【学习实践】尝试使用LDA方法与传统LSA方法对比实现文本主题进行挖掘
尝试使用LDA方法与传统LSA方法对比实现文本主题进行挖掘
实验简介
本实验或者说案例,是使用Pycharm编写代码,对同一组新闻数据集进行新闻主题挖掘,来训练两个不同的NLP模型,并提供训练集对训练结果进行测试,并量化。随后通过可视化方法对比两组实验结果。(为了保留实验过程以及实现结果的可视化,保留了实验生成的日志文档和某次实验结果的参考图)
首先,该实验数据集为爬取到的新闻主题的数据集,大约包含22000条content信息可以供模型训练使用,但由于数据集来自爬虫爬取的含html标签形式的txt文件,需要进行数据清洗来提取新闻内容。简略的实验流程描述如下:在清洗过数据集之后,对数据集进行分词和词性标注(该过程的耗时较长)。随后通过分词后的数据构建词袋模型(也就是语料库,包含词典,TF-IDF矩阵等信息)。构建完毕后,人为给定一个挖掘的主题个数后,分别使用刚才构建好的语料库去训练LSA模型和LDA模型。训练完毕后,保存两种模型并准备带入到测试集中查看预测效果。随后,用同样的预处理方法提取测试集的语料,并将测试集语料带入到两种不同的模型中查看结果,通过可视化方法进行对比,得到比较明显的实验结果。
实验全程的每一个子过程均记录了起止时间,并打印到了日志文档log.txt中用于对比和检验试验过程的耗时情况。
实验环境
软件环境
Windows 10操作系统,Pycharm IDE环境。
硬件环境
12线程CPU,16G内存,6G显存
第三方库的使用
- Jieba函数库(用于分词和词性标注与过滤)
- Bs4函数库(用于清洗’lxml’标签)
- Gensim函数库(用于词袋语料库预处理以及模型的训练)
- Tarfile函数库(用于解压数据集文件)
- Os函数库(用于路径分析和文件操作以及日志操作)
- Matplotlib函数库(用于数据可视化过程便于对比实验结果)
- Time函数库(用于记录每一步子过程的时间节点)
实验目标
对比LSA模型和LDA模型挖掘新闻主题的效果,评价两种模型的优势与缺点。效果评价主要从以下几个方面进行:模型训练时间,模型预测准确度,模型主题之间的相关度等。将两个模型的训练结果和预测结果都表示出来,并进行对比,并记录分析,是该实验的主要目标。
实验过程
实验的数据集的原始形式是.tar.gz格式的压缩文件,包含多个被切割的txt文档。首先需要对其进行解压缩。记录压缩所消耗的时间。然后将解压之后的所有content综合起来准备进行清洗。记录数据合并的时间消耗。而这个数据集的数据主要来自网络爬虫的爬取结果,所以txt中包含大量的冗余信息,在解压和合并之后,首先使用bs4.BeautifulSoup函数库将html标签和无关数据过滤掉,仅提取出我们想要使用的content标签当中的新闻内容,同时记录下数据清洗所消耗的时间。
数据清洗过后,要开始构建单词文本矩阵了,首先需要把大段的文本信息进行分词,并对词性进行标注,为的是过滤掉无关的连接词和空白content中的无关信息。该过程使用到了Jieba函数库的posseg子库,记录下分词和词性标注开始的时间和结束时间。
标注结束后使用词袋模型预处理函数,对分好词的数据集进行处理,首先构建词典,记录下这一过程起止时间。再紧接着构建语料库,这是为了训练模型是能够参照着无权的语料数据(LDA随机抽样目标),同样记录下起止时间来计算消耗。然后为了综合权重信息,我们使用TF-IDF来表示综合重要程度(同时体现一个文本中某单词出现次数的占比和含有某单词的语料占全部文本的比例),也记录下这个过程的时间消耗。
首先,我人为的(主观可变参数 - num_topics = 10)指定了10个主题个数进行挖掘。将预处理的结果,应用于模型的训练当中,分别训练LSA和LDA模型,并打印出训练的结果,结果呈现为主题序号和主题关键字的键值对形式。可以通过观察这个过程结果。来观察有没有很好的避免一词多义和多词一义。在这个过程中记录下来两个模型的训练消耗时长,作为其中一个关键参数进行对比。
最后通过一组测试及样本进行测试,首先也是对测试机进行语料的预处理,然后作为预测样本带入到两个模型中去,分别得到两个模型,对该样本的预测结果。表示为10个主题的相似度键值对结果。将预测结果进行归一化和标准化后,用matplotlib可视化的方法将数据呈现出来进行比较分析。
实验代码
函数库引用部分:
# Author:JinyuZ1996
# Creation date:2020/7/25 20:03
# -*- coding: utf-8 -*-
import os
import tarfile
import matplotlib.pyplot as plt
import jieba.posseg as pseg
import time as t
# 使用jieba第三方类库对文本进行切割(中文分词类库),但是我们接下来要使用的是posseg的cut方法(大坑)
from bs4 import BeautifulSoup
from gensim import corpora, models
#踩坑,在使用LSA的时候必须指明包内调用的是lsimodel,而网上大多数博主没说或者说之前的写法可以用
import gensim.models.lsimodel as lsi函数定义部分:(注释详细)
# 函数定义部分
# 数据集分词方法:将输入的文本句子根据词性标注做分词
# (参数是:从数据集或者测试集中提取的文本句子,为标准字符串类型)
def cut_word(text):
word_type = ['z', 'vn', 'v', 't', 'nz', 'nr', 'ns', 'n', 'l', 'i', 'j', 'an', 'a'] # 定义各种不同的词性规则
words = pseg.cut(text) # 在这里踩了个大坑
# 使用jieba中定义的cut方法来进行中文分词,这里cut方法通过查库,得知是精准模式,它会把文本精确的切分开,不存在冗余单词
cut_result = [word_cut.word for word_cut in words if word_cut.flag in word_type] # 这是一个地道的写法,可以避免主观上知道被分成了多少词项
return cut_result # 返回符合规则的分词结果
# 文本预处理方法:如果是训练阶段,返回词典、TF-IDF对象和TF-IDF向量空间数据;如果是预测阶段,返回TF-IDF向量空间数据
# (参数是:词项表——列表型数据;TF_IDF模型对象——默认值是None;标志位,标志现在是什么过程,训练还是测试)
def text_pre(words_list, tfidf_object=None, training=True):
# 分词列表转字典
t_dic_start = t.time()
dic = corpora.Dictionary(words_list) # 将分好词的词项表转换为字典形式
t_dic_end = t.time()
if training:
print('训练集词典构建完毕.用了' + str(format(t_dic_end-t_dic_start,'.2f')) + '秒,构建模型语料库开始......')
# 下面这三行曾经是为了展示一下词典模型的样式
# print('{:-^50}'.format('测试展示词典索引值与分词表:'))
# for i, w in list(dic.items())[:20]: # 循环读出字典前20条的每个key和value,对应的是索引值和分词
# print('索引值:%s -- 分词:%s' % (i, w)) # 因为数据量比较大这里只是做个展示,让大家看一下数据处理的步骤
else:
print('测试集字典构建完毕.')
# 构建完了词典再来构建语料库corpus,这里的doc2bow方法是构建bow模型的内置方法
# 该模型忽略掉文本的语法和语序等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的(也就是构成了原始的语料)
t_corpus_start = t.time()
corpus = [dic.doc2bow(words) for words in words_list] # 用于存储语料库的列表
t_corpus_end = t.time()
if training:
print('训练集语料库构建完毕.用了' + str(format(t_corpus_end-t_corpus_start,'.2f')) + '秒,构建模型TF—IDF开始......')
# 下面这两局曾经用于测试查看词袋模型语料库形式
# print('{:-^50}'.format('语料库一维样本展示:'))
# print(corpus[0]) # 展示语料库的第一维
else:
print('测试集语料集合分析完毕.')
# TF-IDF转换(首先判定是否为训练过程,如果是的话则使用语料库进行权值矩阵的构建)
if training:
t_TFIDF_start = t.time()
tfidf = models.TfidfModel(corpus) # 建立TF-IDF模型对象,TF_IDF也是定义在gensim上的既有方法
corpus_tfidf = tfidf[corpus] # 得到TF-IDF向量稀疏矩阵
# 下面这两句曾经用于测试查看词袋模型的样子
# print('{:-^50}'.format('TF-IDF 模型一维展示:'))
# print(list(corpus_tfidf)[0]) # 展示第一维
t_TFIDF_end = t.time()
print('构建TF-IDF过程结束,用了'+str(format(t_TFIDF_end-t_TFIDF_start,'.2f'))+'秒.')
return dic, corpus_tfidf, tfidf
else:
return tfidf_object[corpus] # 如果试运行测试集的话不做处理tfidf_object=None
# 全角转半角方法:用于数据及预处理环节,数据清洗使用
# (参数是:content标签里的原始文本)
def str_convert(content):
strs = []
for each_char in content: # 循环读取每个字符
code_num = ord(each_char) # 读取字符的ASCII值或Unicode值
if code_num == 12288: # 全角空格直接转换
code_num = 32
elif 65281 <= code_num <= 65374: # 全角字符(除空格)根据关系转化
code_num -= 65248
strs.append(chr(code_num))
return ''.join(strs)
# 解析文件内容数据预处理之前的简单清洗
# (参数是:数据集文件读取过来的文本格式包含大量标签格式和脏数据)
def data_parse(data):
#BeautifulSoup库的作用就是帮助我们去提取网页格式标签内的信息
raw_code = BeautifulSoup(data, 'lxml') # 建立BeautifulSoup对象
content_code = raw_code.find_all('content') # 从包含文本的代码块中找到content标签,将新闻信息过滤出来
# 将每个content标签中的文本提取出来之后,转成半角str字符串格式对象存储返回一个字符串list(过程中还进行了判空,清洗掉了数据库脏数据)
content_list = [str_convert(each_content.text) for each_content in content_code if len(each_content) > 0]
return content_list案例实现过程部分:(注释详细)# 案例实现过程部分
# 创建日志文件用于记录运行过程及结果
doc = open('log.txt','w')
# 解压缩文件过程(找了一个比较完整的读取tar.gz格式压缩文件的步骤(之前找的全炸),建议收着)
print('解压过程开始......')
print('解压过程开始......',file=doc)
t_unzip_start = t.time()
if not os.path.exists('./news_data'): # 如果不存在数据目录,则先解压数据文件(就是有没有解压的文件夹在)
with tarfile.open('news_data.tar.gz') as tar: # 打开tar.gz压缩包对象(有时包内部嵌套多层)
names = tar.getnames() # 获得压缩包内的每个文件对象的名称
for name in names: # 循环读出每个文件
tar.extract(name, path='./') # 将文件解压到指定目录
# 汇总所有内容(因为通过观察数据集在压缩目录中被分为多个子文件,个人粗略估计大概有22000+个content)
t_unzip_end = t.time()
print('解压过程结束,用了'+str(format(t_unzip_end-t_unzip_start,'.2f'))+'秒,数据合并过程开始......')
print('解压过程结束,用了'+str(format(t_unzip_end-t_unzip_start,'.2f'))+'秒,数据合并过程开始......',file=doc)
t_datamerg_start = t.time()
all_content = [] # 构建总列表,待会儿用于存储所有文件的文本内容
for root, dirs, files in os.walk('./news_data'): # os.walk()游走方法,分别读取遍历目录下的根目录、子目录和文件列表
for file in files: # 循环读取每个文件
file_name = os.path.join(root, file) # 将目录路径与文件名合并为带有完整路径的文件名
with open(file_name, encoding='utf-8') as f: # 以只读方式打开文件(默认就是只读)
data = f.read() # 读取文件内容
all_content.extend(data_parse(data)) # 从文件内容中获取文本,清洗数据并将结果追加到总列表
# 数据集分词过程开始
t_datamerg_end = t.time()
print('数据合并过程结束,用了'+str(format(t_datamerg_end-t_datamerg_start,'.2f'))+'秒,分词过程开始......')
print('数据合并过程结束,用了'+str(format(t_datamerg_end-t_datamerg_start,'.2f'))+'秒,分词过程开始......',file=doc)
# 获取分词列表,用于存储所有文件的分词结果(在all_content中获得)
t_cutWord_start = t.time()
print("开始对数据集进行分词和词性标注(该过程比较耗时)......")
print("开始对数据集进行分词和词性标注(该过程比较耗时)......",file=doc)
words_list = [list(cut_word(each_content)) for each_content in all_content]
t_cutWord_end = t.time()
print("分词过程完成,用了"+str(format(t_cutWord_end-t_cutWord_start,'.2f'))+'秒,开始构建词典模型......')
t_wordwash_start = t.time()
dic, corpus_tfidf, tfidf = text_pre(words_list) # 有了数据,我们先对训练集的文本进行预处理
num_topics = 10 # 主观的设置主题个数(先设置10个测试)
t_wordWash_end = t.time()
print('词袋预处理过程结束,'+str(format(t_wordWash_end-t_wordwash_start,'.2f'))+'秒,开始构建LDA主题模型......')
print('词袋预处理过程结束,'+str(format(t_wordWash_end-t_wordwash_start,'.2f'))+'秒,开始构建LDA主题模型......',file=doc)
# 使用数据集分别训练LDA和LSA两种模型(分别记录训练时间用于结果比较)
t_lda_start = t.time()
lda = models.LdaModel(corpus_tfidf, id2word=dic, num_topics=num_topics) #通过LDA进行主题建模
t_lda_end = t.time()
print('LDA模型构建完毕,用了'+str(format(t_lda_end-t_lda_start,'.2f'))+'秒,开始构建LSA主题模型......')
print('LDA模型构建完毕,用了'+str(format(t_lda_end-t_lda_start,'.2f'))+'秒,开始构建LSA主题模型......',file=doc)
print('{:-^50}'.format('构建好的主题LDA:'))
print('{:-^50}'.format('构建好的主题LDA:'),file=doc)
print(lda.print_topics()) #打印所有LDA的主题
print(lda.print_topics(),file=doc)
t_lsa_start = t.time()
lsa = lsi.LsiModel(corpus_tfidf, id2word=dic, num_topics=num_topics) #通过LSA进行主题建模
t_lsa_end = t.time()
print('LSA模型构建完毕,用了'+str(format(t_lsa_end-t_lsa_start,'.2f'))+'秒.')
print('LSA模型构建完毕,用了'+str(format(t_lsa_end-t_lsa_start,'.2f'))+'秒.',file=doc)
print('{:-^50}'.format('构建好的主题LSA:'))
print('{:-^50}'.format('构建好的主题LSA:'),file=doc)
print(lsa.print_topics()) #打印所有LSA的主题
print(lsa.print_topics(),file=doc)
# 新数据集的主题模型预测
print('开始测试集过程,测试集文件打开......')
print('开始测试集过程,测试集文件打开......',file=doc)
with open('article.txt', encoding='utf-8') as f: # 打开测试集的文本
text_new = f.read() # 读取文本数据
text_content = data_parse(data) # 解析新的文本
words_list_new = cut_word(text_new) # 将文本分词为下一步预处理做准备
corpus_tfidf_new = text_pre([words_list_new], tfidf_object=tfidf, training=False) # 新文本数据集的预处理(注意把标志位置false)
# LDA预测部分(使用训练好的LDA模型去预测新闻主题)
# t_testLda_start = t.time()
corpus_lda_new = lda[corpus_tfidf_new] # 用训练好的lda去获取新的分词词袋列表(文档)的主题概率分布
# t_testLda_end = t.time()
print('{:-^50}'.format('测试样本LDA主题预测:'))
print('{:-^50}'.format('测试样本LDA主题预测:'),file=doc)
pre_list = list(corpus_lda_new)
trans_list = sorted(pre_list[0],key = (lambda x:[x[1],x[0]]),reverse=True) #2020-08-05改进代码通过排序方式将最大概率的预测结果显示在第一位
print(trans_list) #打印出排序好的话题序列预测结果
print(trans_list,file=doc)
# print('LDA模型对测试集数据预测完毕,用了'+str(format(t_testLda_end-t_testLda_start,'.2f'))+'秒.') #为什么不写了呢,因为我发现真的这个过程是很快的,快到.2f不是很好展示
print('LDA模型对测试集数据预测完毕.')
print('LDA模型对测试集数据预测完毕.',file=doc)
# LSA预测部分(使用训练好的LSA模型去预测新闻主题)
# t_testLsa_start = t.time() #记录LSA预测测实际的开始时间
corpus_lsa_new = lsa[corpus_tfidf_new] #用构建好的lsa去处理测试集语料库
# t_testLsa_end = t.time() #记录LSA预测结束的时间
print('{:-^50}'.format('测试样本LSA主题预测:'))
print('{:-^50}'.format('测试样本LSA主题预测:'),file=doc)
pre_list_lsa = list(corpus_lsa_new) #将训练好的结果转成List对象
trans_list_lsa = sorted(pre_list_lsa[0],key = (lambda x:[abs(x[1]),x[0]]),reverse=False) #对值得部分进行排序(排序的时候要使用绝对值形式排序)
print(trans_list_lsa) #打印出排序好的话题序列预测结果
print(trans_list_lsa,file=doc)
# print('LSA模型对测试集数据预测完毕,用了'+str(format(t_testLsa_end-t_testLsa_start,'.2f'))+'秒.') #为什么不写了呢,因为我发现真的这个过程是很快的,快到.2f不是很好展示
print('LSA模型对测试集数据预测完毕.')
print('LSA模型对测试集数据预测完毕.',file=doc)
# 图形化展LSA的测试结果(柱状图)
id_lsa = [] #话题编号list(注意要与值一一对应)
val_lsa = [] #权重值的list
lsa_Outlist = trans_list_lsa #个人习惯再赋个新名字
for i in range(0,len(lsa_Outlist)): #该循环用于将上方矩阵中的值转移到两个新的list当中用于结果的展示
id_lsa.append("tp-"+str(lsa_Outlist[i][0])) #将编号放入新的list中准备打印
val_lsa.append(float(format((1-10*abs(lsa_Outlist[i][1]))*10,'.3f'))) #将权重放入新的list,注意取绝对值并同时对数据进行归一化方便展示
print(id_lsa) #测试打印序号序列
print(val_lsa) #测试打印权重序列
fig = plt.figure(figsize=(10, 5)) #设置窗体大小
fig.canvas.set_window_title('Using LSA to predict Testing Set') #设置窗体title
plt.title('Using LSA to predict Testing Set') #设置图表的title
plt.xlabel('Predicted subject sequence number') #被预测的话题序号
plt.ylabel('Weight of prediction possibility') #被预测的话题可能性权重
# 我这里只设置了九种颜色,要是后期同学们再增加新的话题个数的话就需要再增加颜色种类
plt.bar(range(len(val_lsa)),val_lsa,width=0.5,tick_label=id_lsa,color =['grey','gold','darkviolet','turquoise','red','green','blue','pink','tan'])
plt.show()
# 图形化展示LDA测试结果(柱状图)
id_lda = [] #话题编号list(注意要与值一一对应)
val_lda = [] #权重值的list
lda_Outlist = trans_list
for i in range(0,len(lda_Outlist)): #该循环用于将上方矩阵中的值转移到两个新的list当中用于结果的展示
id_lda.append("tp-"+str(trans_list[i][0])) #将编号放入新的list中准备打印
val_lda.append(float(format((trans_list[i][1])*10,'.3f'))) #将权重放入新的list,lda的数据好处理一些
print(id_lda) #测试打印序号序列
print(val_lda) #测试打印权重序列
# 曾经对lda尝试过绘制饼图,但是效果不是很好,但是保留这种写法以后参考用。参数(值,标志,颜色分类,自动转化为百分比形式,还可以设置阴影shadow=,或者设置凸显某一部分explode=)
# plt.pie(x=value,labels=id_lda,colors=['C0', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'C8', 'C9'],autopct='%1.1f%%')
# plt.axis('equal') #用'正'圆饼图来可视化预测结果
fig = plt.figure(figsize=(10, 5)) #设置窗体大小
fig.canvas.set_window_title('Using LDA to predict Testing Set') #设置窗体title
plt.title('Using LDA to predict Testing Set') #设置图表的title
plt.xlabel('Predicted subject sequence number') #被预测的话题序号
plt.ylabel('Weight of prediction possibility') #被预测的话题可能性权重
# 我这里只设置了九种颜色,要是后期同学们再增加新的话题个数的话就需要再增加颜色种类
plt.bar(range(len(val_lda)),val_lda,width=0.5,tick_label=id_lda,color =['grey','gold','darkviolet','turquoise','red','green','blue','pink','tan'])
plt.show()
#再比较一下二者花费时间的差距
lda_cost = t_lda_end-t_lda_start
lsa_cost = t_lsa_end-t_lsa_start
if lda_cost>lsa_cost:
print("LDA模型花费" + str(format(lda_cost, '.2f')) + '秒.\nLSA模型花费' + str(format(lsa_cost, '.2f')) + '秒.')
print("LDA模型花费" + str(format(lda_cost, '.2f')) + '秒.\nLSA模型花费' + str(format(lsa_cost, '.2f')) + '秒.', file=doc)
print("LDA模型比LSA模型要多花费" + str(format(lda_cost - lsa_cost, '.2f')) + '秒.')
print("LDA模型比LSA模型要多花费" + str(format(lda_cost - lsa_cost, '.2f')) + '秒.',file=doc)
else:
print("LDA模型花费" + str(format(lda_cost,'.2f')) + '秒.\nLSA模型花费' + str(format(lsa_cost,'.2f')) + '秒.')
print("LDA模型花费" + str(format(lda_cost, '.2f')) + '秒.\nLSA模型花费' + str(format(lsa_cost, '.2f')) + '秒.', file=doc)
print("LSA模型比LDA模型要多花费" + str(format(lsa_cost - lda_cost,'.2f')) + '秒.')
print("LSA模型比LDA模型要多花费" + str(format(lsa_cost - lda_cost, '.2f')) + '秒.',file=doc)实验结果分析
首先,根据某次实验log.txt给出的结果和可视化数据结果来进行观察(事先已经进行了超过20次实验,这里取其中一次比较有代表性的试验结果来分析):
从训练结果来看,根据对log.txt当中LSA和LDA主题训练结果的内容观察分析可以得知,LSA明显的在多个主题中都有着部分与体育相关的单词,我们可以理解这种情况产生的原因,之前我在视频中提到过关于新闻主题个数的问题,大约在22-30个左右的时候可以实现最佳粒度,但目前为了尽快得到实验结果和放大实验效果,我们主观的取num_topics = 10,来进行试验。但事实上你可以清楚地发现,在LDA训练结果中就有很高的区分度,即便目前仅仅只有10个话题,每个话题之间的关联度也都很小,只是偶尔会出现个别相关联单词被分配到其他主题的情况,占的权重也很小。所以当我们只观测到训练结果的时候,初步推测,LSA将会出现预测不准,或预测模糊的状况,而相对的LDA应该能够避免这种情况。
然后,从训练时间来看,在我们目前规定的数据及规模和话题量为10的实验条件下,LSA在多次重复试验过程中基本上都会比LDA慢2s左右。
最后让我们看一看二者对测试集的预测结果,测试集是一则体育新闻,LDA精准的将其预测为话题9,带有比较高的权值,且所有话题集的相似度均以正数排列,几乎不需要筛选返回值和归一化,当然后期为了在图像中方便展示进行了format,而LSA模型返回值键值对之间差距较大,相似度表达为与主题偏离的程度,需要先取绝对值,在进行从小到大排序,并且由于我们先前分析的结果,多个话题之间保有较小的差距,所以可以看到多个话题(abs后)都有着比较小的偏差,预测结果相对LDA来说比较模糊,且后期数据处理较为复杂。
只看log.txt已经不太直观了,当我们对两者返回值list进行归一化展示后,我们会清楚地得到两张图表。
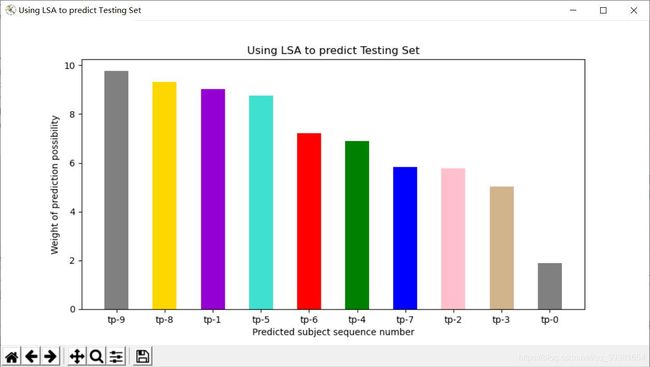 Chart1:LSA模型预测的结果
Chart1:LSA模型预测的结果
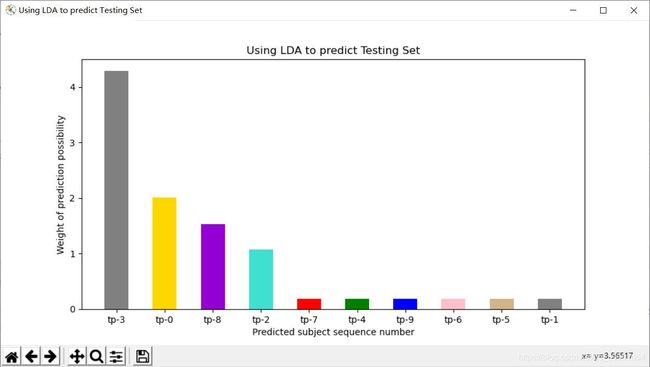 Chart2:LDA模型预测的结果
Chart2:LDA模型预测的结果
通过观察,我们可以明显的看到,LDA拥有更加清晰地预测反馈,不同的话题相似度之间有着明显的差距,据此可以明确的定义其中某一话题(topic3)为所预测话题的目标话题。而LSA的结果就比较模糊,话题9,8,1,5都有着比较高的相似度,虽然仍可以比较出9是最为相似的话题,但是效果显然不如LDA明显。
事实上,还有一处区别是在实验过程中发现的,那就是LDA每次实验所生成的话题顺序是不同的,有的时候话题3代表着体育,有的时候话题6代表着体育,但是都具有相同的预测精度。而LSA每次的预测结果几乎都是相似的,图像也基本一致。这是因为,LSA使用SVD奇异值分解,而LDA使用的是随机抽样的方法,由于随机抽样,所以每次产生的话题序列生成结果也不尽相同,这是非常正常的现象。
得出结论
通过实验和多组信息的对比,LDA与LSA相比在规定了话题个数的前提下,LDA的挖掘效果要更加突出和明显,预测的精度相对更高,且LDA也抱有更小的时间消耗,LSA的预测结果就相对模糊。分析原因的话,我们也可以得知,在之前的学习过程中,我们知道LSA是通过SVD降维手段将原始相似度不高的高维矩阵映射到新的低维语义空间中来实现的,所以其每次的分解结果都是相近的,而且我们知道它可以解决多词一义的问题,而解决不了一词多义的问题,这也就是它在多个话题中包含多个相似单词的重要原因之一。相对的来说LDA,使用MCMC中的Gibbs抽样算法实现随机抽样,于是它每次产生的训练序列会有所不同,但是却能保持相对较高的预测效果,同时也避免了一词多义与多词一义的问题,使得话题预测结果没有歧义,单个话题预测相似度能够明显地优于其他多个话题。
实验的不足
事实上能够提出来的不足也马上就能够解决,只是写报告的时候,完善实验在时间上有些不太够了。第一个可以改进的点,应该在log中打印多次重复试验的所有日志信息,而不是仅保留最近一次试验的日志结果。第二个可以改进的点,该专门写一个类或者函数,把训练和测试LDA和LSA的步骤分别封装起来,代码可读性会相对更高。第三个可以改进的点,根据最近查资料和对库的进一步学习才得知,语料库是可以实现暂存的。而该实验没有很好地对分词结果进行保存,导致每次实验都要重新进行分词和词性标注,导致实验的时间成本变高。
实验所使用的数据集
LFM_Comparation.rar_LSA和LDA是文本挖掘技术吗-机器学习文档类资源-CSDN下载