torch.utils.data.DataLoader中的collate_fn的使用
参考链接: class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None)
补充链接: 自定义torch.utils.data中的Dataset,并使用DataLoader自动加载
词语释义:



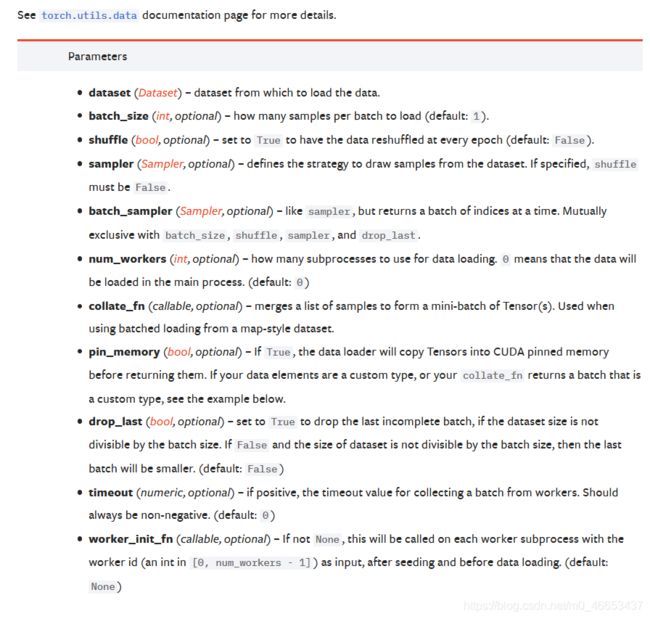

功能:
以自定义的方式将加载的多项数据组织成一个mini-batch,比如加载成numpy多维数组的方式。
在collate_fn中将数据集中的多项数据组织成批,比如将多个numpy小数组组合成一个大的numpy数组:
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license()" for more information.
>>> import numpy as np
>>> a = np.array([0,1,2])
>>> b = np.array([3,4,5])
>>> c = np.array([6,7,8])
>>> ls = [a,b,c]
>>> a
array([0, 1, 2])
>>> b
array([3, 4, 5])
>>> c
array([6, 7, 8])
>>> ls
[array([0, 1, 2]), array([3, 4, 5]), array([6, 7, 8])]
>>> result = np.array(ls)
>>> result
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> np.array(ls)
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>>
>>>
使用示例1:
def ssd_dataset_collate(batch):
# print('ssd_dataset_collate函数被执行...')
images = []
bboxes = []
for img, box in batch:
images.append(img)
bboxes.append(box)
images = np.array(images)
bboxes = np.array(bboxes)
return images, bboxes
gen = DataLoader(train_dataset, \
batch_size=Batch_size, \
num_workers=8, \
pin_memory=True,\
drop_last=True, \
collate_fn=ssd_dataset_collate)
# collate_fn=None)
使用示例2:
# DataLoader中collate_fn使用
def deeplab_dataset_collate(batch):
images = []
pngs = []
seg_labels = []
for img, png, labels in batch:
images.append(img)
pngs.append(png)
seg_labels.append(labels)
images = np.array(images)
pngs = np.array(pngs)
seg_labels = np.array(seg_labels)
return images, pngs, seg_labels
train_dataset = DeeplabDataset(train_lines, inputs_size, NUM_CLASSES, True)
val_dataset = DeeplabDataset(val_lines, inputs_size, NUM_CLASSES, False)
gen = DataLoader(train_dataset, batch_size=Batch_size, num_workers=2, pin_memory=True,
drop_last=True, collate_fn=deeplab_dataset_collate)
gen_val = DataLoader(val_dataset, batch_size=Batch_size, num_workers=2,pin_memory=True,
drop_last=True, collate_fn=deeplab_dataset_collate)
train_dataset = DeeplabDataset(train_lines, inputs_size, NUM_CLASSES, True)
val_dataset = DeeplabDataset(val_lines, inputs_size, NUM_CLASSES, False)
gen = DataLoader(train_dataset, batch_size=Batch_size, num_workers=4, pin_memory=True,
drop_last=True, collate_fn=deeplab_dataset_collate)
gen_val = DataLoader(val_dataset, batch_size=Batch_size, num_workers=4,pin_memory=True,
drop_last=True, collate_fn=deeplab_dataset_collate)
实验代码:
# 定义一个标准的用户定制Dataset模板
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class Dataset4cxq(Dataset):
def __init__(self, datum,length):
self.datum = datum
self.length = length
def __len__(self):
return self.length
def __getitem__(self, index):
if type(index) != type(2) and type(index) != (slice):
raise TypeError('索引类型错误,程序退出...')
# index 是单个数
if type(index) == type(2):
if index >= self.length or index < -1 * self.length:
# print("索引越界,程序退出...")
raise IndexError("索引越界,程序退出...")
elif index < 0:
index = index + self.length
sample4cxq, label4cxq = self.datum[index]
return sample4cxq, label4cxq
# index 是切片
elif type(index) == slice:
sample4cxq = list(item[0] for item in self.datum[index])
label4cxq = list(item[1] for item in self.datum[index])
return sample4cxq, label4cxq
if __name__ == "__main__":
cities = tuple([
("0浙江省0","0杭州市0"),
("1广东省1","1广州市1"),
("2福建省2","2福州市2"),
("3江苏省3","3南京市3"),
("4河北省4","4石家庄市4"),
("5河南省5","5郑州市5"),
("6山东省6","6济南市6"),
("7山西省7","7太原市7")
])
print('\n')
# print('pirnt tuple variable cities...')
# print(cities)
print("creating dataset".center(50,'-'))
my_dataset = Dataset4cxq(cities, len(cities))
print("数据集的长度:",len(my_dataset))
print('\n'+ "iteration in DataLoader".center(50,'-'))
dataloader4cxq = torch.utils.data.DataLoader(
dataset=my_dataset,
batch_size=2,
shuffle=True # True False
)
for cnt, data in enumerate(dataloader4cxq, 20200910):
# pass
sample4cxq, label4cxq = data
print('sample4cxq的类型: ',type(sample4cxq),'\tlabel4cxq的类型: ',type(label4cxq))
print('迭代次数:', cnt, ' sample4cxq:', sample4cxq, ' label4cxq:', label4cxq)
print('\n'+ "using collate_fn".center(50,'-'))
def collate_fn4cxq(batch):
samples = []
labels = []
for sample4cxq, label4cxq in batch:
samples.append(sample4cxq)
labels.append(label4cxq)
samples = np.array(samples)
labels = np.array(labels)
return samples, labels
dataloader4cxq = torch.utils.data.DataLoader(
dataset=my_dataset,
batch_size=3,
# batch_size=2,
drop_last=True,
# drop_last=False,
shuffle=True, # True False
# shuffle=False, # True False
collate_fn=collate_fn4cxq,
# collate_fn=None,
)
print('使用collate_fn参数...\n')
for cnt, data in enumerate(dataloader4cxq, 0):
# pass
sample4cxq, label4cxq = data
print('sample4cxq的类型: ',type(sample4cxq),'\tlabel4cxq的类型: ',type(label4cxq))
print('迭代次数:', cnt, ' sample4cxq:', sample4cxq, ' label4cxq:', label4cxq)
控制台下输出:
Windows PowerShell
版权所有 (C) Microsoft Corporation。保留所有权利。
尝试新的跨平台 PowerShell https://aka.ms/pscore6
加载个人及系统配置文件用了 945 毫秒。
(base) PS C:\Users\chenxuqi\Desktop\News4cxq> & 'D:\Anaconda3\python.exe' 'c:\Users\chenxuqi\.vscode\extensions\ms-python.python-2021.1.502429796\pythonFiles\lib\python\debugpy\launcher' '55416' '--' 'c:\Users\chenxuqi\Desktop\News4cxq\新建文本文档.py'
数据集的长度: 8
-------------iteration in DataLoader--------------
sample4cxq的类型: label4cxq的类型:
迭代次数: 20200910 sample4cxq: ('2福建省2', '1广东省1') label4cxq: ('2福州市2', '1广州市1')
sample4cxq的类型: label4cxq的类型:
迭代次数: 20200911 sample4cxq: ('3江苏省3', '5河南省5') label4cxq: ('3南京市3', '5郑州市5')
sample4cxq的类型: label4cxq的类型:
迭代次数: 20200912 sample4cxq: ('0浙江省0', '6山东省6') label4cxq: ('0杭州市0', '6济南市6')
sample4cxq的类型: label4cxq的类型:
迭代次数: 20200913 sample4cxq: ('7山西省7', '4河北省4') label4cxq: ('7太原市7', '4石家庄市4')
-----------------using collate_fn-----------------
使用collate_fn参数...
sample4cxq的类型: label4cxq的类型:
迭代次数: 0 sample4cxq: ['2福建省2' '0浙江省0' '6山东省6'] label4cxq: ['2福州市2' '0杭州市0' '6济南市6']
sample4cxq的类型: label4cxq的类型:
迭代次数: 1 sample4cxq: ['7山西省7' '1广东省1' '3江苏省3'] label4cxq: ['7太原市7' '1广州市1' '3南京市3']
(base) PS C:\Users\chenxuqi\Desktop\News4cxq> conda activate base
(base) PS C:\Users\chenxuqi\Desktop\News4cxq>
补充说明:
torch.utils.data.DataLoader类的构造函数中,
batch_size参数用于指定一个批batch的长度,即一个batch包含多上数据项.
drop_last参数用于指定是否将最后一个长度不足batch_size的数据项丢弃.
shuffle参数用于是否需要顺序随机地加载的数据集.
collate_fn参数用于是否需要以自定义的方式组织一个batch,
例子中将一个mini-batch的数据组织成numpy.ndarray的类型.
默认情况下collate_fn=None时,数据以元组的方式返回.
以上参数的不同设置效果可以在代码第80到90行中自行设置后,
运行程序,并观察不同输出效果.