可乐的UE4学习笔记(10)--官方教程“蓝图AI简介”的笔记



大纲视图右键browse asset可以直接在资源视图查看源
TIP:1,场景中按end键可以让物体落到地面
2,按F7可以直接compile
AI创建:

点击all class,选择AIcontroller创建

在charactor中选择新建的AIC类型
寻路:






level setting内可以选择是否开启寻路自动更新


利用大纲里的 recastNavMesh里的offset功能把导航体积抬高显示
导航修改器

提高该导航区域的难度
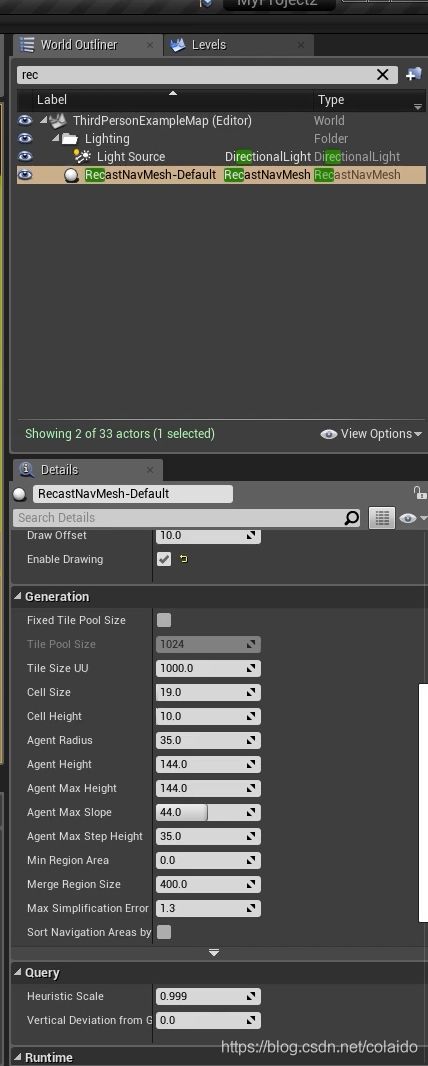
recastNav内可以更改导航属性,agent radius、height控制可寻路的范围


寻路设置里的Agents可以添加多重代理对应多种类型的角色
蓝图中使用simplemovetolocation实现角色移动

Nav data不连接的话就是使用默认寻路体积
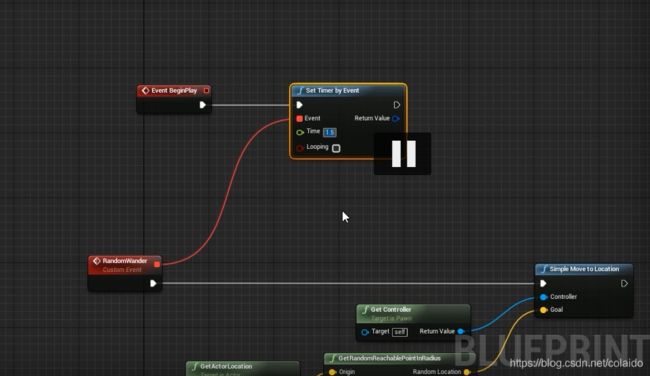
set Timer by event节点可以创建一个计时器,并且可以绑定事件。
DEBUG

Input里面可以自定义一个console
gameplay,debugger设置调试按键

按下对应按键可以在play的时候查看相关内容

左上角是按键对应的显示功能
AI感知:
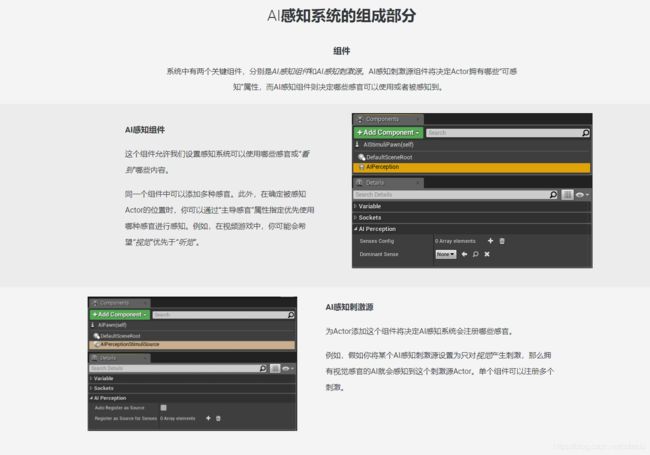

AI角色添加AIPERCEPTION:

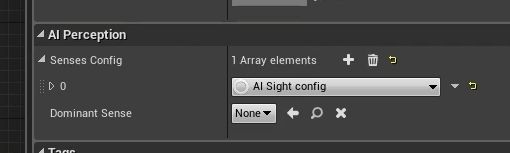

添加了一种感知之后可以点开修改相关属性
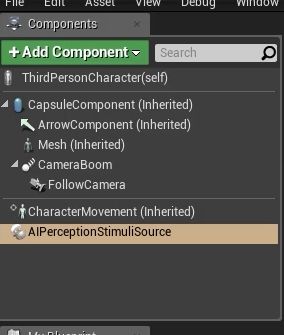
玩家角色添加AIPERCEPTIONSTIMULISOURCE:

TIP:

debug的时候关闭AA抗锯齿可以看清反馈的细线。

按下debug键(默认单引号),按4可以看到反馈,age代表多久前更新的信息。当角色离开视线,age就会增加,视线检测结果留在最后更新的位置。

创建OnTarget Perception Updated,该事件会返回ACTOR和一个包含感知信息的结构体

当事件触发时,先储存actor变量。
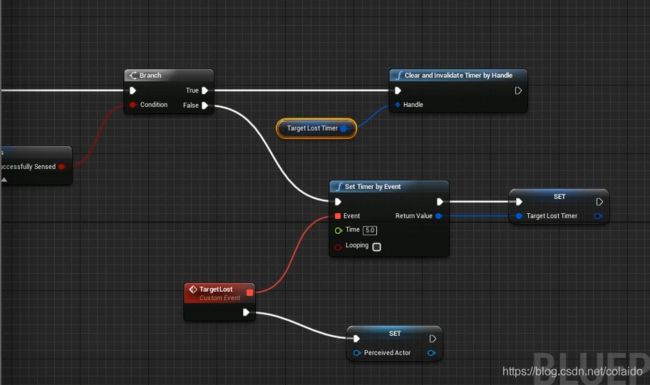
设置定时器,当角色5秒不被感知,清空感知角色的变量。当被感知就删除定时器。
行为树:
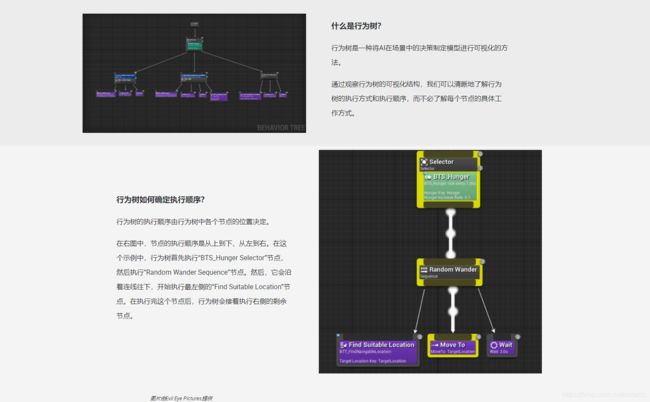



实例:
先创建一个行为树BT——enermyAI

然后创建一个黑板

在AI controller中创建一个Event On Possess,选用刚才创建的行为树

行为树中确保刚才创建的黑板被选中

点右上角黑板可以创建一个新的KEY(变量)

创建完成后该变量就会出现在右下方的黑板面板

点击New task,创建一个BP任务

这个蓝图就会自动被创建在content里

行为树蓝图以这个Event Recerive Execute AI事件开始

因为蓝图任务执行完就会销毁,所以必须要把随机获取的位置传递到黑板中,这里创建一个黑板key的变量。

最后要用finishExcute返回成功或失败
追逐玩家:


黑板创建一个object的key,命名为TargetActor,并在detail里面把class改为actor

再创建一个布尔HasLineOfSight

AI控制器内创建一个函数updateTargetActorKey用来更新黑板内容,函数有一个输入值。右键能够获取黑板变量,
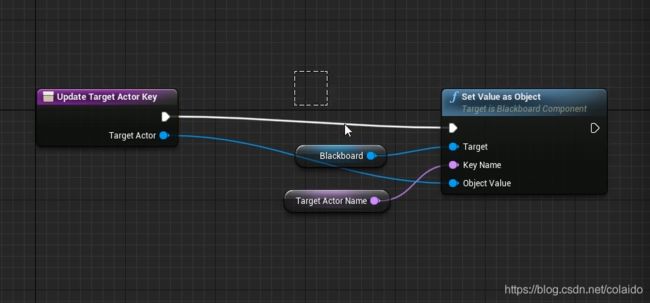
然后用set value as object更新黑板

同样建一个函数更新布尔值



在AI控制的角色中,用之前的传感器事件调用事件更改黑板中的key.
整个逻辑是,当AI感知到玩家,会储存玩家信息和视线可见。挡视线不可见时更新黑板key为不可见,当不可见超过5秒(计时器)则清空玩家信息。
行为树部分:


创建一个selector,左侧创建一个sequence,包含一个move to(TagetActor)和wait



然后为sequnce创建一个修饰器(blackboard),并设置名称和条件
DEBUG:

运行后选择debug的角色
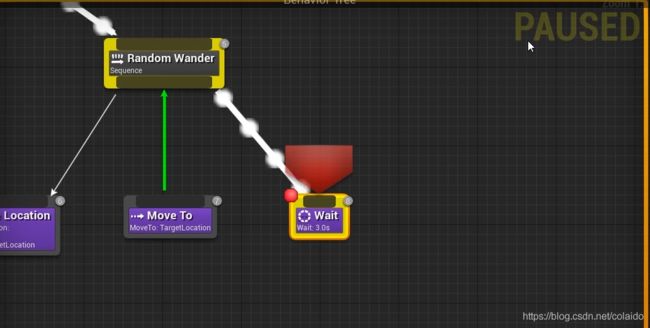
在某个节点上按F9可以设置一个断点,运行到该点游戏就会暂停

上方的按键可以控制查看

运行中按2查看行为树信息,可以看到当前的数值
学完这一部分之后关于行为树和黑板还有一些搞不清楚的,行为树其实是一个拥有一些常用动作并且可以用于多种同类角色的组合机制,它依赖于黑板的数据做决策。黑板相当于一个公共变量,在黑板上写状态就避免了每个角色都要建立大量相同的状态变量。
AI charactor要做的只是感知并将感知信息发送到黑板,这里比较讨厌的是因为黑板时加载给AI controller的,所以更新黑板的函数要写在AI controller里(为了调用相对应的黑板变量,也为了可以普遍适应各种需要同类controller控制的AI角色)。然后再拥有感知能力的charactor里根据感知的反馈,调用AI controller的函数更新黑板。
而行为树是一个独立的思维网络,只依赖于黑板的信息来做决策。每次向下运行,不论成功与否只要运行到结尾就重头再运行一次。在这个范例中思维从根部开始,向下到selector的时候就要二选一,决定是否要追踪敌人。追踪完成这个行为树就完成了一次,再次从根部开始。如果这次运行到修饰器(其实就是个综合判断的程序),修饰器如果检测到这一轮行动之间内容发生了变化,那么这次的行为就直接停止,两边都不执行,发回去从根部再重新判断一次。新的运行再次到修饰器,修饰器的反馈是条件为假(没有敌人),并且不是刚更新的状态,那么这个选择分支就被放弃,转而运行另一个分支(瞎溜达)。
行为树提供了大量内置的行为控制,比如移动,等待等等。
下面是课程的第三部分-EQS的内容:

EQS的启动在Experimantal里


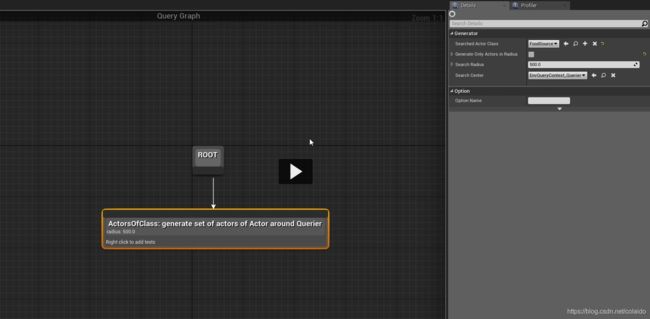
QES里面可以设置需要查找的类型。

generate中添加一个距离测试(test)
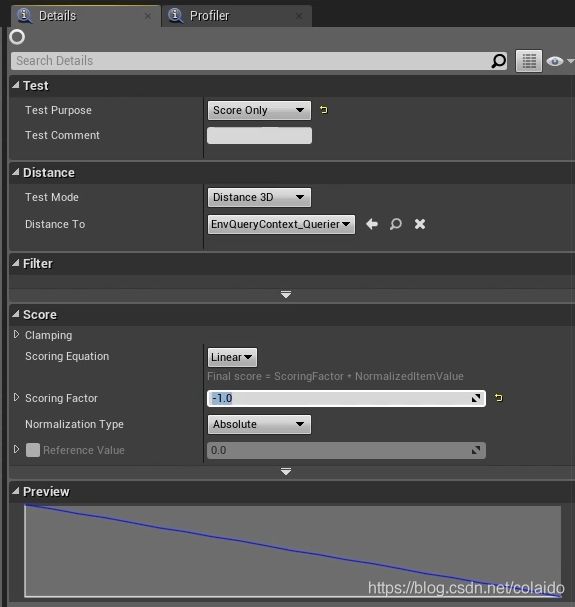
测试目的改为计分,factor改成-1,这样就会倾向于选择更低的数值(距离更近)

在行为树中新建一个key(object),类型改为foodSource

新建一个行为分支,添加run EQS Query,设置EQS为刚才创建的找食物的EQS,模式设置为分数最高的单个物体。

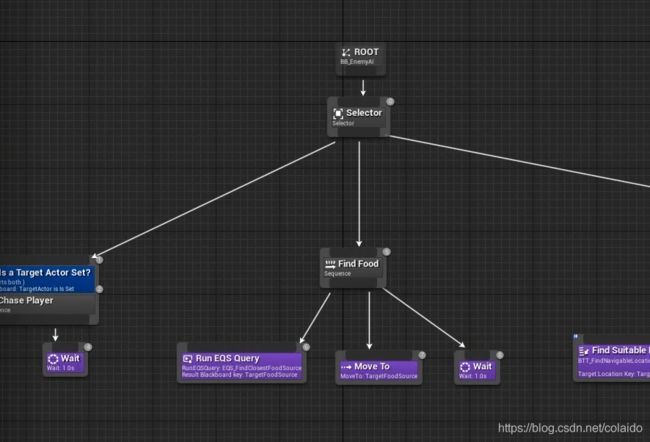
在blackboard选项中选择要写入的黑板key,这样就实现了根据EQS实现拾取食物。
行为树的service创建:

新建一个hungerkey
可以创建一个新的service
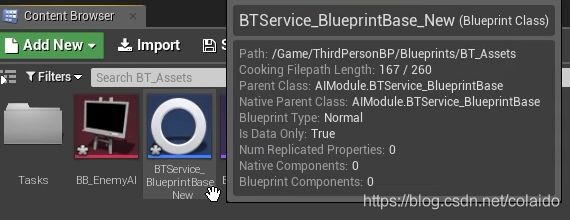
新seive的蓝图会创建在同一个目录,改名


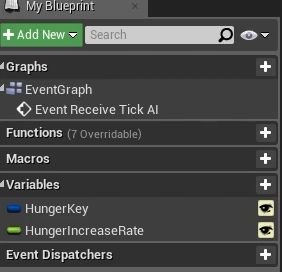
新建一个变量,类型是blackboardkey,在新建一个float变量用来控制每帧hunger值得增量

Event Receive Tick AI事件调用黑板的hunger key,每帧增加Hungerincreaserate,然后set输出
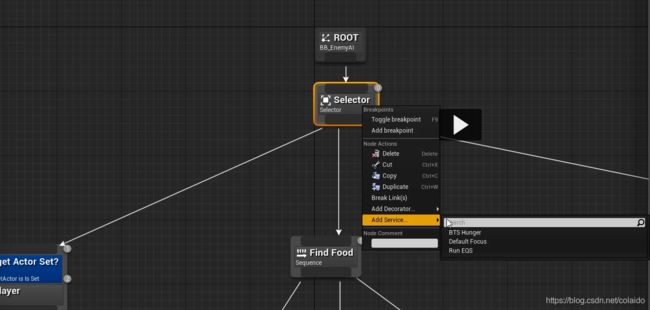
在总的selector中添加service。

把服务蓝图的黑板变量指定为Hunger Key

这里控制服务的间隔时间和随机变化
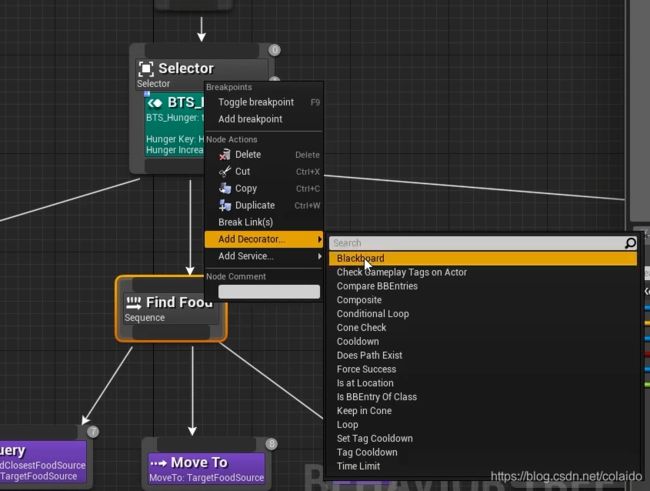

给查找食物行为创建一个黑板修饰器
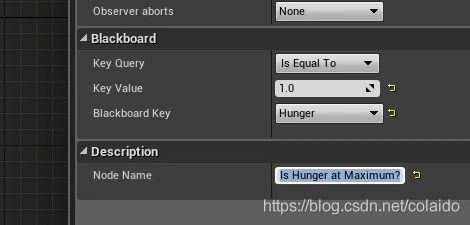
这样就完成了当hunger key数值达到1,就寻找食物的逻辑

创建一个设置浮点数的BP task,用来设置黑板里的浮点key。

这样就完成了获取食物后hunger值归零
EQS躲避角色AI:

创建一个EnvQueryContext(EQS的情景文件)
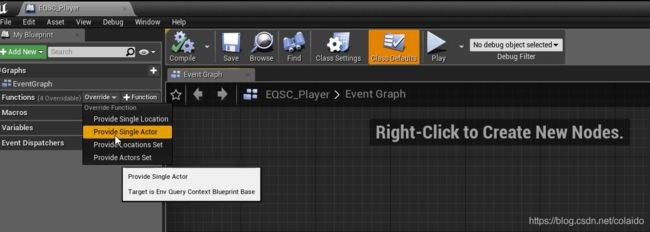
重命名为EQSC_player,重写继承的Provide Single Actor函数
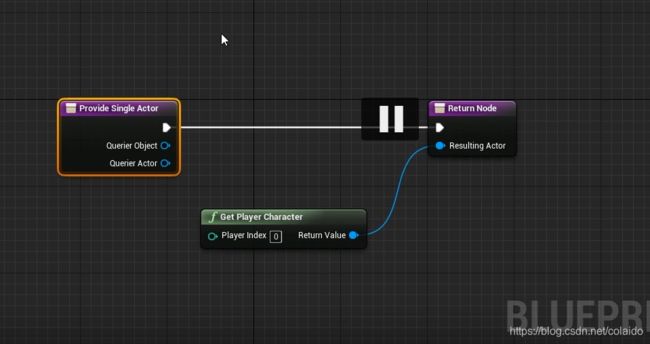
函数直接返回play charactor
新建一个EQS,用来查询最适合躲藏的点

新建一个generate around Query,它会在一定范围内设置一定量的测试点。

右键创建一个test,用来测试比较

右键创建一个trace测试,模式设置为filter only,目标的context设置为EQSC_player(刚才创建的那个返回玩家位置的EQSC蓝图)

然后再创建一个距离测试

设置为得分模式,factor设置为-1,选出得分最高的点(距离最近)

再创建一个pathfinding测试,判断这个点是不是能够被导航

这里的情景选择EnvQueryContext_Query(默认的情景)
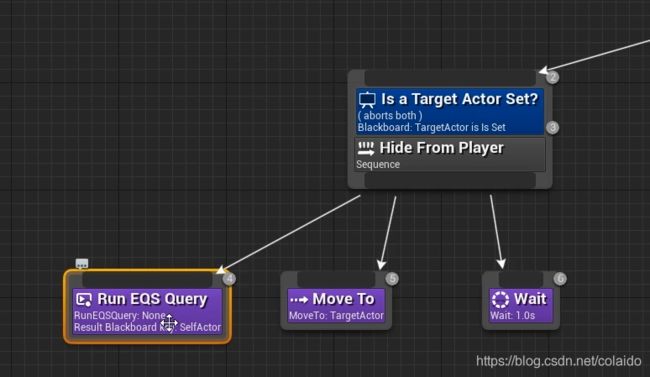
返回到行为树,将原有的追踪行为改名为躲避行为,新建一个Run EQS Query任务

将EQS的返回值设置为Taeget Location,然后选择刚才的筛选躲避点的EQS

然后把move to的行为目标改为Target Location,这样就完成了躲避玩家的逻辑树
EQS_test pawn:

创建一个EQS_Testing Pawn蓝图
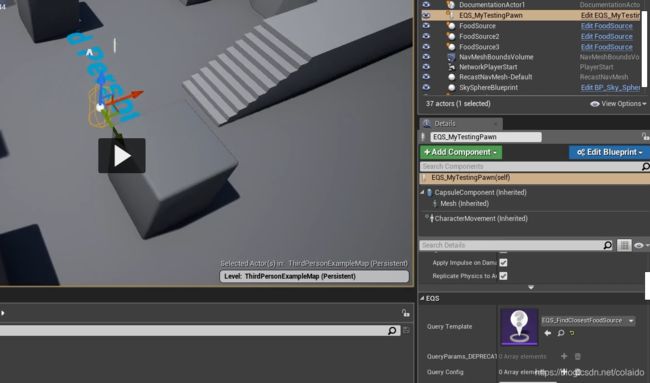
将测试pawn拖进视图,并选择EQS为之前的查找食物。

这样直接就可看到EQS里面各个物体的得分

切换到躲猫猫EQS,可以看到测试点,但是有效点太多了。这是因为游戏没有运行,所以没有获取到玩家的charactor

修改一下EQSC_Player的内容,将返回值设置为查询的Actor(转换类型为EQS testing pawn)
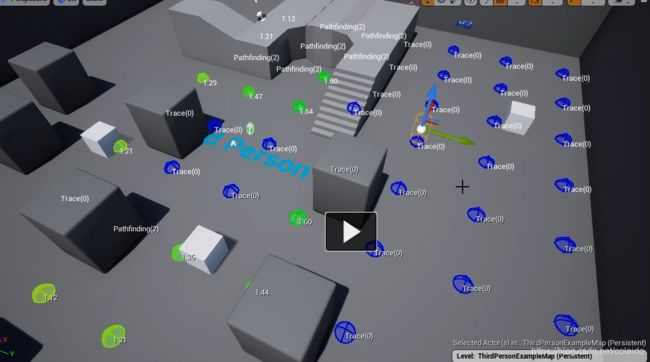
这样再返回游戏界面,选择测试pawn,就可以看到以自身作为目标的测试结果。
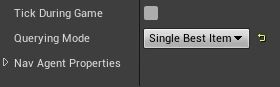
查看模式改为single Best Item,就可以找到最优选择。

最后把context改回原来的返回玩家角色
观察使用效果

游戏以后按 ’ 键打开gameplay debug,然后tab进入观察者模式就可以把摄像机独立出来查看AI
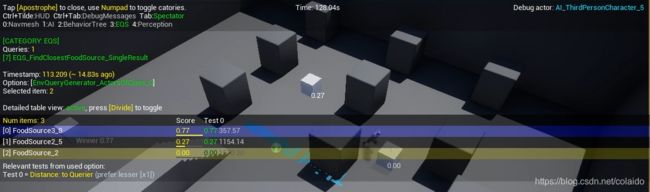
开启EQS查看的时候按下/可以看到EQS的各项得分

按*键可以更改要查看的EQS结果
以上是官方AI教程的内容,因为官方教程里面没有讲关于行为树调用角色蓝图的部分,所以再补一段B站上堪家诚的相关教程。

他在教程里用了更简单的部分,AI角色用一个重叠时间自动播放挥拳动画,并且用定时器循环。

蒙太奇必须要在动画的状态机后面有个插槽才能使用

他在创建task的时候直接创建了一个带行动的任务,相当于用蓝图控制AI。
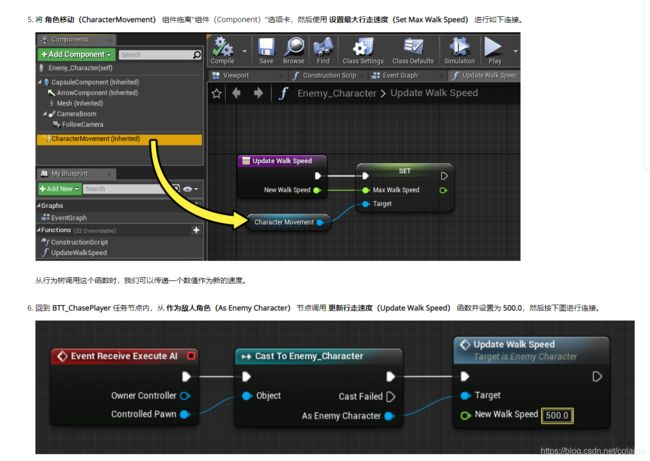
官方帮助里面有一个简单的范例演示了使用AI任务调用AI角色内部函数的范例。