get_bboxes
losses
接口进行了简化。对于熟悉 PyTorch 的用户而言,学习成本会更低。
3.1.2 简化 Loss 计算封装过程

上图为 MMYOLO 相比 MMDetection 3.0 在 loss 计算中的组件差异。可以发现 MMYOLO 对 loss 计算过程进行了简化,不再刻意强求划分三大组件,其好处是不再需要对内部数据进行层层数据封装,简化了代码逻辑,加快了训练速度、减轻了社区使用、理解和魔改难度。
以 MMDetection 的 YOLOX 配置为例:
bbox_head=dict(
type='YOLOXHead',
num_classes=80,
in_channels=128,
feat_channels=128,
stacked_convs=2,
strides=(8, 16, 32),
use_depthwise=False,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='Swish'),
...
loss_obj=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
reduction='sum',
loss_weight=1.0),
train_cfg=dict(assigner=dict(type='SimOTAAssigner', center_radius=2.5)),
通常 bbox_head 会拆分为 assigner + box coder + sampler 三个大的组件,拆分如此细致的原因在于希望能够仅通过配置修改即可任意替换各类组件,但是实际上这种做法对于一些专为 YOLO 而设计的框架中有如下缺点:
- 设计初衷是希望能任意替换组件,但是由于各类算法的差异,部分算法想仅仅修改配置就实现组件替换,例如通过配置文件替换将 YOLOX 的 assigner 应用到 RetinaNet 算法上,这个实现上比较困难,用户依然需要代码修改且对算法和代码都理解得非常透彻才可以。
- 会导致代码复杂,因为为了通用性,上述 3 个组件之间的传递需要封装额外的对象来处理,对于社区用户来说魔改难度、学习成本和易用性都存在挑战。
- 会导致训练速度较慢,以典型的 YOLOv5 来说,其
loss_by_feat部分代码进行了深度优化,从 batch 并行到 assigner 并行,如果按照我们之前的写法,分成 3 个组件,效率会很低导致训练速度慢不少。
基于上述问题,在 MMYOLO 中,我们不再刻意强求任何一个算法都强制划分为 assigner + box coder + sampler 3 个组件,只需要做到 model+ loss_by_feat 解耦即可,用户可以通过修改配置实现任意模型配合任意 loss_by_feat 计算过程。例如将 YOLOv5 模型应用 YOLOX 的 simOTA 策略等。
新的配置文件如下所示:
bbox_head=dict(
type='YOLOXHead',
head_module=dict (
type='YOLOXHeadModule',
num_classes=80,
in_channels=256,
feat_channels=256,
widen_factor=widen_factor,
stacked_convs=2,
featmap_strides=(8, 16, 32),
use_depthwise=False,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True),
),
...
loss_obj=dict(
type='mmdet.CrossEntropyLoss',
use_sigmoid=True,
reduction='sum',
loss_weight=1.0)
train_cfg=dict(
assigner=dict(
type='mmdet.SimOTAAssigner',
center_radius=2.5,
iou_calculator=dict(type='mmdet.BboxOverlaps2D'))),
3.1.3 简化 Mosaic 和 MixUp 实现
之前 MMDetection 为了支持 mosaic 和 mixup 等数据增强操作而引入了 MultiImageMixDataset wrapper,其属于 dataset 包装器,这导致使用混合类数据增强时,必须要将混合类数据增强和 MultiImageMixDataset 绑定才能使用,对于初级用户存在一定障碍。
之前有不少 issue 反馈为何在自己配置里面加入 mosaic 程序就报错了? 原因就是没有使用数据集包装器。原先的配置写法为:
train_pipeline = [
dict(type='Mosaic', img_scale=img_scale, pad_val=114.0),
dict(
type='RandomAffine',
scaling_ratio_range=(0.1, 2),
border=(-img_scale[0] // 2, -img_scale[1] // 2)),
dict(
type='MixUp',
img_scale=img_scale,
ratio_range=(0.8, 1.6),
pad_val=114.0),
dict(type='YOLOXHSVRandomAug')
]
train_dataset = dict(
# use MultiImageMixDataset wrapper to support mosaic and mixup
type='MultiImageMixDataset',
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file='annotations/instances_train2017.json',
data_prefix=dict(img='train2017/'),
pipeline=[
dict(type='LoadImageFromFile', file_client_args=file_client_args),
dict(type='LoadAnnotations', with_bbox=True)
],
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
pipeline=train_pipeline)
最合理且简洁的做法是能够将 mosaic 当做普通的 pipeline,为此 MMYOLO 对其进行了简化。新的配置写法为:
pre_transform = [
dict(
type='LoadImageFromFile',
file_client_args={{_base_.file_client_args}}),
dict(type='LoadAnnotations', with_bbox=True)
]
train_pipeline_stage = [
*pre_transform,
dict(
type='Mosaic',
img_scale=img_scale,
pad_val=114.0,
pre_transform=pre_transform),
dict(
type='mmdet.RandomAffine',
scaling_ratio_range=(0.1, 2),
border=(-img_scale[0] // 2, -img_scale[1] // 2)),
dict(
type='YOLOXMixUp',
img_scale=img_scale,
ratio_range=(0.8, 1.6),
pad_val=114.0,
pre_transform=pre_transform),
]
同时参考 RTMDet 中提出的 cache 策略,MMYOLO 目前也已经实现了两种功能的 mosaic 了。
3.2 可定制插件的网络模块
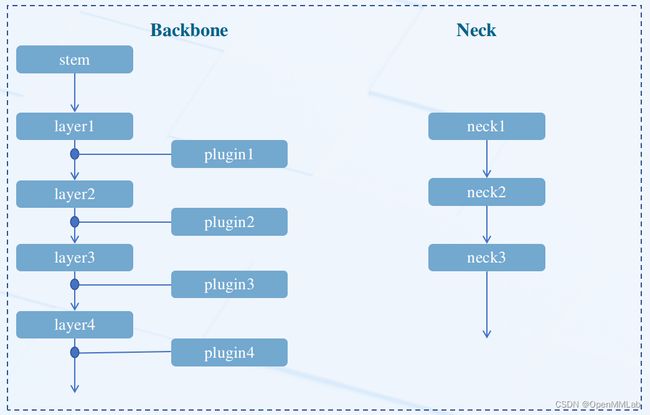
上图为可定制插件的网络模块图,plugin 即为通过配置可定制的插件。YOLO 系列算法大部分都采用统一的网络搭建模式,例如 DarkNet+PAFPN。
为了方便用户理解网络结构,同时为了能够在基类中提供一些通用功能,MMYOLO 抽象了 BaseBackbone 和 BaseYOLONeck 基类。
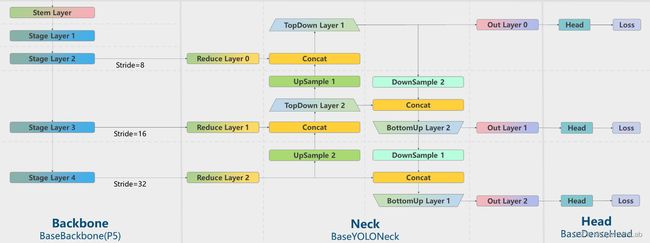
上图为 MMYOLO 中抽象的 BaseBackbone 和 BaseYOLONeck 基类结构图。
抽象 BaseBackbone 的好处包括:
- 子类不需要关心 forward 具体过程,只要类似建造者模式一样构建模型即可
- 子类自动支持 frozen 某些 stage 和 forzen bn 功能,方便用户 fintune
- 支持通过修改配置实现定制插件功能,MMYOLO 在每个 layer 后面预先插入了点位,用户可以很方便地插入一些类似注意力模块
同样地, BaseYOLONeck 也具备上述优点,而且用户可以方便地串联多个 Neck。
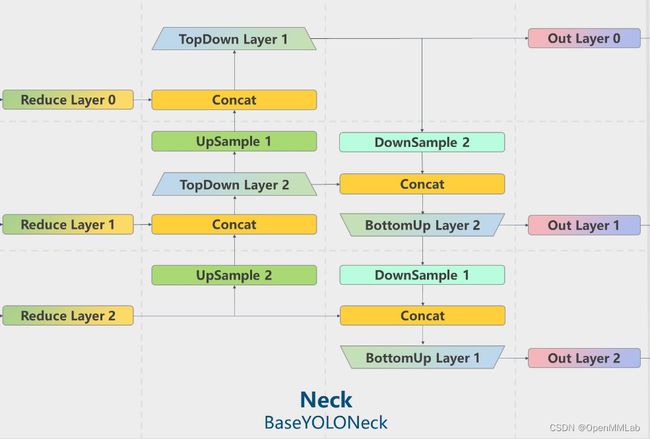
上图为 BaseYOLONeck 结构图。以 YOLOv5 为例,用户可以直接通过修改 config 文件中 backbone 的 plugins 参数来实现对插件的管理。例如为 YOLOv5 增加 MMDetection 中的 GeneralizedAttention 插件,其配置文件如下:
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
model = dict(
backbone=dict(
plugins=[
dict(
cfg=dict(
type='mmdet.GeneralizedAttention',
spatial_range=-1,
num_heads=8,
attention_type='0011',
kv_stride=2),
stages=(False, False, True, True)),
], ))
如果用户想应用多个 Neck,一个比较好的例子是:用户想在 YOLOv5 的 Neck 后面应用 MMDetection 中的具备注意力机制的 DyHead,配置写法为:
_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
model = dict(
type='YOLODetector',
neck=[
dict(
type='YOLOv5PAFPN',
deepen_factor=deepen_factor,
widen_factor=widen_factor,
in_channels=[256, 512, 1024],
out_channels=[256, 512, 1024],
num_csp_blocks=3,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True)),
dict(
type='mmdet.ChannelMapper',
in_channels=[128, 256, 512],
out_channels=128,
),
dict(
type='mmdet.DyHead',
in_channels=128,
out_channels=256,
num_blocks=2
]
详细用法见:https://github.com/open-mmlab/mmyolo/blob/main/docs/zh_cn/advanced_guides/how_to.md
鉴于 OpenMMLab 2.0 优秀的扩展机制,用户可以轻松修改配置文件来组合各类 YOLO 算法组件,快速实现魔改和自定义需求。如果你本身就是 OpenMMLab 的用户,那么 MMYOLO 用起来就会更加事半功倍了。
3.3 丰富的入门和进阶教程
前面说过文档也是 MMYOLO 中一个重点建设的模块,为此在已经开源的 MMYOLO 中,我们已经提供了诸多文档教程,典型的如下:
- 学习 YOLOv5 配置文件
- YOLOv5 从入门到部署全流程
- 模型设计相关说明
- YOLOv5 原理和实现全解析
- RTMDet 原理和实现全解析
- 特征图可视化
- How-to 教程
需要特别强调的是由于 MMYOLO 中抽象了 BaseBackbone 和 BaseYOLONeck,因此我们可以方便快速且采用统一风格对已经复现的算法网络结构进行绘制,进一步方便用户理解。典型图如下所示:

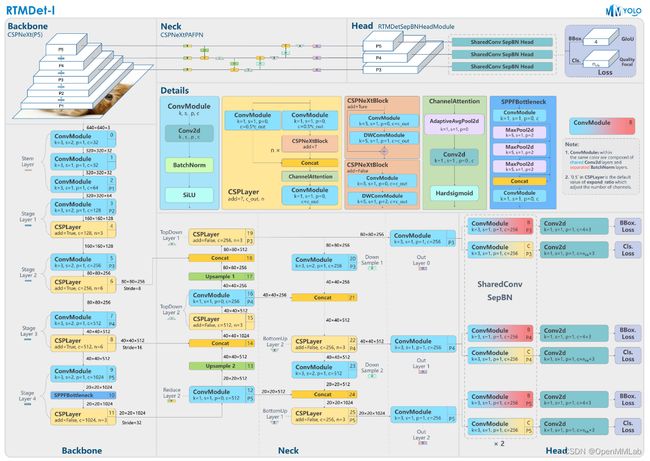
详细内容可以阅读官方文档:https://mmyolo.readthedocs.io/zh_CN/latest/
近期我们也开始录制短视频来介绍 MMYOLO 中的功能,详情见 https://github.com/open-mmlab/OpenMMLabCourse/blob/main/mmyolo.md。
我们也会不断地新增其他必备文档,希望社区小伙伴可以一起参与!
3.4 高效透明的社区协作
YOLO 系列算法本身用户基数非常大,MMYOLO 作为一个以社区为主导的算法库,还承担着探索更高效透明的社区协作模式的任务。在 MMYOLO 的开发和维护过程中,会采用如下方式进行协作开发:
- 邀请贡献突出的社区开发者参与到项目的管理和规划
- 任务和计划更加公开更加透明
- 以社区需求为主导
MMYOLO 目前已经给部分社区核心贡献者开通了 writer 权限来共同推动仓库建设,同时开发任务和计划都已经公开了。我们希望 MMYOLO 能够以社区所提需求为主导,邀请更多的社区小伙伴来共同参与。
4 总结
MMYOLO 定位于 YOLO 系列核心热门开源库以及工业应用核心库,现在还处于早期开发快速迭代阶段,目前很多功能还不太完善,迫切需要各位热心小伙伴们的参与!
如果你对 MMYOLO 有任何疑问或者参与兴趣,不管是代码、文档还是参与讨论等方面,都可以直接联系管理员,希望能邀请更多的社区人员共同建设更好的 MMYOLO!
想了解更多 MMYOLO 相关内容,欢迎查看回放视频 https://www.bilibili.com/video/BV19e4y1674D
5 后续规划
截止到目前为止,MMYOLO 已经实现 YOLOv5/YOLOX/RTMDet 的训练推理和 VOC 数据集在 YOLOv5 中的支持,并同步推出了原理和实现解析文档。近期开发计划包括但不限于:
- 支持 YOLOv6/PPYOLOE/YOLOv7 的训练和推理
- 支持实例分割和旋转框检测
- 支持已支持算法的部署
- 相应算法的原理和实现解析文档
- 相关脚本开发和推广视频制作等等
Roadmap 开发计划见 https://github.com/open-mmlab/mmyolo/issues/136,欢迎大家提 Issue 或者 PR,如果有任何疑问也可以直接联系管理员。
有你的参与,MMYOLO 会做 得 更好!