Q-Learning的学习及简单应用
强化学习(Reinforcement Learning)是一种机器学习算法,强调如何基于环境而行动,以取得最大化的预期利益,在机器人领域应用较为广泛。Q-Learning属于强化学习的经典算法,用于解决马尔可夫决策问题。
马尔可夫决策过程(Markov Decision Processes,MDP)
强化学习研究的问题都是基于马尔可夫决策过程的,分为有限马尔可夫决策过程和无限马尔可夫决策过程。这里主要介绍有限马尔可夫决策过程。
马尔可夫性质:根据每个时刻观察到的状态,从可用的行动集合中选用一个行动作出决策,系统下一步(未来)的状态是随机的,并且其下一步状态与历史状态无关。
马尔可夫决策过程可以描述为:一个机器人(agent)通过采取行动(action)改变自身状态(state),与环境(E)互动得到回报(Reward)。目的是通过一定的行动策略(π)获得最大回报。它有5个元素构成:
S:所有可能的状态的集合(元素可能会很多,设计的时候需要合并或舍弃)
A:在状态S下可以做出的行为
p:Pa(S, S'),表示在a行为下t时刻状态S转化为t+1时刻状态S'的概率
Gamma:衰减变量,距离当前时刻t越远的回报R对当前决策的影响越小,避免在无限时间序列中导致的无偏向问题
V:衡量策略(π)的价值,与当前立即回报以及未来预期回报有关,v(S) = E [U|St],U = R(t+1)+Gamma*R(t+2)+Gamma^2*R(t+3)...,其中R(t+n)表示在t+n时刻的回报
一个例子:k-armed bandit
假设有一台赌博机,一共有k个扳手,按下每个扳手的得奖概率不相同。如何用最少的次数,确定回报最大的扳手并得到最多奖励?
一个最简单的思路是每个扳手试验1000次,估算出获奖概率。大量的重复实验可以较为准确地获得接近真实的概率,但效率显然不是最高。
还有一种思路是先每个试验10次,并在之后一直坚持估算概率最高的扳手(Greedy算法),效率提高但所选的扳手可能不是得奖概率最高的。
改进:选择一个比较小的数 ε(如0.1),然后生成一个0~1之间的随机小数,如果该数小于 ε,则随机挑一个目前看来得奖概率不高的扳手,反之,继续坚持目前概率最高的扳手。该算法称为 ε-greedy算法(关于这些算法性能的比较见下图)
另外的思路:UCB算法(Upper Confidence Bound)。对一个扳手的评估:value+sqrt((2 *total_counts) / counts),value是当前得奖概率,sqr((2 *total_counts) / counts)是对这个扳手的了解程度,total_counts总实验次数,counts是对这个扳手的试验次数。在所有的评估中选最大值进行下一次试验。可以看出,如果一个扳手试验次数比较少,则有很高的概率在下一次被选中。该算法避免随机数,每个值都是可以直接计算出来的,可以让没有机会尝试的扳手得到更多的机会。
各算法的效率如图:
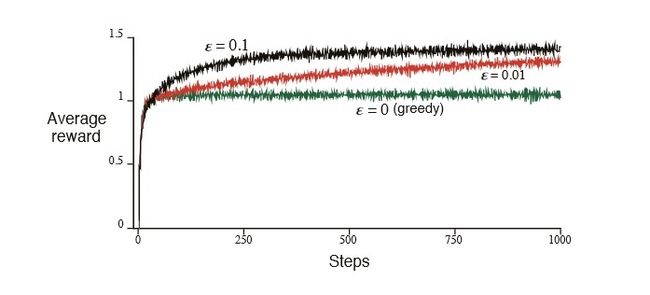
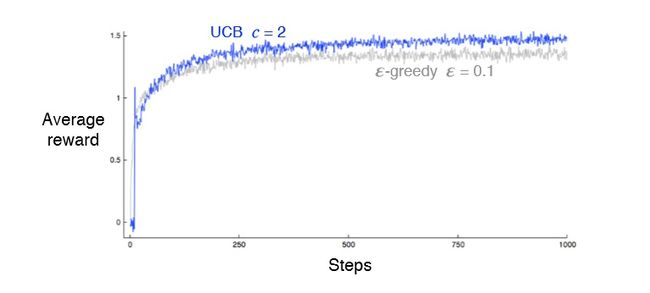
(来源:Reinforcement Learning - An Introduction,CHAPTER 2. MULTI-ARM BANDITS)
以上算法的思想是在exploration和exploitation之间的折衷,在马尔可夫问题中,不可能立刻找到最优的策略,但如何快速收敛是考察问题的重点。
马尔可夫问题求解
主要思想有3类:动态规划(不适用于大型问题),蒙特卡洛方法, Temporal-Difference Learning。其中蒙特卡洛方法与蒙特卡洛搜索树在原理上有相似性,容易被混淆。
Q-Learning属于Temporal-Difference Learning的一种,思想如下:

(来源:Reinforcement Learning - An Introduction,CHAPTER 6. TEMPORAL-DIFFERENCE LEARNING)
其中α是学习率,一般取(0,1)之间的数,学习率越大,收敛速度越快,但可能会导致过拟合问题。Q(S,A)指在状态S下执行A的质量(越大越好)

使用Q-Learning挑战robocode
Robocode 是 IBM 开发的 Java 战斗机器人平台,游戏者可以在平台上设计一个 Java 坦克。每个坦克有个从战场上收集信息的感应器,并且它们还有一个执行动作的传动器。其规则和原理类似于现实中的坦克战斗。(介绍参见http://robocode.sourceforge.net/)
设计思路:
1. 选择States:一共有5个状态分类:当前坦克方位,距离敌方坦克距离,与敌方坦克相对夹角,是否撞墙,是否被击中。其中当前坦克方位每90°算一个状态,距离敌方坦克距离有20个状态(0,100000),与敌方坦克相对夹角有16个状态便于微调,是否撞墙和是否被击中各有两个状态。
2. 选择action:一共6个动作:前进300步;后退300步;左转20°并前进300步;右转20°并前进300步;左转20°并后退300步;右转20°并后退300步
3. Gamma值:0.1
4. 选择ε-greedy算法进行exploration和exploitation的折衷
5. 评分:每射出一个子弹扣分:e.getBullet().getPower();
被子弹击中扣分:e.getBullet().getPower();
撞墙扣分:(Math.abs(getVelocity()) * 0.5 - 1);
撞到敌方坦克扣分:6;
击中敌方坦克加分:e.getBullet().getPower() * 9;
设计简化了坦克炮管的校准和雷达的探测,所以结果不尽如人意,需要继续调整。部分代码如下:
QLRobot负责收集敌方坦克信息控制坦克行动,并对行动结果评分
package robot;
import java.awt.*;
import java.awt.geom.*;
import robocode.*;
import robocode.AdvancedRobot;
public class QLRobot extends AdvancedRobot {
//Q值存储表
private QLTable table;
//在状态state下采取action行为获得的回报
private double reward = 0.0;
//火力值(0,3]
private double firePower;
//方向
private int direction = 1;
//是否撞墙
private int isHitWall = 0;
//是否被击中
private int isHitByBullet = 0;
//存取数据
private Data data = new Data();
//敌方状态
private double distance = 100000;
private long ctime;
private double targetX;
private double targetY;
private double bearing;
private double turnDegree = 20.0;
private double moveDistance = 100.0;
public void run() {
table = data.readData();
setAdjustGunForRobotTurn(true);
setAdjustRadarForGunTurn(true);
turnRadarRightRadians(2 * Math.PI);
while (true) {
robotMovement();
firePower = 50 / distance;
if (firePower > 3)
firePower = 3;
//radarMovement();
if (getGunHeat() == 0) {
setFire(firePower);
}
execute();
}
}
void doMovement() {
if (getTime() % 20 == 0) {
direction *= -1;
setAhead(direction * 300);
}
setTurnRightRadians(bearing + (Math.PI / 2));
}
private void robotMovement() {
int state = getState();
int action = table.selectAction(state);
table.learn(state, action, reward);
reward = 0.0;
isHitWall = 0;
isHitByBullet = 0;
switch (action) {
case 0:
setAhead(moveDistance);
break;
case 1:
setBack(moveDistance);
break;
case 2:
setAhead(moveDistance);
setTurnLeft(turnDegree);
break;
case 3:
setAhead(moveDistance);
setTurnRight(turnDegree);
break;
case 4:
setAhead(moveDistance);
setTurnLeft(turnDegree);
break;
case 5:
setBack(moveDistance);
setTurnLeft(turnDegree);
break;
case 6:
setBack(moveDistance);
setTurnRight(turnDegree);
break;
}
}
private int getState() {
int heading = State.getHeading(getHeading());
int targetDistance = State.getTargetDistance(distance);
int targetBearing = State.getTargetBearing(bearing);
int state = State.Mapping[heading][targetDistance][targetBearing][isHitWall][isHitByBullet];
return state;
}
private void radarMovement() {
double radarOffset;
if (getTime() - ctime > 4) {
radarOffset = 4 * Math.PI;
} else {
radarOffset = getRadarHeadingRadians() - (Math.PI / 2 - Math.atan2(targetY - getY(), targetX - getX()));
radarOffset = NormaliseBearing(radarOffset);
if (radarOffset < 0)
radarOffset -= Math.PI / 10;
else
radarOffset += Math.PI / 10;
}
setTurnRadarLeftRadians(radarOffset);
}
double NormaliseBearing(double ang) {
if (ang > Math.PI)
ang -= 2 * Math.PI;
if (ang < -Math.PI)
ang += 2 * Math.PI;
return ang;
}
double NormaliseHeading(double ang) {
if (ang > 2 * Math.PI)
ang -= 2 * Math.PI;
if (ang < 0)
ang += 2 * Math.PI;
return ang;
}
public void onBulletHit(BulletHitEvent e) {
double change = e.getBullet().getPower() * 9;
reward += change;
}
public void onBulletMissed(BulletMissedEvent e) {
double change = -e.getBullet().getPower();
reward += change;
}
public void onHitByBullet(HitByBulletEvent e) {
double power = e.getBullet().getPower();
double change = -(4 * power + 2 * (power - 1));
reward += change;
isHitByBullet = 1;
}
public void onHitRobot(HitRobotEvent e) {
reward += -6.0;
}
public void onHitWall(HitWallEvent e) {
double change = -(Math.abs(getVelocity()) * 0.5 - 1);
reward += change;
isHitWall = 1;
}
public void onScannedRobot(ScannedRobotEvent e) {
if (e.getDistance() < distance) {
//找到敌人方位
double absbearing = (getHeadingRadians() + e.getBearingRadians()) % (2 * Math.PI);
//旋转到该方位
setTurnLeft(absbearing);
targetX = getX() + Math.sin(absbearing) * e.getDistance();
targetY = getY() + Math.cos(absbearing) * e.getDistance();
bearing = e.getBearingRadians();
ctime = getTime();
distance = e.getDistance();
}
}
public void onWin(WinEvent event) {
data.saveData(table);
}
public void onDeath(DeathEvent event) {
data.saveData(table);
}
}
QLTable负责记录并学习更新Q值,是Q-Learning实现的主要部分
package robot;
import java.io.Serializable;
public class QLTable implements Serializable{
private double[][] table;
//状态数
private final int states = 4 * 20 * 16 * 2 * 2;
//行为数
private final int actions = 7;
//是否是第一次行动
private boolean first = true;
//保存上一次状态
private int lastState;
//保存上一次行为
private int lastAction;
//衰减变量
private double gamma = 0.8;
//学习率
private double e = 0.1;
//探索值
private double exploration = 0.2;
public QLTable() {
table = new double[states][actions];
for (int i = 0; i < states; i++)
for (int j = 0; j < actions; j++)
table[i][j] = 0;
}
//对上个状态采取的action进行反馈
public void learn(int state, int action, double reward) {
if (first)
first = false;
else {
double oldValue = table[lastState][lastAction];
double newValue = (1 - e) * oldValue + e * (reward + gamma * getMaxValue(state));
//更新Q值
table[lastState][lastAction] = newValue;
}
lastState = state;
lastAction = action;
}
//获得某个state的最大Q值
private double getMaxValue(int state) {
double max = table[state][0];
for (int i = 0; i < actions; i++) {
if (table[state][i] > max)
max = table[state][i];
}
return max;
}
//根据目前的state,选择最合适的action
public int selectAction(int state) {
double qValue;
double sum = 0.0;
double[] value = new double[actions];
for (int i = 0; i < value.length; i++) {
qValue = table[state][i];
//保证为正数,且不改变函数增减性
value[i] = Math.exp(qValue);
sum += value[i];
}
//计算P(a|s)
if (sum != 0) {
for (int i = 0; i < value.length; i++) {
value[i] /= sum;
}
} else
return getBestAction(state);
int action = 0;
double cumProb = 0.0;
double randomNum = Math.random();
//大于探索值进行探索
if (randomNum < exploration) {
//保证每一种action都探索到
while (randomNum > cumProb && action < value.length) {
cumProb += value[action];
action++;
}
return action - 1;
} else {
//greedy
return getBestAction(state);
}
}
//获得最优action
private int getBestAction(int state) {
double max = table[state][0];
int action = 0;
for (int i = 0; i < actions; i++) {
if (table[state][i] > max) {
max = table[state][i];
action = i;
}
}
return action;
}
}
实战结果如下:
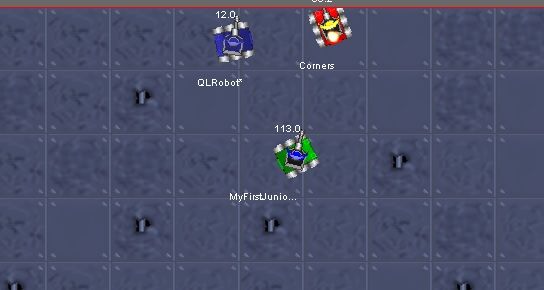

结果分析:在训练次数较少的情况下(10次)结果并不理想,另外炮管和雷达的角度修正出现比较严重的偏差,需要继续调整。对于较大训练次数的情况有待于后续观察