【线性回归——从简单构建到实现数据预测】
深度学习与神经网络day03-线性回归
- 一、简单的线性回归
-
- 1.1、数据集的构建
- 1.2、模型构建
- 1.3、损失函数
- 1.4、模型优化
- 1.5、模型训练
- 1.6、模型评估
- 1.7、样本数量和正则化系数的影响
- 二、多项式回归
-
- 1.1、数据集的构建
- 1.2、模型构建
- 1.5、模型训练
- 1.6、模型评估
- 三、尝试封装Runner类
- 四、基于线性回归的波士顿房价预测
-
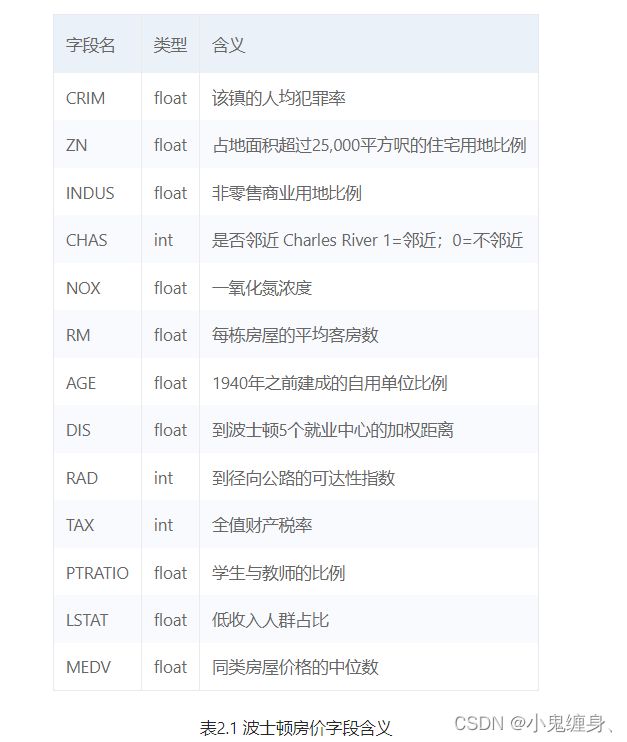
- 4.1数据集介绍
- 4.2数据清洗
-
- 4.2.1缺失值分析
- 4.2.2异常值处理
- 4.3数据集的划分
- 4.4特征工程
- 4.5模型构建
- 4.6完善Runner类
- 4.7模型训练
- 4.8 模型预测
- 后话:一些问题
一、简单的线性回归
1.1、数据集的构建
我们知道线性回归要实现的方程式为:
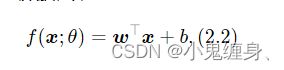
我们通过一个简单的函数linear_func来实现我们的一个简单的线性回归,并由此扩展到多个特征的线性回归模型。
linear_func是一个可以构建构建输入特征和输出标签的维度都为1的数据集函数。
def linear_func(x,w=1.2,b=0.5):
y = w*x + b
return y
function:接下来构造产生数据集的函数,函数随机产生一个num_data行1列的随机数据集,并由linear_func确定标签值并添加噪声值,从而使得数据集符合现实生活中并不那么完美的线性回归。
import torch
def one_feature_data(func,random_x,num_data,noise=0.0,add_outlier=False,outlier_ratio=0.001):
"""
函数功能:根据给定的函数来生成简单的数据集
输入:
- func: 函数
- random_x: x的取值范围(list)
- num_data: 生成的数据集个数
- noise: 添加噪声的大小,默认为0
- add_outlier: 是否添加异常点,默认为False
- outlier_ratio: 异常值占比
输出:
- X: 特征数据,shape=[num_data,1]
- Y: 标签数据,shape=[num_data,1]
"""
#首先生成num_data个随机数,范围在random_x之间
X = torch.rand(shape=[num_data])*(random_x[1]-random_x[0])+random_x[0]
#产生Y
Y=func(X)
#生成高斯分布的标签噪声,使标签不完美。
#用np.random.normal实现num_data个噪声点,0为均值,noise标准差的数据
noise_Y = np.random.normal(0,noise,torch.tensor(num_data))
Y = Y + noise_Y
#查看异常值是否添加
if add_outlier:
#计算异常值个数
outlier_num = int(num_data*outlier_ratio)
#查看异常值个数是都为0
if outlier_num!=0:
#使用torch.randint生成在num_data个数下的outlier_num个异常值的位置
outlier_id = torch.randint(num_data,shape=[outlier_num])
#将选出的几个异常位置的数据进行异常处理
Y[outlier_id] = Y[outlier_id]*5
return X,Y
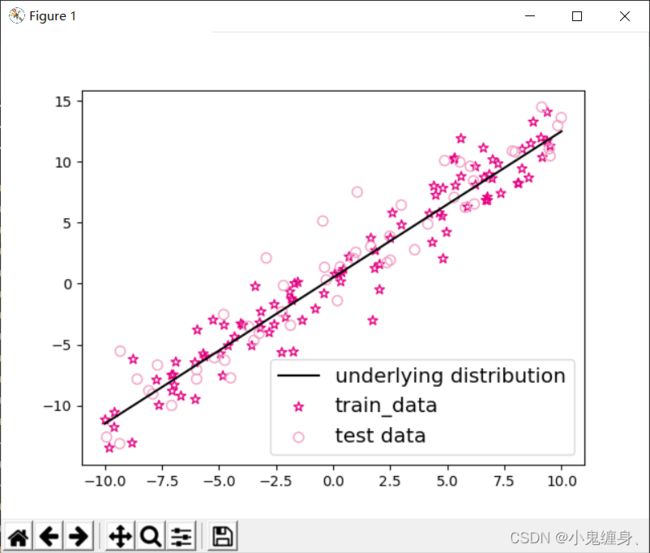
function:我们对上述的数据集进行训练样本和测试样本的可视化,并对标准线进行绘图,从而知道我们要拟合的标准线。
import matplotlib.pyplot as plt
#设置参数
func = linear_func
random_x = [-10,10]
train_num = 100 #训练样本的数目
test_num = 50 #测试样本的数目
noise = 2
#生成训练集和测试集
X_train,Y_train = one_feature_data(func,random_x,num_data=train_num,noise=noise)
print(X_train)
print(Y_train)
X_test,Y_test = one_feature_data(func,random_x,num_data=test_num,noise=noise)
#生成一个大数据集
X_train_large,Y_train_large = one_feature_data(func,random_x,num_data=5000,noise=noise)
#生成之前的标准线
X_underlying = torch.linspace(random_x[0],random_x[1],train_num)
Y_underlying = linear_func(X_underlying)
#数据的可视化
plt.scatter(X_train,Y_train,marker='*',facecolor="none",edgecolor='#e4007f',s=50,label="train_data")
plt.scatter(X_test, Y_test, facecolor="none", edgecolor='#f19ec2', s=50, label="test data")
plt.plot(X_underlying, Y_underlying, c='#000000', label=r"underlying distribution")
plt.legend(fontsize='x-large') # 给图像加图例
plt.savefig('ml-vis.pdf') # 保存图像到PDF文件中
plt.show()
可视化:
1.2、模型构建
我们根据:Y=WX + b来构建最基本的式子:
#实现线性模型的通式,利用张量运算来实现
# X: tensor, shape=[N,D]
# Y: tensor, shape=[N]
# w: shape=[D,1]
# b: shape=[1]
Y = torch.matmul(X,w)+b
接下来我们尝试创建一个自己的Linear类来实现线性回归迭代的实现。
创建如下模型:
import torch
torch.manual_seed(10)
# 线性算子
class Linear():
def __init__(self, feature_size):
"""
输入:
- feature_size: 特征向量维度的大小
"""
self.feature_size = feature_size
# 模型参数
self.params = {}
self.params['w'] = torch.randn([self.feature_size,1],dtype=torch.float32)
self.params['b'] = torch.zeros([1], dtype=torch.float32)
def __call__(self, X):
return self.forward(X)
def forward(self, X):
"""
输入:
- X:tensor,shape=[N,D]
"""
N, D = X.shape
# 验证输入特征数是否为0
if self.feature_size == 0:
return torch.full([N, 1], float(self.params['b']))
# 验证数据的合法性
assert D == self.feature_size
# 使用torch.matmul()计算两个tensor的乘积
Y = torch.matmul(X, self.params['w']) + self.params['b']
return Y
feature_size = 5
N = 2
X = torch.randn([N, feature_size], dtype=torch.float32)
model = Linear(feature_size)
Y = model(X)
print("y_predict:", Y)
我们对刚建立的预测模型进行最基本的测试,首先生成一个2行5列的随机矩阵,然后传入feature_size=5即5个特征的数据,从而对模型进行一次训练得到预测模型,然后传入这个2行5列的矩阵从而传入得到2个预测值。
预测结果如下:

1.3、损失函数
回归任务是对连续值的预测,希望模型能根据数据的特征输出一个连续值作为预测值。因此回归任务中常用的评估指标是均方误差。
其中均方误差没有除2。
均方误差 的定义为:
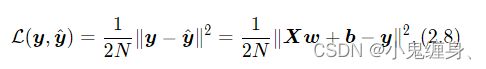
均方误差的函数表示为:
import torch
def mean_squared_error(y_label,y_predict):
"""
:param y_label: 样本真实标签
:param y_predict: 样本预测标签
:return error: 误差值
"""
assert y_label.shape[0] == y_predict.shape[0]
#torch.square计算输入的平方值
#torch.mean沿axis方向做均值处理,默认axis为None,则对输入的全部元素计算平均值
error = torch.mean(torch.square(y_predict - y_label))
return error
我们采用一个简单的样例对该函数进行测试,确保函数的正确性。
#构造一个简单的样例对函数进行测试
y_label = torch.tensor([[-0.2],[4.9]],dtype=torch.float64)
y_predict = torch.tensor([[1.3],[2.5]],dtype=torch.float64)
error = mean_squared_error(y_label,y_predict).item()
print("error:",error)
测试结果:

1.4、模型优化
采用经验风险最小化,线性回归可以通过最小二乘法求出参数w和b的解析解。
最小二乘法 建立的最优解为:
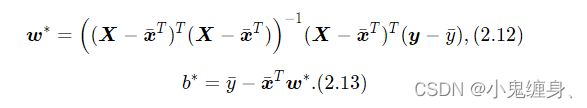
建立模型优化器(最小二乘法)的函数如下:
def optimizer_lsm(model, X, y, reg_lamda=0):
"""
输入:
- model: 模型
- X: tensor, 特征数据,shape=[N,D]
- y: tensor,标签数据,shape=[N]
- reg_lambda: float, 正则化系数,默认为0
输出:
- model: 优化好的模型
"""
N, D = X.shape
# 对输入特征数据所有特征向量求平均值(对于二维矩阵,axis=0表示对每列求均值)
x_bar_tran = torch.mean(X, dim=0).T
# 求标签的均值,shape=[1]
y_bar = torch.mean(y)
# torch.subtract通过广播的方式实现矩阵减向量
x_sub = torch.subtract(X, x_bar_tran)
# 使用torch.all判断输入tensor是否全0
if torch.all(x_sub == 0):
model.params['b'] = y_bar
model.params['w'] = torch.zeros([D])
return model
# torch.inverse求方阵的逆
tmp = torch.inverse(torch.matmul(x_sub.T, x_sub) + reg_lambda * torch.eye((D)))
#最小二乘法求w
w = torch.matmul(torch.matmul(tmp, x_sub.T), (y - y_bar))
#最小二乘法求b
b = y_bar - torch.matmul(x_bar_tran, w)
model.params['b'] = b
model.params['w'] = torch.squeeze(w, dim=-1)
#返回优化好的模型
return model
1.5、模型训练
我们已经建立好了模型,并且提到了损失函数,也有了模型优化器,接下来对我们已经建立好的模型进行求解。
#小数据集的模型训练
input_size = 1
model = Linear(input_size)
model = optimizer_lsm(model,X_train.reshape([-1,1]),Y_train.reshape([-1,1]))
print("w_pred:",model.params['w'].item(), "b_pred: ", model.params['b'].item())
#求训练集的误差为
y_train_pred = model(X_train.reshape([-1,1])).squeeze()
train_error = mean_squared_error(Y_train, y_train_pred).item()
print("train error: ",train_error)
训练结果:

#打的数据集进行训练
X_train_large, y_train_large = one_feature_data(func=linear_func, num_data = 5000,random_x=random_x, noise = 2,)
model_large = Linear(input_size)
model_large = optimizer_lsm(model_large,X_train_large.reshape([-1,1]),y_train_large.reshape([-1,1]))
print("w_pred large:",model_large.params['w'].item(), "b_pred large: ", model_large.params['b'].item())
#求误差
y_train_pred_large = model_large(X_train_large.reshape([-1,1])).squeeze()
train_error_large = mean_squared_error(y_train_large, y_train_pred_large).item()
print("train error large: ",train_error_large)
训练结果:

1.6、模型评估
我们对用训练集训练过了的模型进行测试,来表达模型的性能,测试程序如下:
#小数据集进行评估
y_test_pred = model(X_test.reshape([-1,1])).squeeze()
test_error = mean_squared_error(Y_test, y_test_pred).item()
print("test error: ",test_error)
#大数据集进行评估
y_test_pred_large = model_large(X_test.reshape([-1,1])).squeeze()
test_error_large = mean_squared_error(Y_test, y_test_pred_large).item()
print("test error large: ",test_error_large)
评估结果:

1.7、样本数量和正则化系数的影响
(1) 调整训练数据的样本数量,由 100 调整到 5000,观察对模型性能的影响。
解: 当样本数量较小时,容易受到个别点的扰动,对于不同的数据集,实验结果产生误差的可能性更大,模型性能较好。
当样本数量较大时,不容易受到个别样本的扰动,对于不同的数据集,实验结果的误差基本平衡,模型性能较好。
(2) 调整正则化系数,观察对模型性能的影响。
解: 正则化系数过大,导致了参数被过度正则化,特征参数趋近于0,导致了欠拟合。
正则化系数过小,而训练样本的进一步加大,会使参数的数目增多,导致模型的过拟合。
正则化系数在一定范围内调整时,会使模型的拟合效果编号
二、多项式回归
1.1、数据集的构建
导入我们所需要的一些库:
import math
import torch
from matplotlib import pyplot as plt
import numpy as np
由于是学习多项式回归,所以在此我们假设我们要拟合的非线性函数为一个缩放后的sin函数。
# sin函数: sin(2 * pi * x)
def sin(x):
y = torch.sin(2 * math.pi * x)
return y
通线性回归一样的,我们生成数据:
def one_feature_data(func, random_x, num_data, noise=0.0, add_outlier=False, outlier_ratio=0.001):
"""
函数功能:根据给定的函数来生成简单的数据集
输入:
- func: 函数
- random_x: x的取值范围(list)
- num_data: 生成的数据集个数
- noise: 添加噪声的大小,默认为0
- add_outlier: 是否添加异常点,默认为False
- outlier_ratio: 异常值占比
输出:
- X: 特征数据,shape=[num_data,1]
- Y: 标签数据,shape=[num_data,1]
"""
# 首先生成num_data个随机数,范围在random_x之间
X = torch.rand([num_data]) * (random_x[1] - random_x[0]) + random_x[0]
# 产生Y
Y = func(X)
# 生成高斯分布的标签噪声,使标签不完美。
# 用np.random.normal实现num_data个噪声点,0为均值,noise标准差的数据
noise_Y = torch.tensor(np.random.normal(0, noise, torch.tensor(Y.shape[0])))
Y = Y + noise_Y
# 查看异常值是否添加
if add_outlier:
# 计算异常值个数
outlier_num = int(num_data * outlier_ratio)
# 查看异常值个数是都为0
if outlier_num != 0:
# 使用torch.randint生成在num_data个数下的outlier_num个异常值的位置
outlier_id = torch.randint(num_data, [outlier_num])
# 将选出的几个异常位置的数据进行异常处理
Y[outlier_id] = Y[outlier_id] * 5
return X, Y
# 生成数据
func = sin
interval = (0, 1)
train_num = 15
test_num = 10
noise = 0.5 # 0.1
X_train, y_train = one_feature_data(func=func, random_x=interval, num_data=train_num, noise=noise)
X_test, y_test = one_feature_data(func=func, random_x=interval, num_data=test_num, noise=noise)
X_underlying = torch.linspace(interval[0], interval[1], steps=100)
y_underlying = sin(X_underlying)
# 绘制图像
plt.rcParams['figure.figsize'] = (8.0, 6.0)
plt.scatter(X_train, y_train, facecolor="none", edgecolor='#e4007f', s=50, label="train data")
# plt.scatter(X_test, y_test, facecolor="none", edgecolor="r", s=50, label="test data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")
plt.legend(fontsize='x-large')
plt.savefig('ml-vis2.pdf')
plt.show()
我们对数据可视化,画出标准的sinx图,然后将训练样本可视化,从而确定数据点在标准线上下波动:
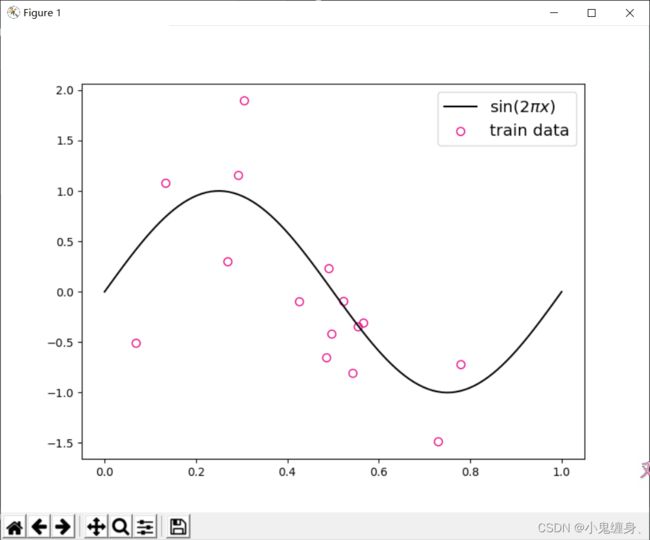
1.2、模型构建
我们实现多项式基函数polynomial_basis_function对原始特征x进行转换。
多项式回归如下:
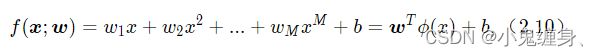
我们建立如下函数来实现上式:
我们首先建立输入序列的多项式转化:
# 多项式转换
def polynomial_basis_function(x, degree=2):
"""
输入:
- x: tensor, 输入的数据,shape=[N,1]
- degree: int, 多项式的阶数
example Input: [[2], [3], [4]], degree=2
example Output: [[2^1, 2^2], [3^1, 3^2], [4^1, 4^2]]
注意:本案例中,在degree>=1时不生成全为1的一列数据;degree为0时生成形状与输入相同,全1的Tensor
输出:
- x_result: tensor
"""
if degree == 0:
return torch.ones(size=x.shape, dtype=torch.float32)
x_tmp = x
x_result = x_tmp
for i in range(2, degree + 1):
x_tmp = torch.multiply(x_tmp, x) # 逐元素相乘
x_result = torch.cat((x_result, x_tmp), dim=-1)
return x_result
# 简单测试
data = [[2], [3], [4]]
X = torch.tensor(data=data, dtype=torch.float32)
degree = 3
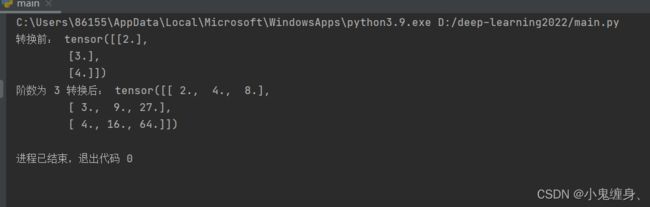
transformed_X = polynomial_basis_function(X, degree=degree)
print("转换前:", X)
print("阶数为", degree, "转换后:", transformed_X)
转化结果图:
1.5、模型训练
转化后的多项式,即变成了一特征属性,我们可以采用线性回归的方式来进行训练。
plt.rcParams['figure.figsize'] = (12.0, 8.0)
for i, degree in enumerate([0, 1, 3, 8]): # []中为多项式的阶数
model = Linear(degree)
X_train_transformed = polynomial_basis_function(X_train.reshape([-1, 1]), degree)
X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1, 1]), degree)
model = optimizer_lsm(model, X_train_transformed, y_train.reshape([-1, 1])) # 拟合得到参数
y_underlying_pred = model(X_underlying_transformed).squeeze()
print(model.params)
# 绘制图像
plt.subplot(2, 2, i + 1)
plt.scatter(X_train, y_train, facecolor="none", edgecolor='#e4007f', s=50, label="train data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")
plt.plot(X_underlying, y_underlying_pred, c='#f19ec2', label="predicted function")
plt.ylim(-2, 1.5)
plt.annotate("M={}".format(degree), xy=(0.95, -1.4))
# plt.legend(bbox_to_anchor=(1.05, 0.64), loc=2, borderaxespad=0.)
plt.legend(loc='lower left', fontsize='x-large')
plt.savefig('ml-vis3.pdf')
plt.show()
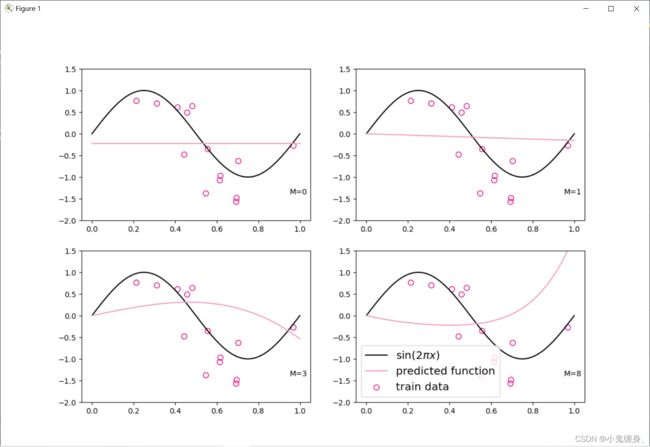
1.6、模型评估
通过均方误差来衡量训练误差、测试误差以及在没有噪音的加入下sin函数值与多项式回归值之间的误差,更加真实地反映拟合结果。多项式分布阶数从0到8进行遍历。
# 训练误差和测试误差
training_errors = []
test_errors = []
distribution_errors = []
# 遍历多项式阶数
for i in range(9):
model = Linear(i)
X_train_transformed = polynomial_basis_function(X_train.reshape([-1, 1]), i)
X_test_transformed = polynomial_basis_function(X_test.reshape([-1, 1]), i)
X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1, 1]), i)
optimizer_lsm(model, X_train_transformed, y_train.reshape([-1, 1]))
y_train_pred = model(X_train_transformed).squeeze()
y_test_pred = model(X_test_transformed).squeeze()
y_underlying_pred = model(X_underlying_transformed).squeeze()
train_mse = mean_squared_error(y_train, y_train_pred).item()
training_errors.append(train_mse)
test_mse = mean_squared_error(y_test, y_test_pred).item()
test_errors.append(test_mse)
# distribution_mse = mean_squared_error(y_true=y_underlying, y_pred=y_underlying_pred).item()
# distribution_errors.append(distribution_mse)
print("train errors: \n", training_errors)
print("test errors: \n", test_errors)
# print ("distribution errors: \n", distribution_errors)
# 绘制图片
plt.rcParams['figure.figsize'] = (8.0, 6.0)
plt.plot(training_errors, '-.', mfc="none", mec='#e4007f', ms=10, c='#e4007f', label="Training")
plt.plot(test_errors, '--', mfc="none", mec='#f19ec2', ms=10, c='#f19ec2', label="Test")
# plt.plot(distribution_errors, '-', mfc="none", mec="#3D3D3F", ms=10, c="#3D3D3F", label="Distribution")
plt.legend(fontsize='x-large')
plt.xlabel("degree")
plt.ylabel("MSE")
plt.savefig('ml-mse-error.pdf')
plt.show()
评估结果:
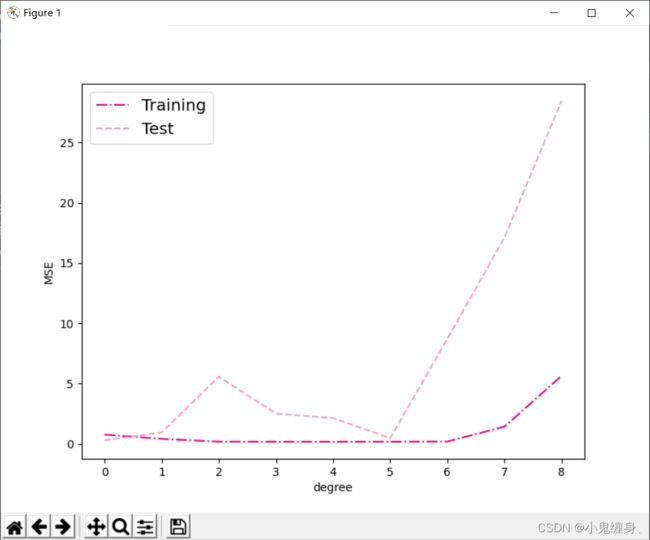
通过观察可视化结果,我们可以得到:
- 当阶数较低的时候,模型的表示能力有限,训练误差和测试误差都很高,代表模型欠拟合
- 当阶数较高的时候,模型表示能力强,但将训练数据中的噪声也作为特征进行学习,一般情况下训练误差继续降低而测试误差显著升高,代表模型过拟合。
对于模型过拟合的情况,可以引入正则化方法,通过向误差函数中添加一个惩罚项来避免系数倾向于较大的取值。
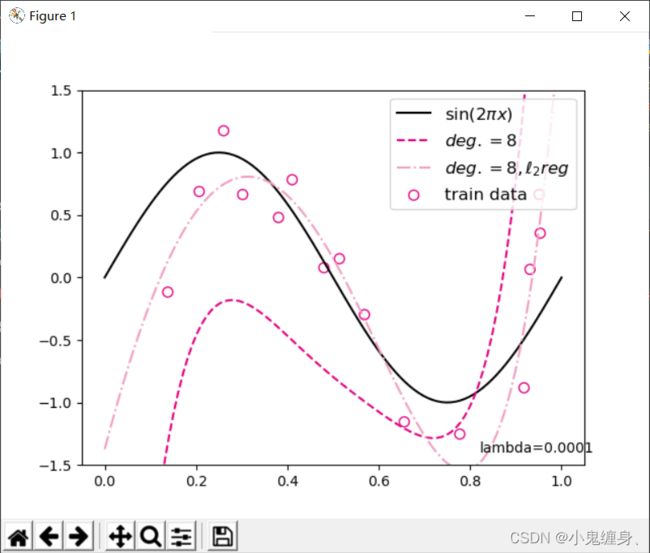
代码如下:
degree = 8 # 多项式阶数
reg_lambda = 0.0001 # 正则化系数
X_train_transformed = polynomial_basis_function(X_train.reshape([-1,1]), degree)
X_test_transformed = polynomial_basis_function(X_test.reshape([-1,1]), degree)
X_underlying_transformed = polynomial_basis_function(X_underlying.reshape([-1,1]), degree)
model = Linear(degree)
optimizer_lsm(model,X_train_transformed,y_train.reshape([-1,1]))
y_test_pred=model(X_test_transformed).squeeze()
y_underlying_pred=model(X_underlying_transformed).squeeze()
model_reg = Linear(degree)
optimizer_lsm(model_reg,X_train_transformed,y_train.reshape([-1,1]),reg_lambda=reg_lambda)
y_test_pred_reg=model_reg(X_test_transformed).squeeze()
y_underlying_pred_reg=model_reg(X_underlying_transformed).squeeze()
mse = mean_squared_error(y_test, y_test_pred).item()
print("mse:",mse)
mes_reg = mean_squared_error(y_test, y_test_pred_reg).item()
print("mse_with_l2_reg:",mes_reg)
# 绘制图像
plt.scatter(X_train, y_train, facecolor="none", edgecolor="#e4007f", s=50, label="train data")
plt.plot(X_underlying, y_underlying, c='#000000', label=r"$\sin(2\pi x)$")
plt.plot(X_underlying, y_underlying_pred, c='#e4007f', linestyle="--", label="$deg. = 8$")
plt.plot(X_underlying, y_underlying_pred_reg, c='#f19ec2', linestyle="-.", label="$deg. = 8, \ell_2 reg$")
plt.ylim(-1.5, 1.5)
plt.annotate("lambda={}".format(reg_lambda), xy=(0.82, -1.4))
plt.legend(fontsize='large')
plt.savefig('ml-vis4.pdf')
plt.show()
评估结果:
三、尝试封装Runner类
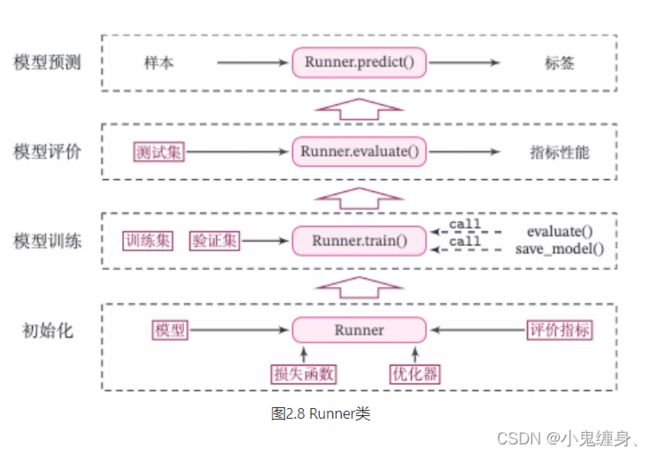
Runner类的成员函数定义如下:
- __init__函数:实例化Runner类,需要传入模型、损失函数、优化器和评价指标等;
- train函数:模型训练,指定模型训练需要的训练集和验证集;
- evaluate函数:通过对训练好的模型进行评价,在验证集或测试集上查看模型训练效果;
- predict函数:选取一条数据对训练好的模型进行预测;
- save_model函数:模型在训练过程和训练结束后需要进行保存;
- load_model函数:调用加载之前保存的模型。
包装Runner类示意图:
包装后的Runner类:
class Runner():
def __init__(self,model,model_loss,model_optimizer,model_evaluate):
self.model = model
self.model_loss = model_loss
self.model_optimizer = model_optimizer
self.model_evaluate = model_evaluate
def train(self,Train_feature,Test_feature,**kwargs):
self.Train_feature = Train_feature
pass
return #各个参数
def evaluate(self,label,**kwargs):
loss = self.model_loss(label,self.predict(self.Train_feature))
# accuracy =
pass
return #返回精度和误差
def predict(self,X,**kwargs):
#用train 的各个参数来对输入序列X进行预测,返回预测值
pass
return #返回预测值
def save_model(self,save_path):
pass
def load_model(self,model_path):
pass
四、基于线性回归的波士顿房价预测
4.1数据集介绍
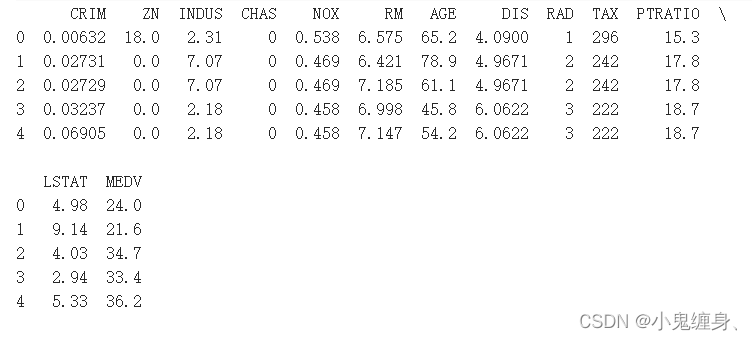
预览一下我们的数据集的前五条数据,看看有没有问题。
import pandas as pd # 开源数据分析和操作工具
# 利用pandas加载波士顿房价的数据集
data=pd.read_csv("C:\\FileRecvboston_house_prices.csv")
# 预览前5行数据
data.head()
预览图:
4.2数据清洗
4.2.1缺失值分析
用isna().sum()各个属性的统计缺失值个数。
data.isna().sum()
分析下图,说明此数据集不存在数据缺失的情况。

4.2.2异常值处理
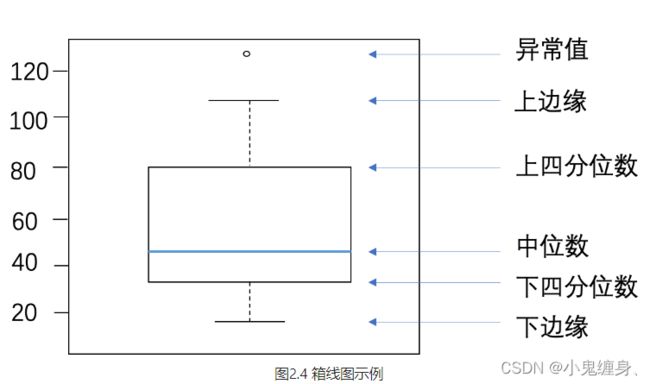
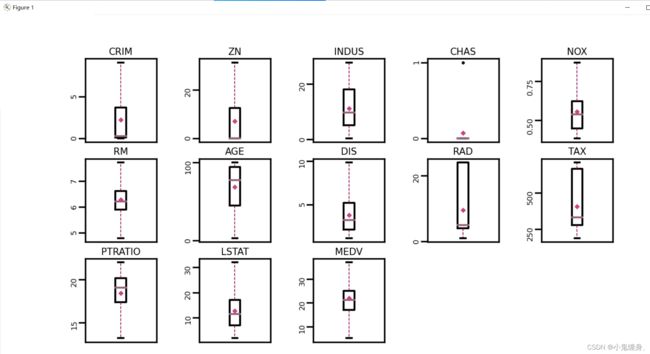
通过箱线图直观的显示数据分布,并观测数据中的异常值。箱线图一般由五个统计值组成:最大值、上四分位、中位数、下四分位和最小值。一般来说,观测到的数据大于最大估计值或者小于最小估计值则判断为异常值,其中:
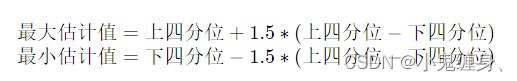
箱线图介绍:
查看数据集各个属性的异常值并可视化的代码:
import matplotlib.pyplot as plt # 可视化工具
import pandas as pd # 开源数据分析和操作工具
# 利用pandas加载波士顿房价的数据集
data=pd.read_csv("C:\\boston_house_prices.csv")
# 预览前5行数据
data.head()
# 查看各字段缺失值统计情况
data.isna().sum()
# 箱线图查看异常值分布
def boxplot(data, fig_name):
# 绘制每个属性的箱线图
data_col = list(data.columns)
# 连续画几个图片
plt.figure(figsize=(5, 5), dpi=300)
# 子图调整
plt.subplots_adjust(wspace=0.6)
# 每个特征画一个箱线图
for i, col_name in enumerate(data_col):
plt.subplot(3, 5, i + 1)
# 画箱线图
plt.boxplot(data[col_name],
showmeans=True,
meanprops={"markersize": 1, "marker": "D", "markeredgecolor": "#C54680"}, # 均值的属性
medianprops={"color": "#946279"}, # 中位数线的属性
whiskerprops={"color": "#8E004D", "linewidth": 0.4, 'linestyle': "--"},
flierprops={"markersize": 0.4},
)
# 图名
plt.title(col_name, fontdict={"size": 5}, pad=2)
# y方向刻度
plt.yticks(fontsize=4, rotation=90)
plt.tick_params(pad=0.5)
# x方向刻度
plt.xticks([])
plt.savefig(fig_name)
plt.show()
boxplot(data, 'ml-vis5.pdf')
可视化结果:
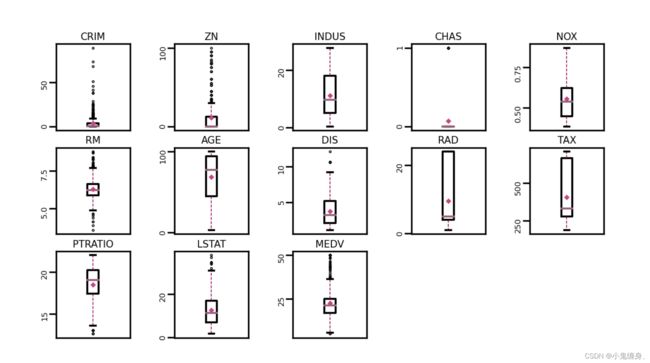
由图可以直观的看出,数据中存在很多的异常值,即超出上下两条杠的部分中的黑圆圈,我们将这些异常值认为是数据集中的“噪声”,并将临界值取代噪声点,从而完成对数据集异常值的处理。
替换代码:
# 四分位处理异常值
num_features = data.select_dtypes(exclude=['object', 'bool']).columns.tolist()
for feature in num_features:
if feature == 'CHAS':
continue
Q1 = data[feature].quantile(q=0.25) # 下四分位
Q3 = data[feature].quantile(q=0.75) # 上四分位
IQR = Q3 - Q1
top = Q3 + 1.5 * IQR # 最大估计值
bot = Q1 - 1.5 * IQR # 最小估计值
values = data[feature].values
values[values > top] = top # 临界值取代噪声
values[values < bot] = bot # 临界值取代噪声
data[feature] = values.astype(data[feature].dtypes)
# 再次查看箱线图,异常值已被临界值替换(数据量较多或本身异常值较少时,箱线图展示会不容易体现出来)
boxplot(data, 'ml-vis6.pdf')
取代后的箱线图:
4.3数据集的划分
将数据集划分为两份:训练集和测试集,不包括验证集。
使用下边的代码进行划分:
import torch
torch.manual_seed(10)
# 划分训练集和测试集
def train_test_split(X, y, train_percent=0.8):
n = len(X)
shuffled_indices = torch.randperm(n) # 返回一个数值在0到n-1、随机排列的1-D Tensor
train_set_size = int(n * train_percent)
train_indices = shuffled_indices[:train_set_size]
test_indices = shuffled_indices[train_set_size:]
X = X.values
y = y.values
X_train = X[train_indices]
y_train = y[train_indices]
X_test = X[test_indices]
y_test = y[test_indices]
return X_train, X_test, y_train, y_test
X = data.drop(['MEDV'], axis=1)
y = data['MEDV']
X_train, X_test, y_train, y_test = train_test_split(X, y) # X_train每一行是个样本,shape[N,D]
4.4特征工程
为了消除纲量对数据特征之间影响,在模型训练前,需要对特征数据进行归一化处理,将数据缩放到[0, 1]区间内,使得不同特征之间具有可比性。
import torch
X_train = torch.tensor(X_train,dtype=torch.float32)
X_test = torch.tensor(X_test,dtype=torch.float32)
y_train = torch.tensor(y_train,dtype=torch.float32)
y_test = torch.tensor(y_test,dtype=torch.float32)
X_min = torch.min(X_train,dim=0)
X_max = torch.max(X_train,dim=0)
X_train = (X_train-X_min.values)/(X_max.values - X_min.values)
X_test = (X_test-X_min.values)/(X_max.values - X_min.values)
# 训练集构造
train_dataset=(X_train,y_train)
# 测试集构造
test_dataset=(X_test,y_test)
4.5模型构建
首先,实例化一个对象。
关于nndl,我们可以不用这个包,可以用我们上边自己写的Linear类,从而进行一样的操作,也能得到结果。
from nndl.op import Linear
# 模型实例化
input_size = 12
model=Linear(input_size)
4.6完善Runner类
我们将之前只有一个外壳的Runner类补充,首先:
import torch.nn as nn
mse_loss = nn.MSELoss()
完整实现如下:
import torch.nn as nn
import torch
import os
from nndl.op import Linear
from nndl.opitimizer import optimizer_lsm
# 模型实例化
input_size = 12
model=Linear(input_size)
mse_loss = nn.MSELoss()
class Runner(object):
def __init__(self, model, optimizer, loss_fn, metric):
# 优化器和损失函数为None,不再关注
# 模型
self.model = model
# 评估指标
self.metric = metric
# 优化器
self.optimizer = optimizer
def train(self, dataset, reg_lambda, model_dir):
X, y = dataset
self.optimizer(self.model, X, y, reg_lambda)
# 保存模型
self.save_model(model_dir)
def evaluate(self, dataset, **kwargs):
X, y = dataset
y_pred = self.model(X)
result = self.metric(y_pred, y)
return result
def predict(self, X, **kwargs):
return self.model(X)
def save_model(self, model_dir):
if not os.path.exists(model_dir):
os.makedirs(model_dir)
params_saved_path = os.path.join(model_dir, 'params.pdtensor')
torch.save(model.params, params_saved_path)
def load_model(self, model_dir):
params_saved_path = os.path.join(model_dir, 'params.pdtensor')
self.model.params = torch.load(params_saved_path)
optimizer = optimizer_lsm
runner = Runner(model, optimizer=optimizer,loss_fn=None, metric=mse_loss)
4.7模型训练
训练代码:
optimizer = optimizer_lsm
runner = Runner(model, optimizer=optimizer,loss_fn=None, metric=mse_loss)
# 模型保存文件夹
saved_dir = 'D:/models_'
# 启动训练
runner.train(train_dataset,reg_lambda=0,model_dir=saved_dir)
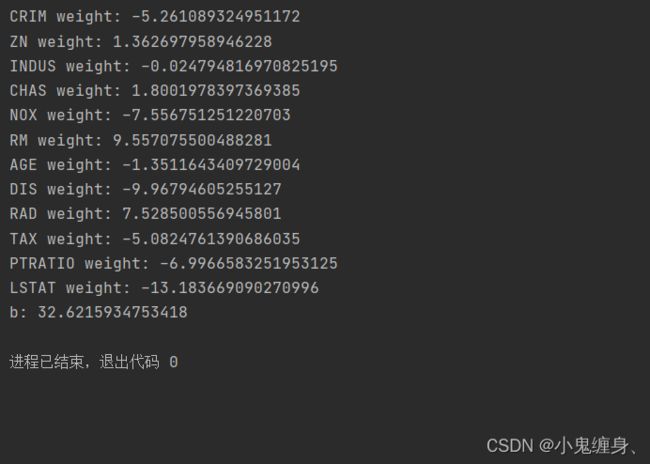
columns_list = data.columns.to_list()
weights = runner.model.params['w'].tolist()
b = runner.model.params['b'].item()
for i in range(len(weights)):
print(columns_list[i],"weight:",weights[i])
print("b:",b)
训练结果:
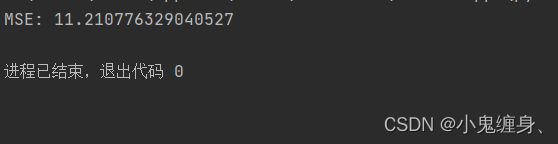
加载训练好的模型参数,在测试集上得到模型的MSE指标。
# 加载模型权重
runner.load_model(saved_dir)
mse = runner.evaluate(test_dataset)
print('MSE:', mse.item())
4.8 模型预测
预测代码
runner.load_model(saved_dir)
pred = runner.predict(X_test[:1])
print("真实房价:",y_test[:1].item())
print("预测的房价:",pred.item())
预测结果:
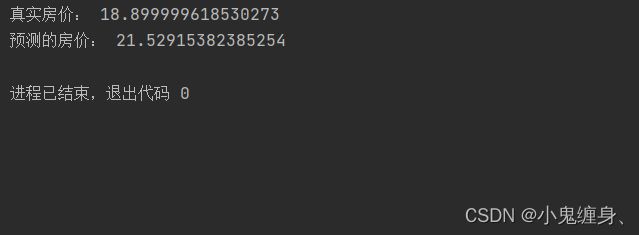 从输出结果看,预测房价接近真实房价。
从输出结果看,预测房价接近真实房价。
后话:一些问题
- 问题1:使用类实现机器学习模型的基本要素有什么优点?
解: 我自我感觉使用类实现机器学习模型的基本要素,可以让我们以后对任何一个适用于该样本的数据集能够以更简单的形式进行训练,优化了后续的训练代码,并且以类封装函数可以让整体更加清晰,思路更加清楚,同时对于机器学习模型的整体把握也会好很多。 - 问题2:算子op、优化器opitimizer放在单独的文件中,主程序在使用时调用该文件。这样做有什么优点?
解: 能够简化操作,直接使用import引用文件,不需要再重新写这些算子和优化器,从而不需要再进行更多的代码编写,省时省力。 - 问题3:线性回归通常使用平方损失函数,能否使用交叉熵损失函数?为什么?
解: 如果要问为什么线性回归要使用均方误差,可以参考这篇博客:【线性回归:为什么损失函数要使用均方误差】,交叉熵损失的假设是误差分布是二值分布,因此更适用于分类等离散属性的问题,而均方误差则假设数据的分布是正态分布,更加是用于连续属性的误差分析。
参考以下博客:
NNDL 实验三 线性回归
神经网络与深度学习:案例与实践
平方损失函数与交叉熵损失函数 & 回归问题为何不使用交叉熵损失函数